AI and ML Refresher
Contents
AI and ML Refresher#
The course has some basic knowledge of machine learning as a prerequisite, but I prefer to start it with a quick introduction of the fundamental concepts so as to verify that we are aligned. In case you don’t know something, you will find references to learn more. Let’s begin!
Machine Learning and Artificial Intelligence#
The terms Machine Learning and Artificial Intelligence are often used interchangeably, but there are differences between the two:
Machine learning is a subset of artificial intelligence that is concerned with giving computers the ability to learn from data.
Artificial Intelligence, on the other hand, is a broader term that covers all aspects of making computers smarter, including machine learning.

Many artificial intelligence systems can be built with or without machine learning. For example:
A chess solver without machine learning would have a list of rules (written by a human expert in chess) that assign scores to specific moves. For example, a move that allows you to eat the opponent’s queen would often have a positive score, as the queen is the most powerful piece in chess. In the end, the move with the highest score would be the move played by the AI system.
A chess solver with machine learning would be trained on a large number of chess matches, automatically learning scores to assign to moves, where a high score means that the move likely contributes to a win. The domain knowledge is extracted by the algorithm from the training data. In the end, the move with the highest score would be the move played by the AI system.
Stockfish and AlphaZero
Stockfish has been one of the best chess engines around for many years, working with “traditional” artificial intelligence methods (no machine learning) and implementing many rules created by human experts.
In 2017, Stockfish was challenged by AlphaZero, a machine learning based chess engine developed by DeepMind entirely trained by self-play: this means that no human expert put his/her knowledge into the program, and the program learned all the knowledge of high-level chess by playing against itself several times.
In 100 games from the normal starting position, AlphaZero won 25 games as White, won 3 as Black, and drew the remaining 72, with 0 losses. In fact, it happens more and more often that AI systems learn more effective rules on their own than those created by human experts, if high-quality data is provided.
Main areas of Machine Learning#
The machine learning field is typically divided into three areas: Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
Supervised Learning#
Supervised Learning is a type of machine learning that leverages a known dataset (i.e. the training set) to train a model which can then make predictions. The training set is a set of data that includes the correct answers (i.e. labels) over which a machine learning model can learn.
Examples of supervised learning problems are:
Classifying images.
Predicting whether or not a person will default on a loan.
Forecasting the price of a stock.
The lifecycle of a supervised learning model is made of two steps: training (i.e. where learning happens) and inference (i.e. where we make predictions on new data).
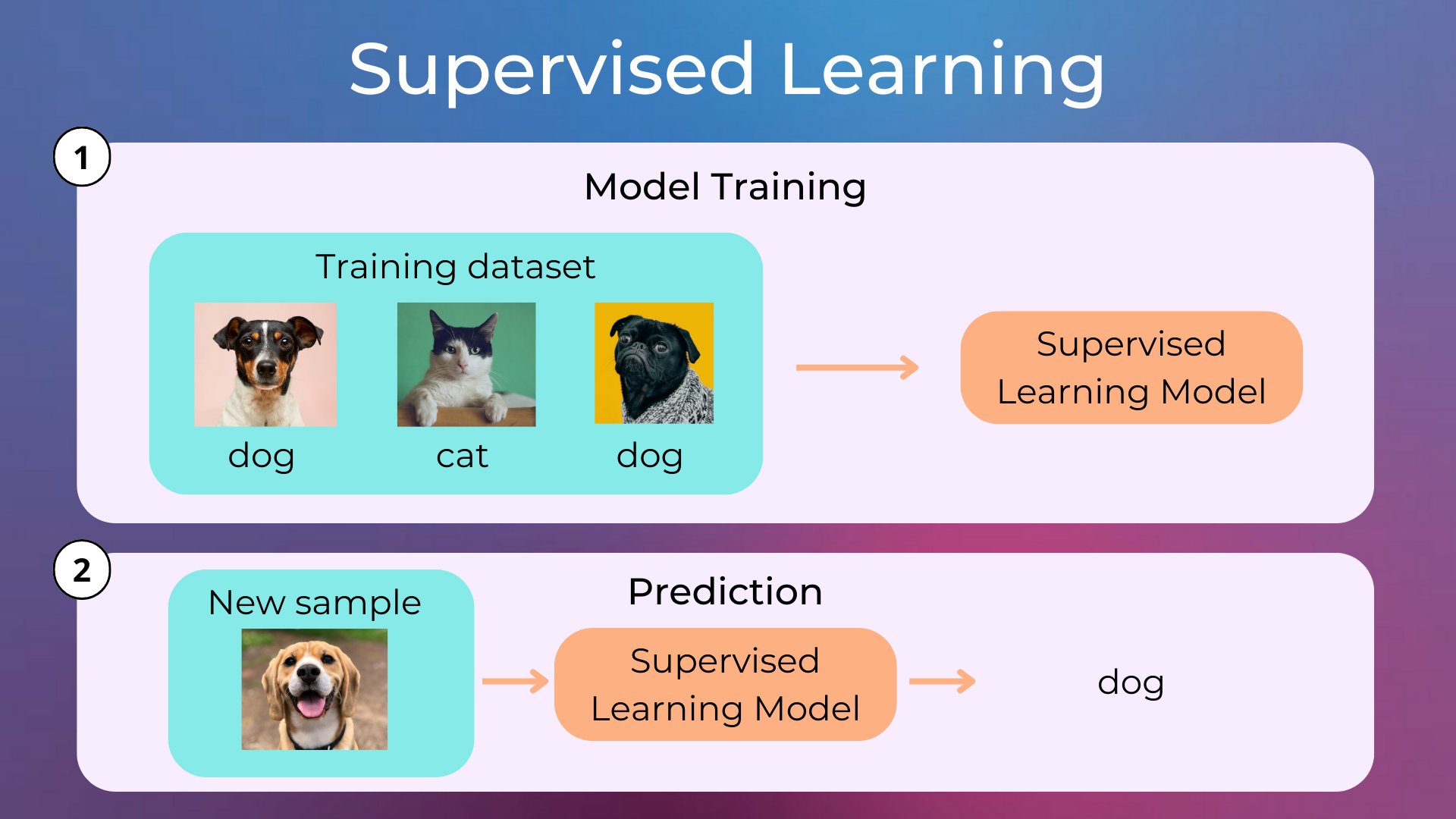
Popular supervised learning algorithms are Linear Regression, Logistic Regression, Decision Trees, Support Vector Machines, K-Nearest Neighbors, Random Forest, XGBoost, and Artificial Neural Networks.
Unsupervised Learning#
Unsupervised Learning is a type of machine learning that looks for patterns in data without being given any labels. This is in contrast to supervised learning, which relies on training data with labels.
Some common unsupervised learning tasks include:
Clustering: A technique that can be used to group data points that are somewhat similar to each other. For example, clustering can be used to group customers who have similar buying habits.
Dimensionality Reduction: A technique that can be used to reduce the number of features in a dataset. This can be useful for visualizing data or for simplifying machine learning models.
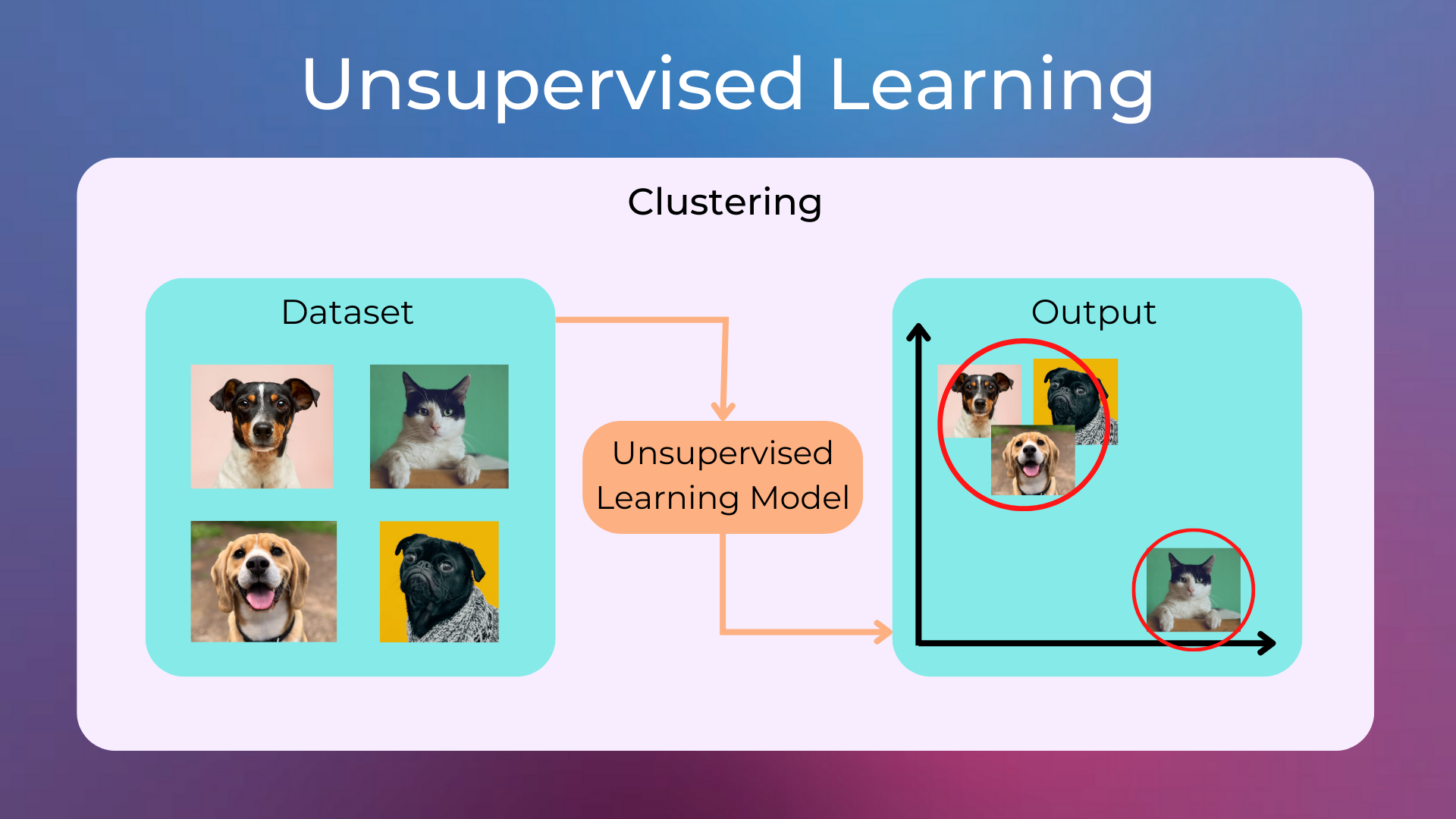
Popular unsupervised learning algorithms are K-means Clustering, HDBSCAN, Spectral Clustering, Principal Component Analysis, and UMAP.
Reinforcement Learning#
Reinforcement Learning is a type of machine learning that allows an agent to learn in an environment by taking actions and receiving rewards.
Example of reinforcement learning problems:
Teaching a robot how to walk: The robot would take actions, such as moving its legs, and receive rewards when specific conditions are met, such as moving forward. Over time, the robot would learn which actions lead to the best rewards and thus learn how to walk.
Learning to play chess (as in AlphaZero).
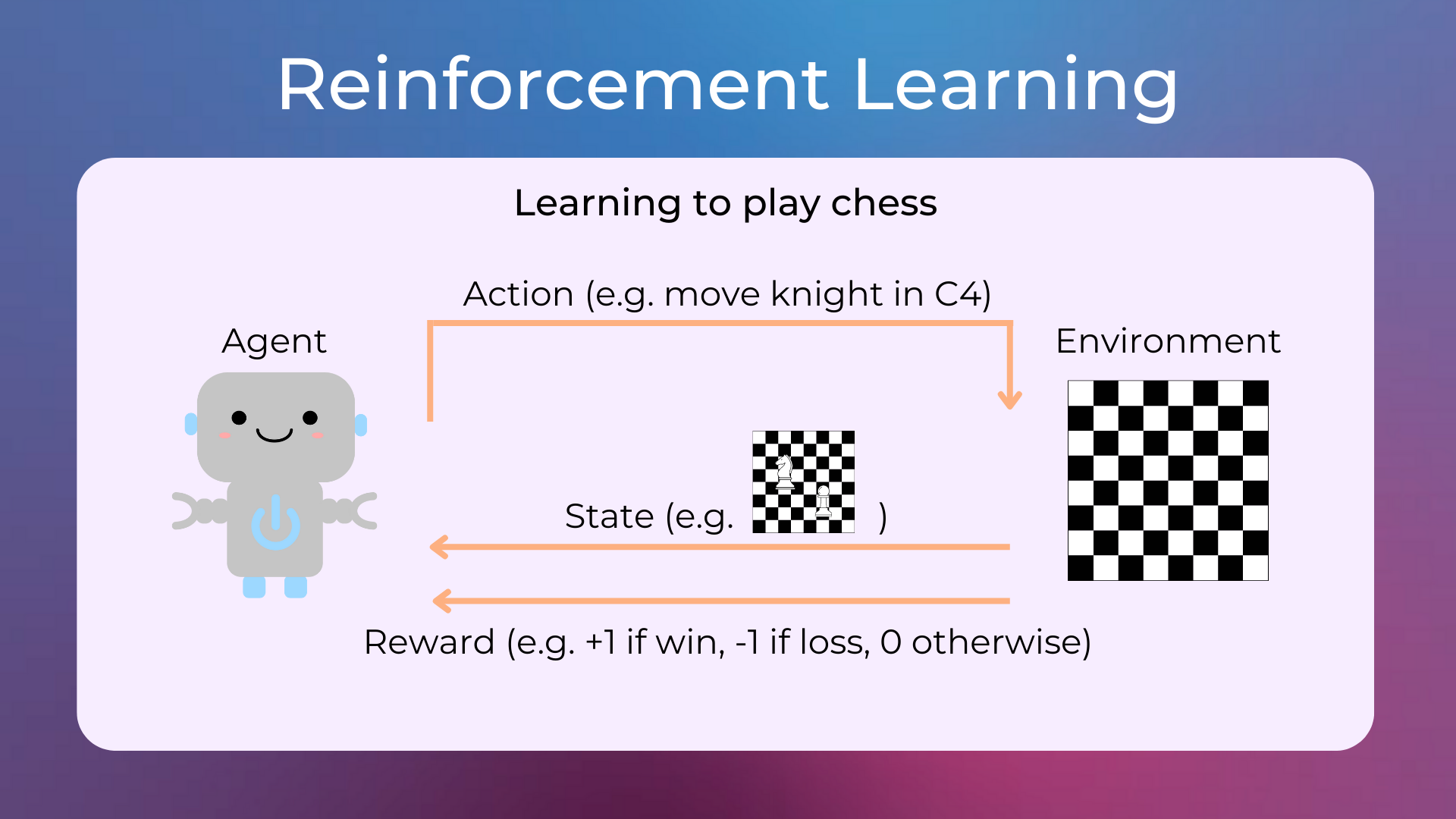
Popular reinforcement learning algorithms are Value Iteration, Policy Iteration, Q-Learning, SARSA, DQN, A2C, and PPO.
Model Training#
Here are some concepts to keep in mind when training machine learning models.
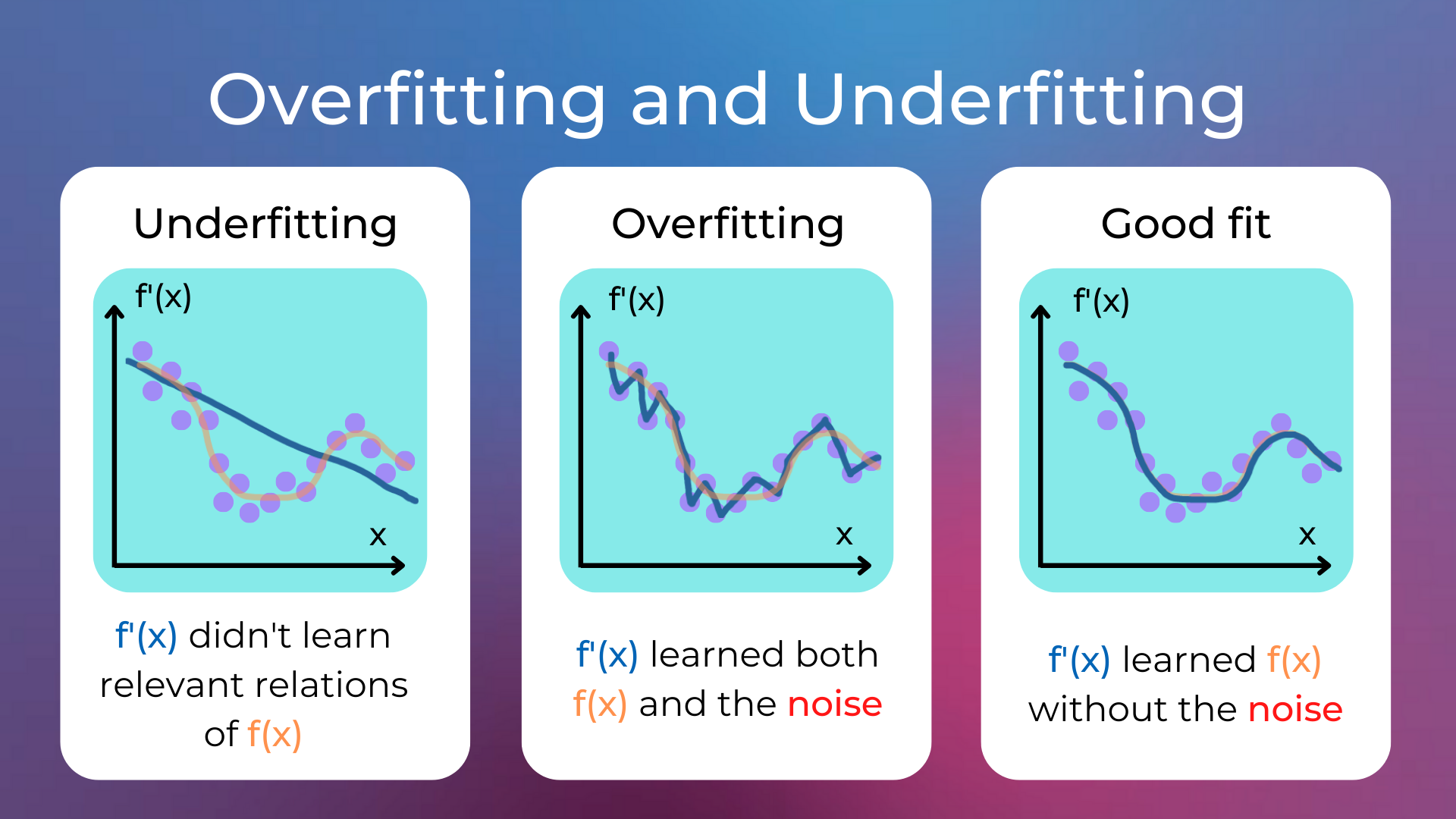
Generalization, Overfitting and Underfitting#
In machine learning, generalization is the ability of a model to accurately predict outcomes for previously unseen data. Indeed, a model is typically trained on a dataset, which is a collection of noisy observations of the function that we want to learn.
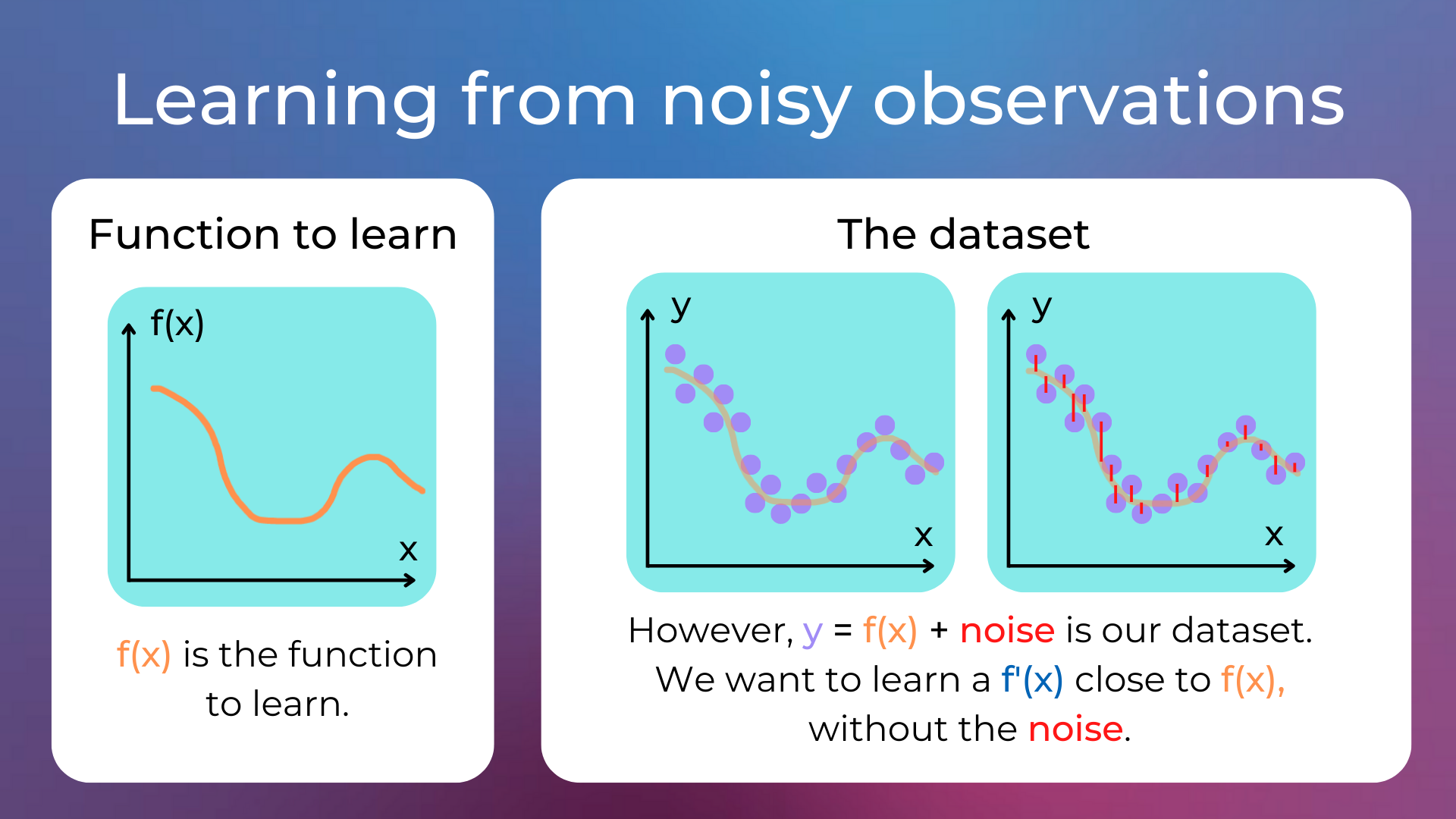
The bias–variance dilemma is the conflict in trying to simultaneously minimize two sources of error that prevent supervised learning algorithms from generalizing beyond their training set:
The bias error is an error from erroneous assumptions in the learning algorithm which leads to missing the relevant relations between features and target outputs (a phenomenon called underfitting).
The variance error is an error from sensitivity to small fluctuations in the training set which may result from an algorithm modeling the random noise in the training data (a phenomenon called overfitting).
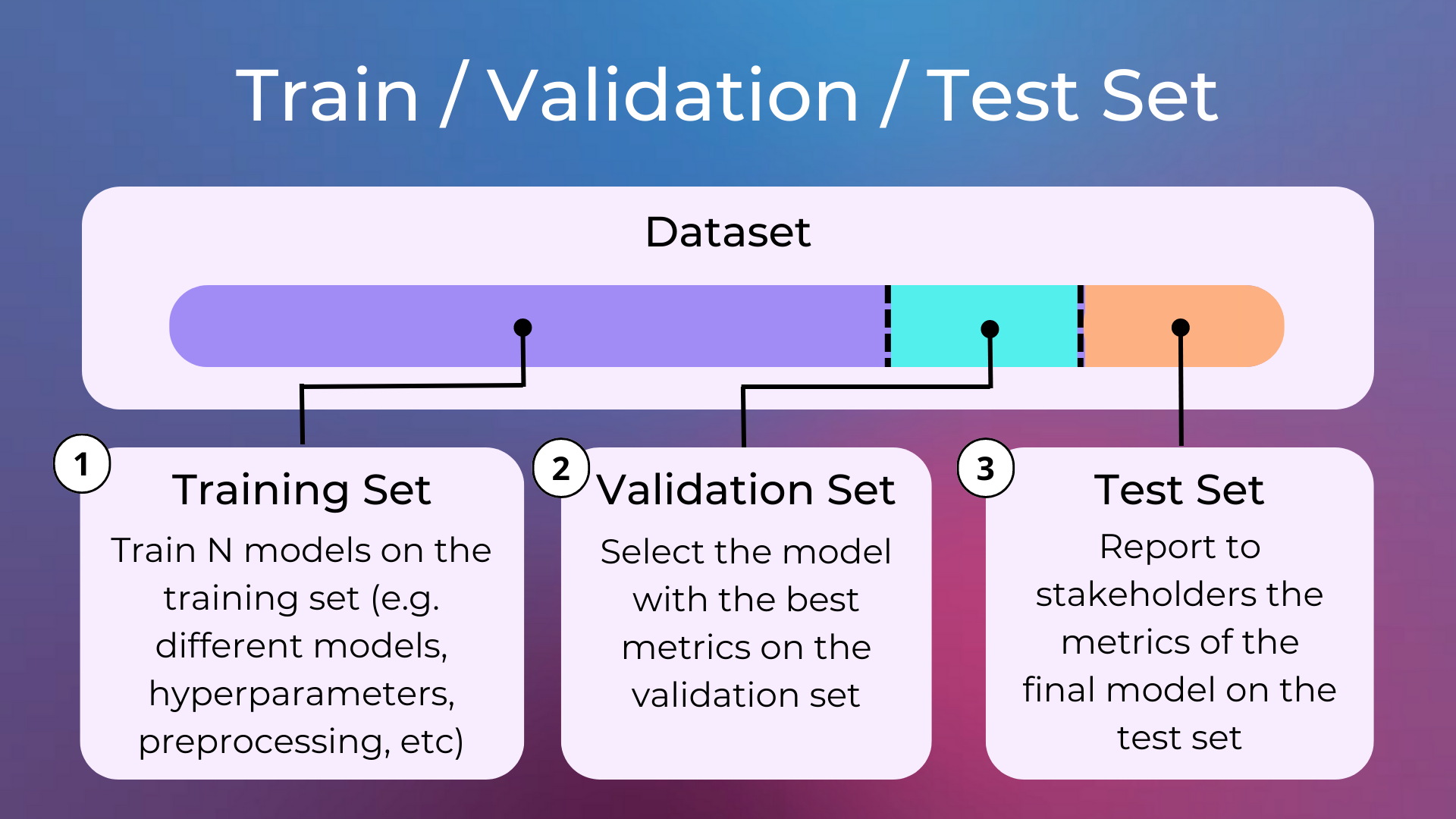
Training set, Validation set, and Test set#
A dataset in a machine learning project is typically split into three parts:
Training Set: The data used when fitting the model.
Validation Set: The data used for hyperparameter tuning, early-stopping to avoid overfitting, or other validation techniques.
Test Set: The data used only after the model has been trained, to compute appropriate metrics that describe the model quality on new unseen data.
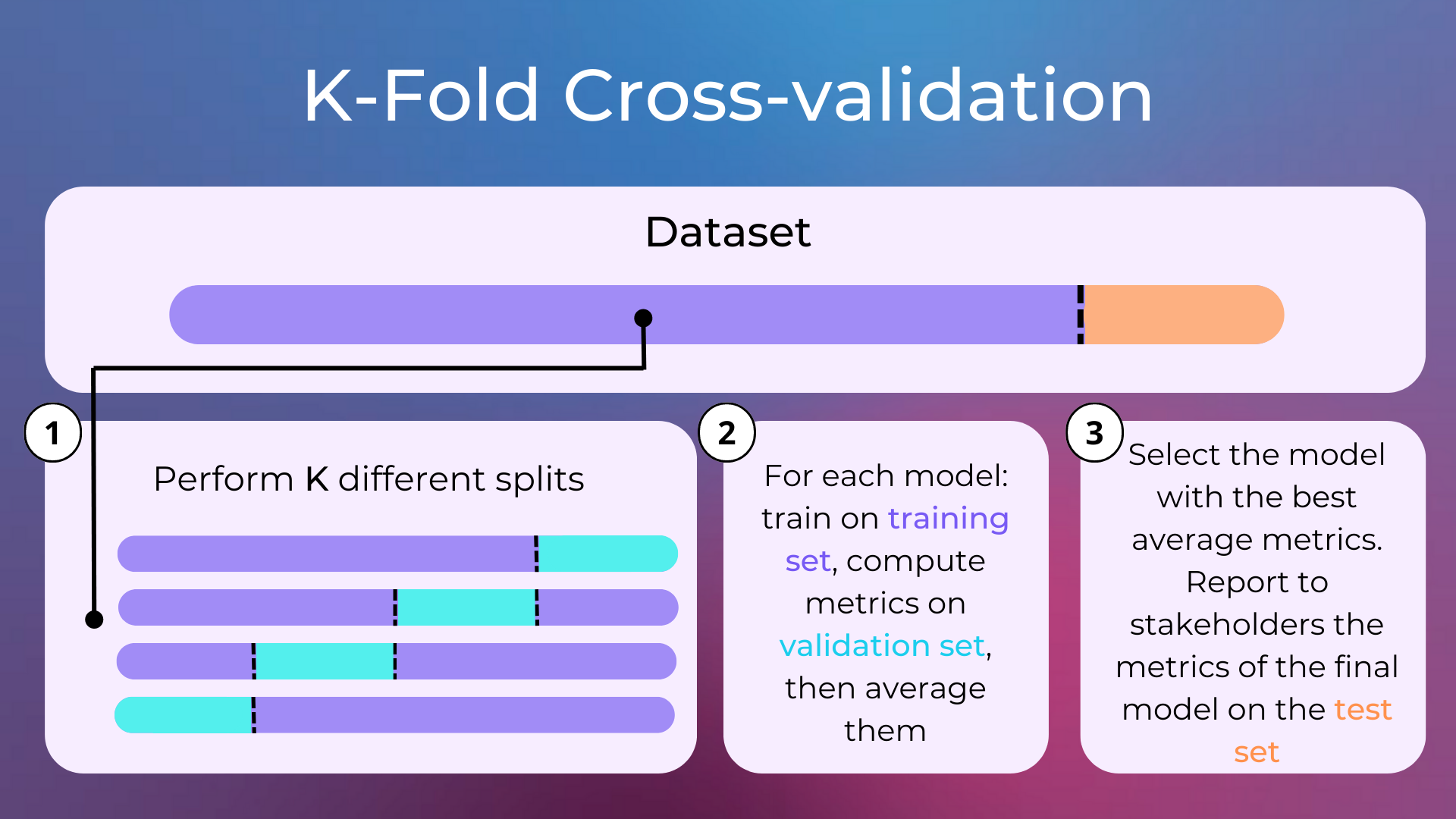
Cross-validation is a model validation technique that consists in splitting the data into training set and validation set several times with different splits, and choosing the model with the best metrics averaged over the different validation sets. Using K-fold cross-validation means that the dataset is split into train set and validation set K times.
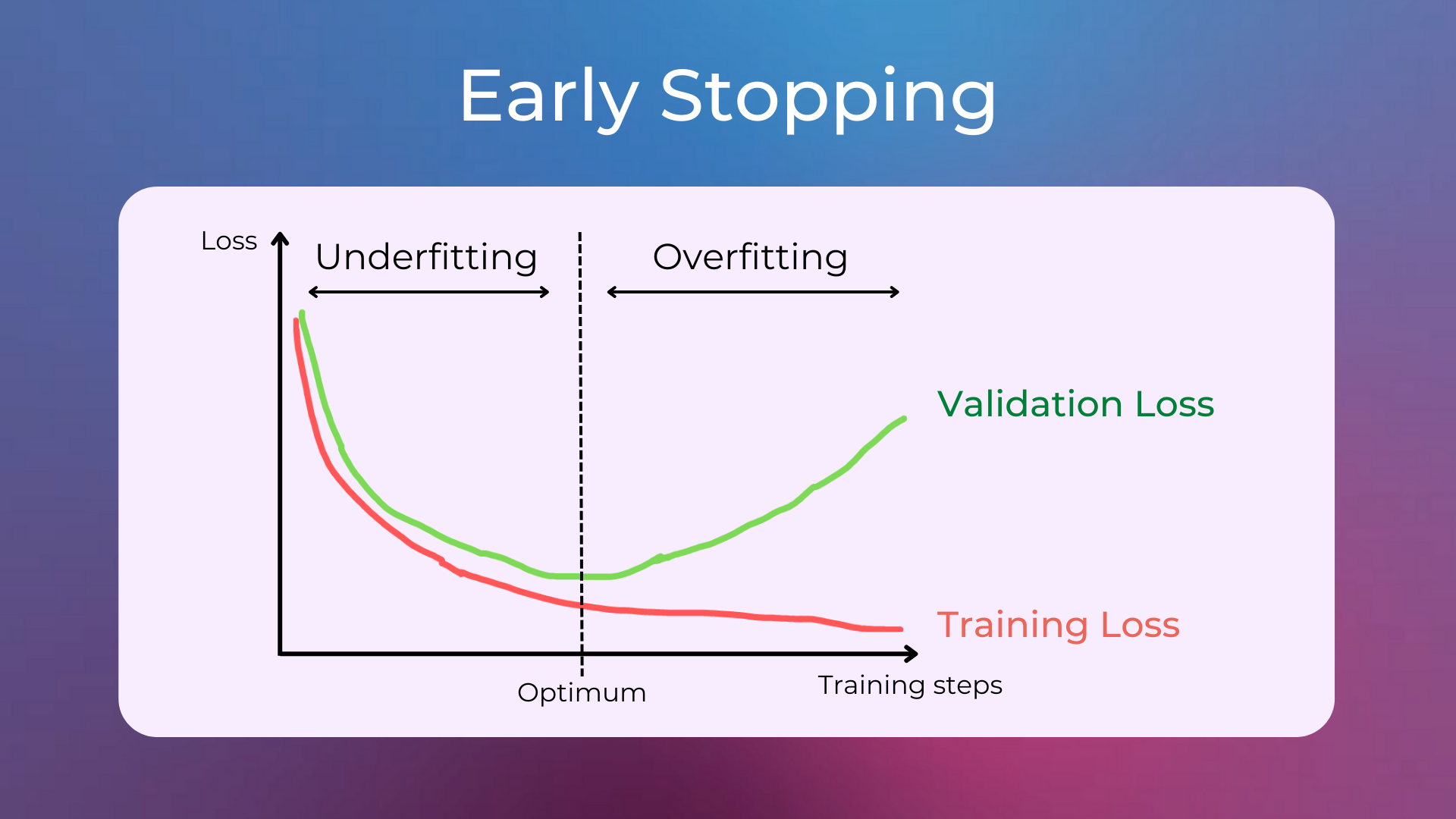
Early stopping is a form of regularization used to avoid overfitting when training a model. It has been observed that, up to a point, the training improves the model performance on data both inside the training set and outside of it (e.g. the validation set). Past that point, however, improving the model on the training data comes at the expense of increased generalization error, which manifests itself as worse performance on the validation set. Therefore, early stopping rules indicate how many iterations of training can be done before the model starts overfitting.
Feature Engineering#
Feature Engineering is the process of using domain knowledge of the data to create features that make machine learning algorithms work better. This is typically done by transforming raw data into features that better represent the underlying problem to the algorithm.
There are many different ways to engineer features, and the approach you take will depend on the data and the problem you’re trying to solve. Some common methods include:
Binning: Grouping data into buckets. For example, you could bin age data into groups such as 0-10, 11-20, 21-30, etc.
Normalization: Scaling data to be between 0 and 1 (as neural networks usually work better with normalized data).
One-hot encoding: Converting categorical data into multiple binary columns.
One of the reasons why Deep Neural Networks tend to perform very well when trained on a large amount of data is their ability to automatically learn low-level and high-level features in the hidden layers.
Hyperparameter Tuning#
Hyperparameter Tuning is the problem of finding a set of optimal hyperparameters (i.e. parameters used to control the learning process) for a learning algorithm. By contrast, the values of other parameters (e.g. the weights in neural networks) are learned.
Examples of hyperparameters for different models are:
Decision Trees: the maximum depth of the tree, the maximum number of leaves, and the criterion used for deciding the splits.
Random Forest: the number of trees.
Neural Network: the number of hidden layers, the number of neurons in each hidden layer.
Loss Functions and Metrics#
A loss function is a function that an optimization algorithm tries to minimize during training. For example, a neural network for a classification problem may be trained with the backpropagation algorithm to minimize the cross-entropy loss function.
An ideal loss function can be easily minimized by the learning algorithm. For example, if the learning algorithm is backpropagation, then an ideal loss function would be differentiable (as backpropagation works with derivatives), smooth, and convex (so that there aren’t suboptimal minima where the learning algorithm can get stuck).
Metrics are only used to evaluate how well a model performs and they are typically computed on the test set. Metrics should be easily interpretable, as they are used to convey the performance of the model to stakeholders. They are not used by the learning algorithm, so it doesn’t matter if they are differentiable or not.
Some common metrics for classification models are accuracy, precision, recall, and the F1-score (i.e. the harmonic mean of precision and recall). Another common metric is the area under the receiver operating characteristic curve (AUC), which measures the ability of the model to discriminate between positive and negative cases.
Some common metrics for regression models are the Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE).
Deep Learning#
Deep Learning is a subset of machine learning that uses deep neural networks to learn from data.

Deep neural networks are networks with multiple layers of neurons, as opposed to neural networks with few layers, which are referred to as shallow neural networks.
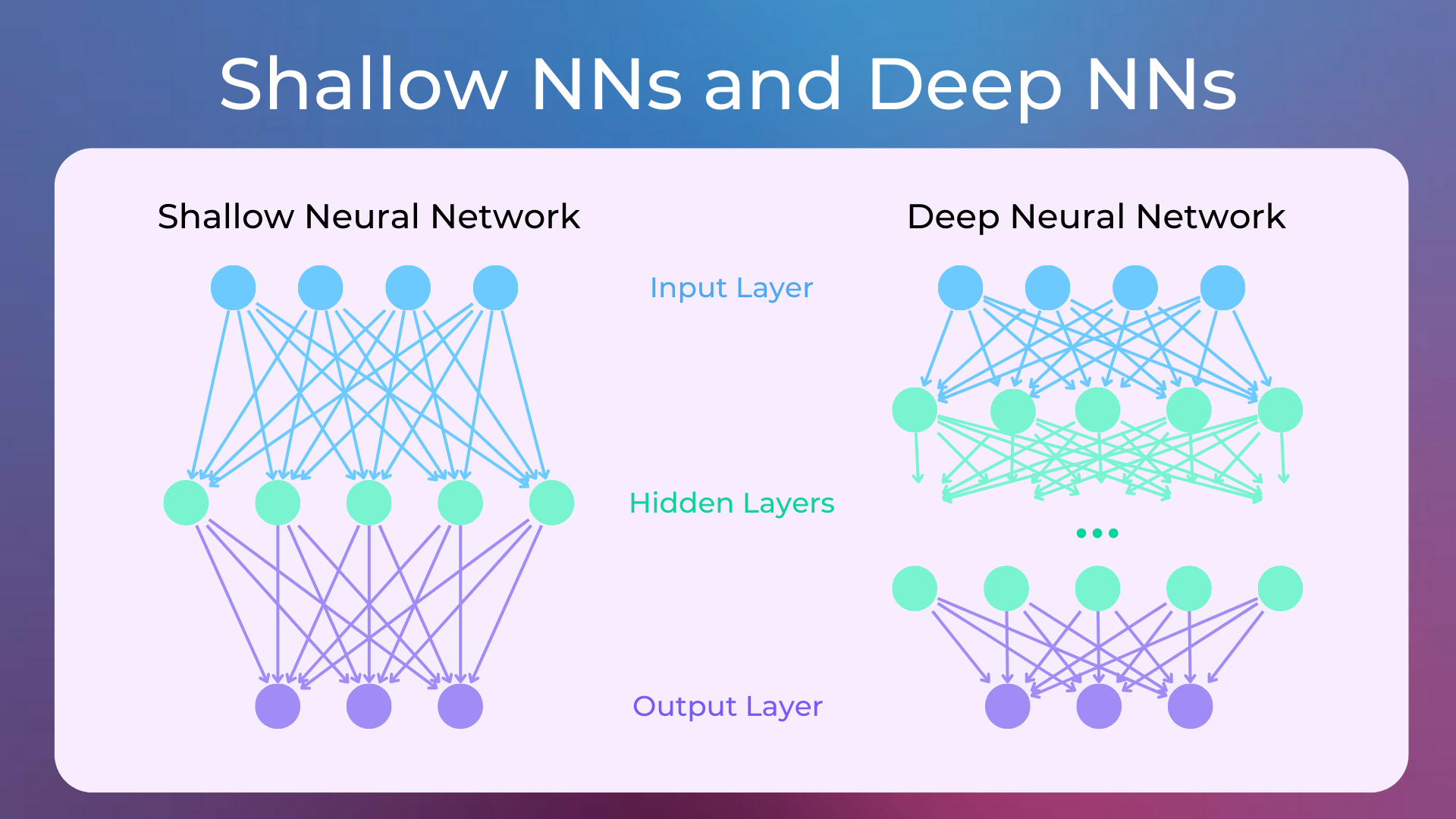
Deep Neural Networks perform very well when trained on a large amount of data, as they are able to learn low-level and high-level features in the hidden layers (a.k.a. feature learning).
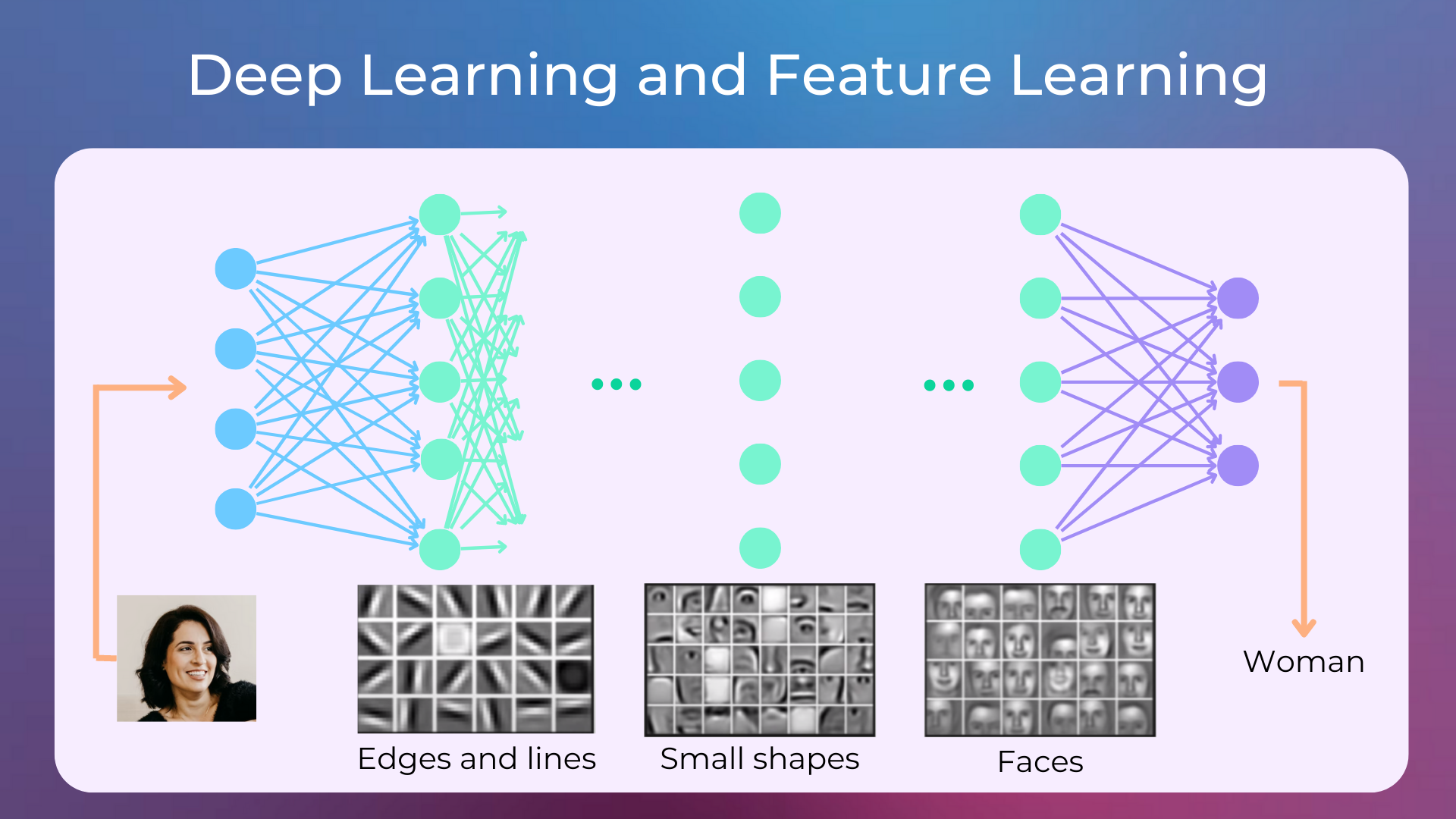
Fig. 1 Feature representations are from https://developer.nvidia.com/blog/deep-learning-nutshell-core-concepts/#
Deep learning is commonly inspired by the brain’s neural networks, even though they are different in many aspects.
Popular types of deep neural networks are Feedforward Neural Networks (FNNs), Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Transformers.
Neural networks are trained using a process called backpropagation. This process involves computing the gradient of the loss function with respect to the weights of the connections between the neurons.
Quiz#
Choose the correct option
Artificial Intelligence is a subset of Machine Learning.
Machine Learning is a subset of Artificial Intelligence.
Answer
The correct answer is 2.
Which one of the following is not one of the three main areas of machine learning?
Reinforcement Learning
Unsupervised Learning
Supervised Learning
Decision Trees
Answer
The correct answer is 4.
Choose the list of algorithms commonly used in supervised learning.
Linear Regression, Decision Trees, Support Vector Machines.
K-means Clustering, HDBSCAN, UMAP.
PPO, SARSA, A2C.
Answer
The correct answer is 1.
Choose the list of algorithms commonly used in unsupervised learning.
Q-Learning and Value Iteration.
Logistic Regression and K-nearest Neighbors.
Principal Component Analysis and K-means Clustering.
Answer
The correct answer is 3.
Choose the list of algorithms commonly used in reinforcement learning.
SARSA and Policy Iteration.
XGBoost and Random Forest.
HDBSCAN and Spectral Clustering.
Answer
The correct answer is 1.
Assign the numbers in the image with the correct options.
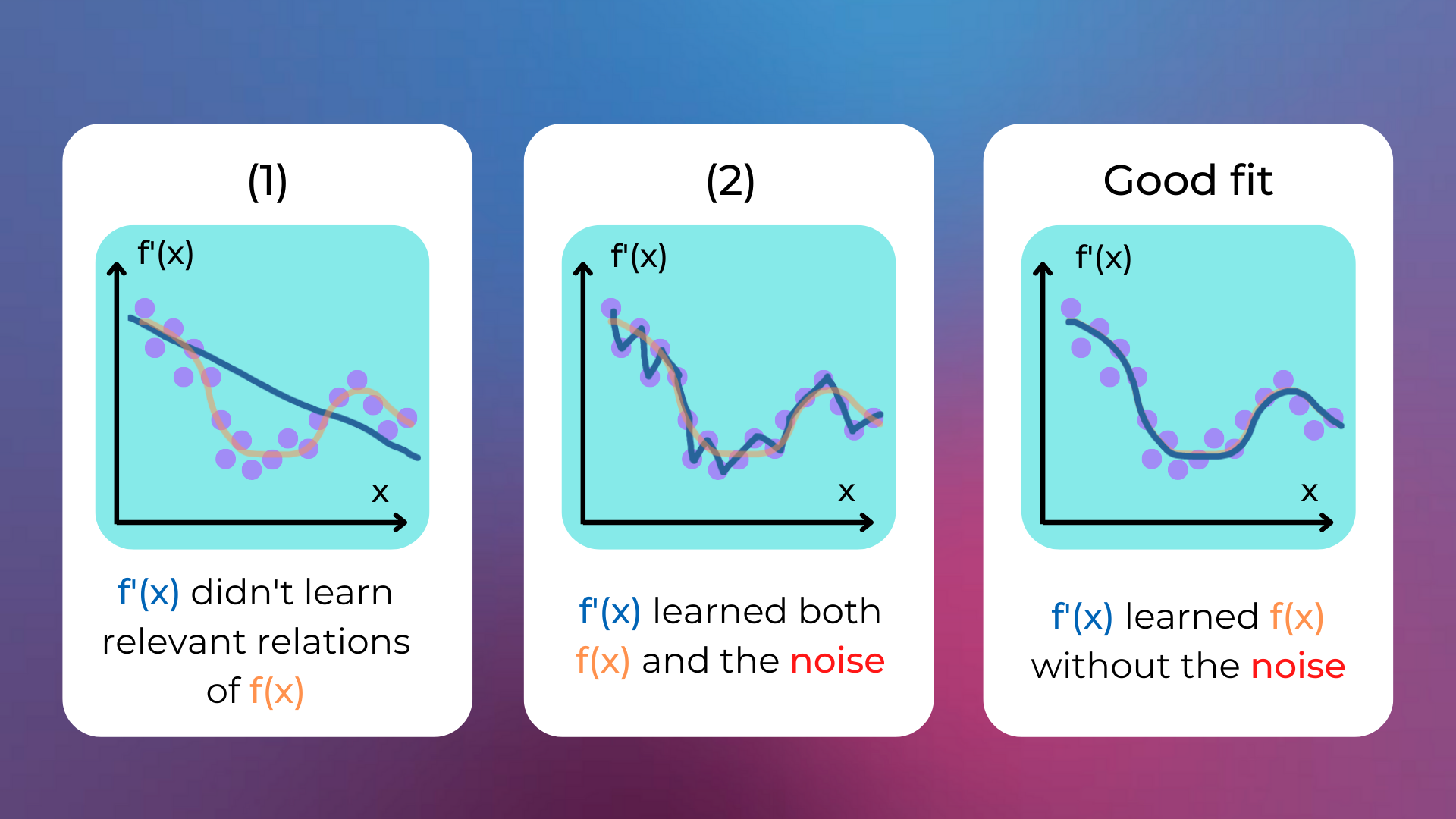
(1)Underfitting,(2)Overfitting.(1)Generalization,(2)Overfitting.(1)Overfitting,(2)Underfitting.(1)Generalization,(2)Underfitting.
Answer
The correct answer is 1.
Assign the numbers in the image with the correct options.
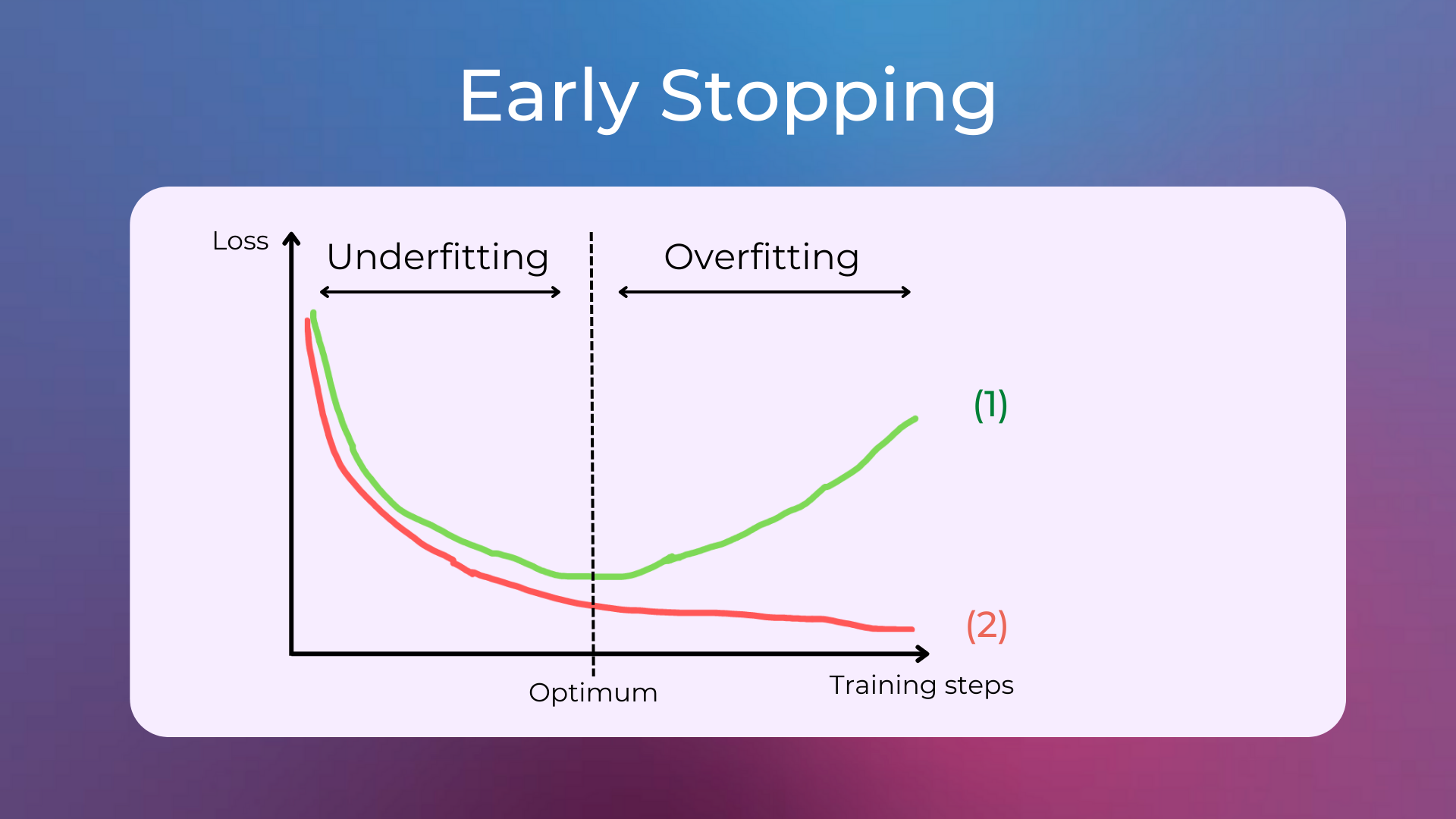
(1)Training Loss,(2)Validation Loss.(1)Test Loss,(2)Training Loss.(1)Validation Loss,(2)Test Loss.(1)Validation Loss,(2)Training Loss.
Answer
The correct answer is 4.
What is feature engineering?
It’s the problem of finding a set of optimal hyperparameters (i.e. parameters used to control the learning process) for a learning algorithm.
It’s the process of grouping data into buckets.
It’s the process of using domain knowledge of the data to create features that make machine learning algorithms work better.
Answer
The correct answer is 3.
Which of the following best describes Deep Learning?
Deep Neural Networks doing feature learning thanks to training on a large amount of data.
Shallow Neural Networks doing feature learning thanks to training on a large amount of data.
Deep Neural Networks doing parameter tuning thanks to training on a large amount of data.
Answer
The correct answer is 1.
What is the name of the algorithm commonly used to train Artificial Neural Networks in machine learning?
Evolutionary Programming.
Backpropagation.
Entropy Loss Optimization.
Answer
The correct answer is 2.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.