2.2 Hugging Face Hub: Models and Model Cards
Contents
2.2 Hugging Face Hub: Models and Model Cards#
Let’s now dive into more details about what we can find in the Hugging Face Hub, learning about model cards.
Model Cards#
Let’s look for something specific, e.g. pre-trained sentiment analysis models finetuned for tweets. If we use “sentiment twitter” as query on the Hub search engine, we’ll find more or less the following models.
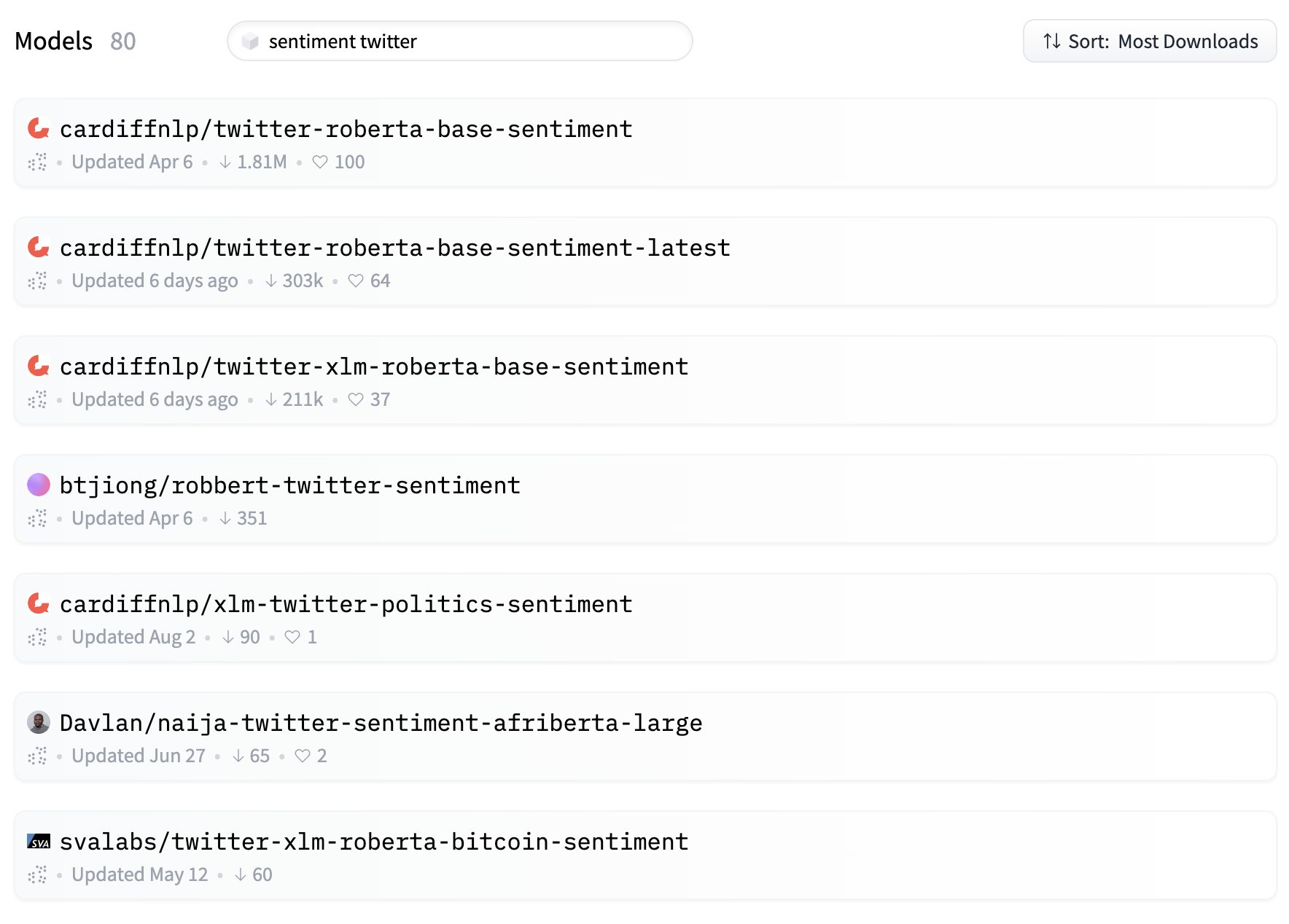
Let’s open the page of the cardiffnlp/twitter-roberta-base-sentiment model, developed by the Natural Language Processing team at Cardiff University. You’ll see the following page.
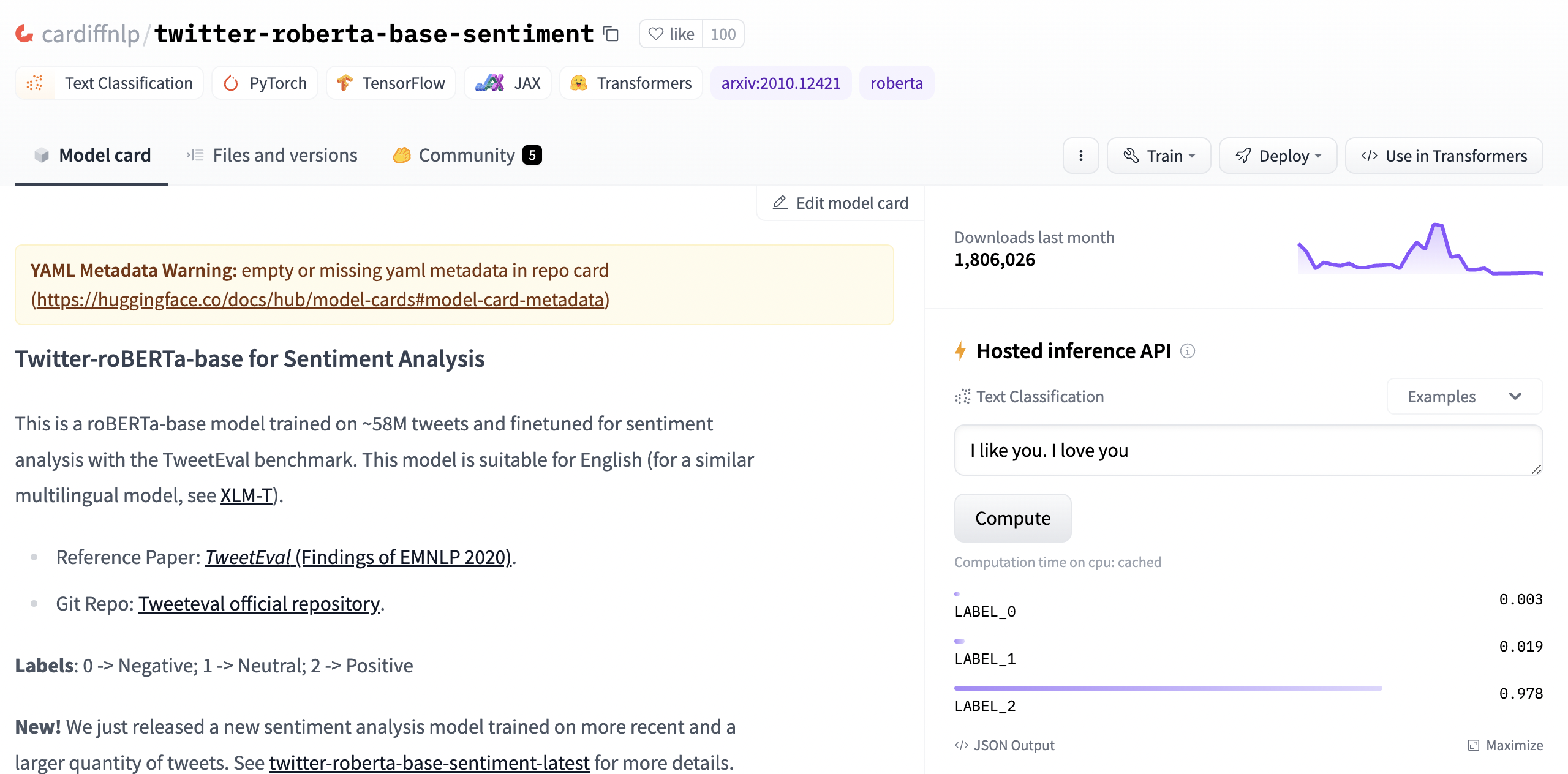
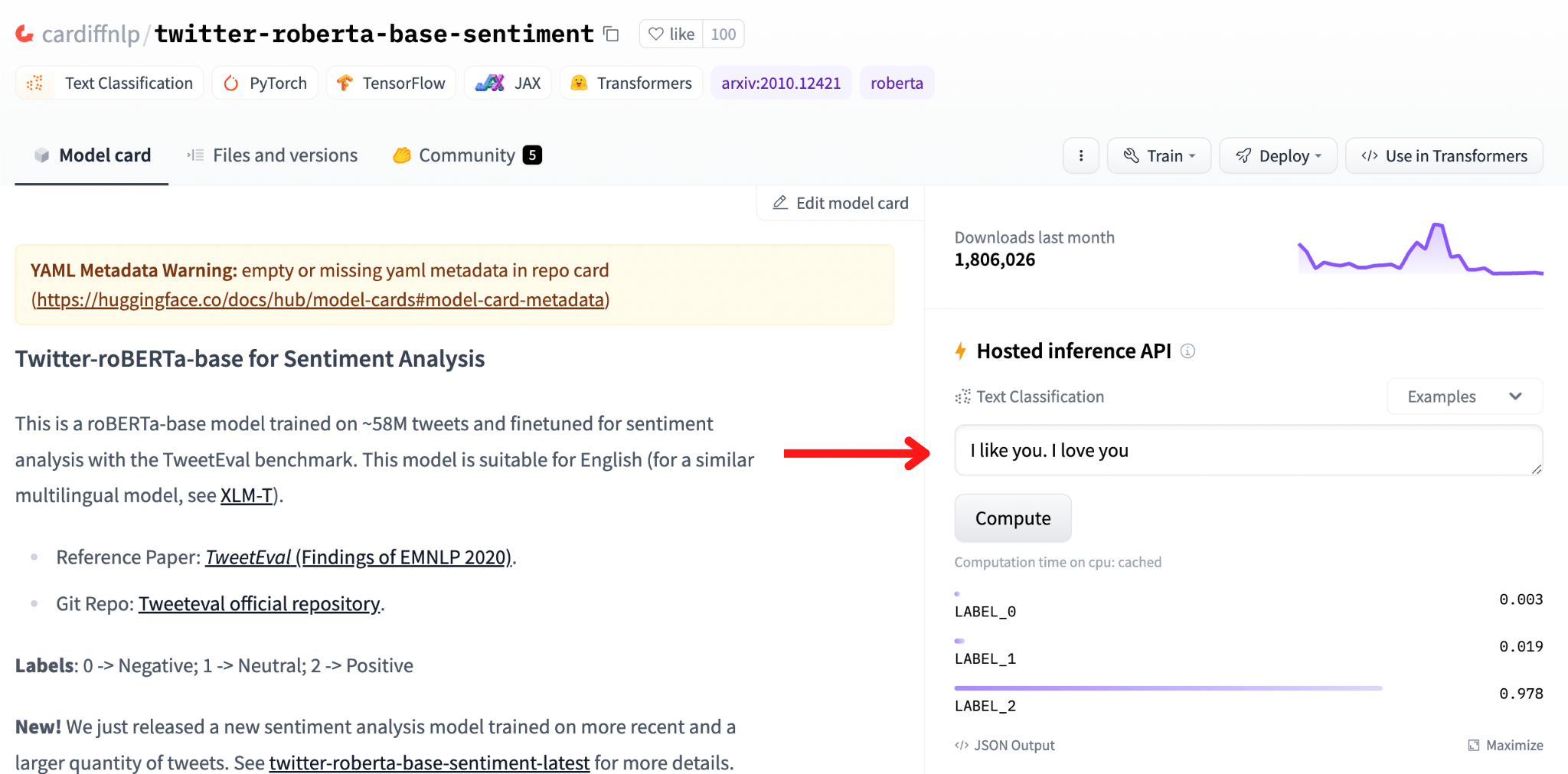
There is a lot of info! Let’s look specifically for the model card.
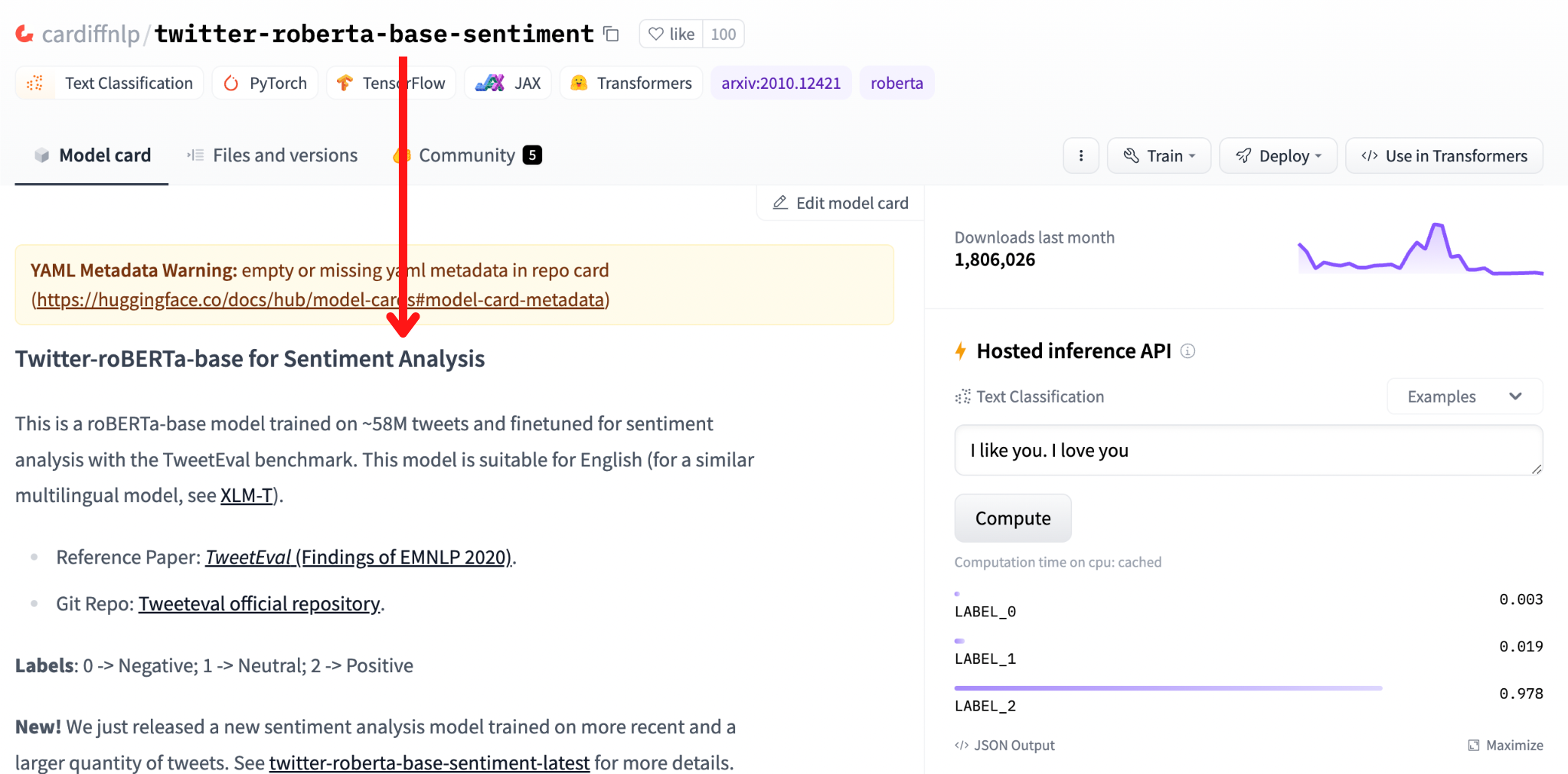
The section indicated by the arrow is the model card of the cardiffnlp/twitter-roberta-base-sentiment model. A model card is basically a collection of important information about a model, often containing:
The model architecture (e.g. BERT, RoBERTa, etc).
The training configuration and experimental info.
Training datasets.
The evaluation results.
Its intended uses and potential limitations, including biases and ethical considerations.
Usually, in the model card you’ll also find a code example of how to use the model. Model cards are great because they provide a simple and standardized overview of a specific model!
Model Tags/Filters#
On top of the model page you can find several tags or badges.
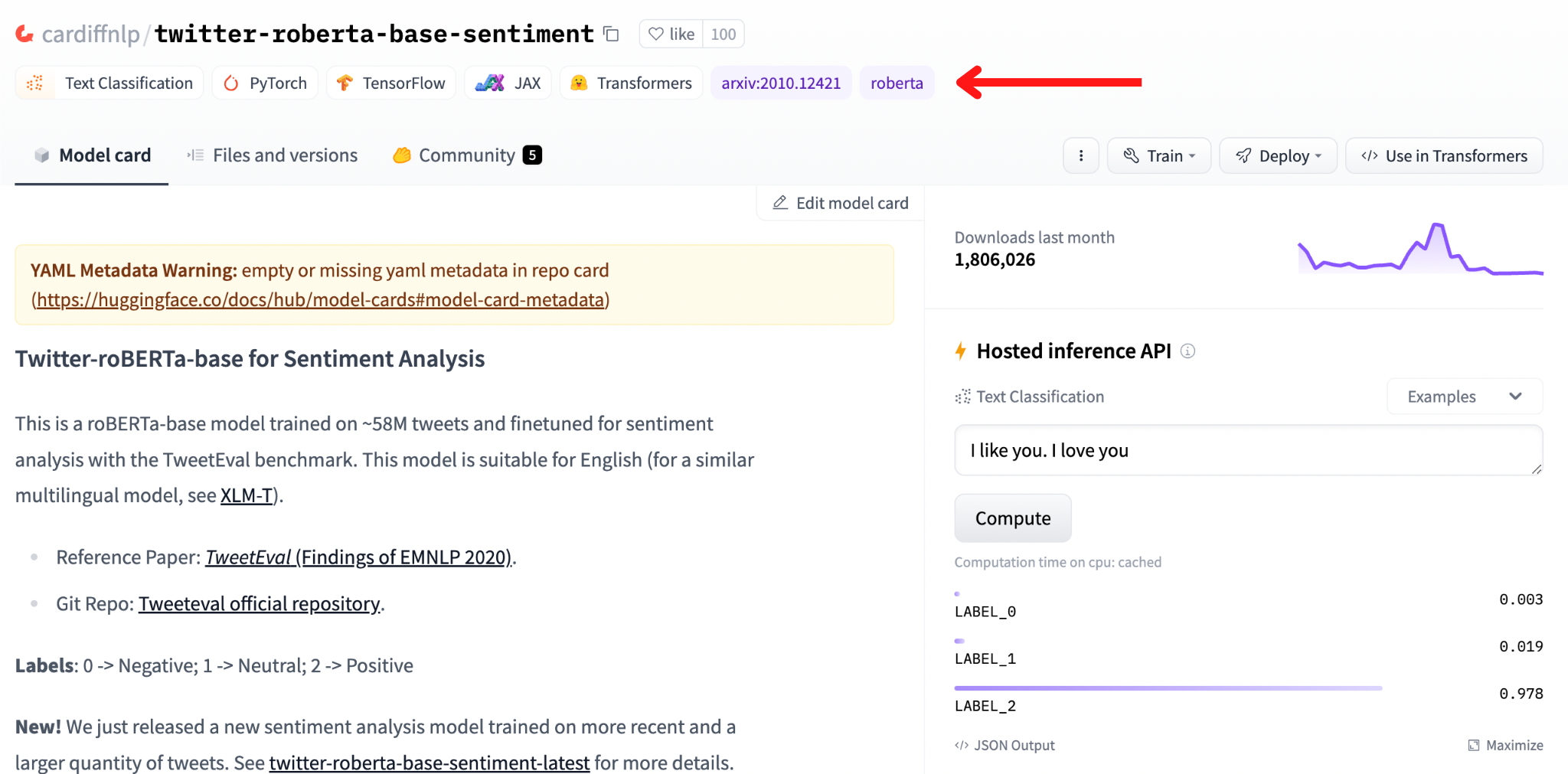
They are divided into:
Task: The ML task the model can perform (e.g. Text Classification, which is a more generic class for sentiment analysis).
Library: The libraries that can be used to load the model, such as TensorFlow, PyTorch, and JAX.
Dataset: The dataset used to train and/or evaluate the model. This information can often be found also in the model card.
Language: The language of the training dataset, and so the language of the inference data to be used with the model. Some models may be multilingual. This information can often be found also in the model card.
License: A license that specifies how the model can be used. This information can often be found also in the model card.
All these tags can also be used as filters on the Hub search engine.
Keep in mind that not all the models on the Hugging Face Hub can be used commercially, so always give a look at the licenses. Here’s a list of several licenses that you may find in the Hub.
Model Repository#
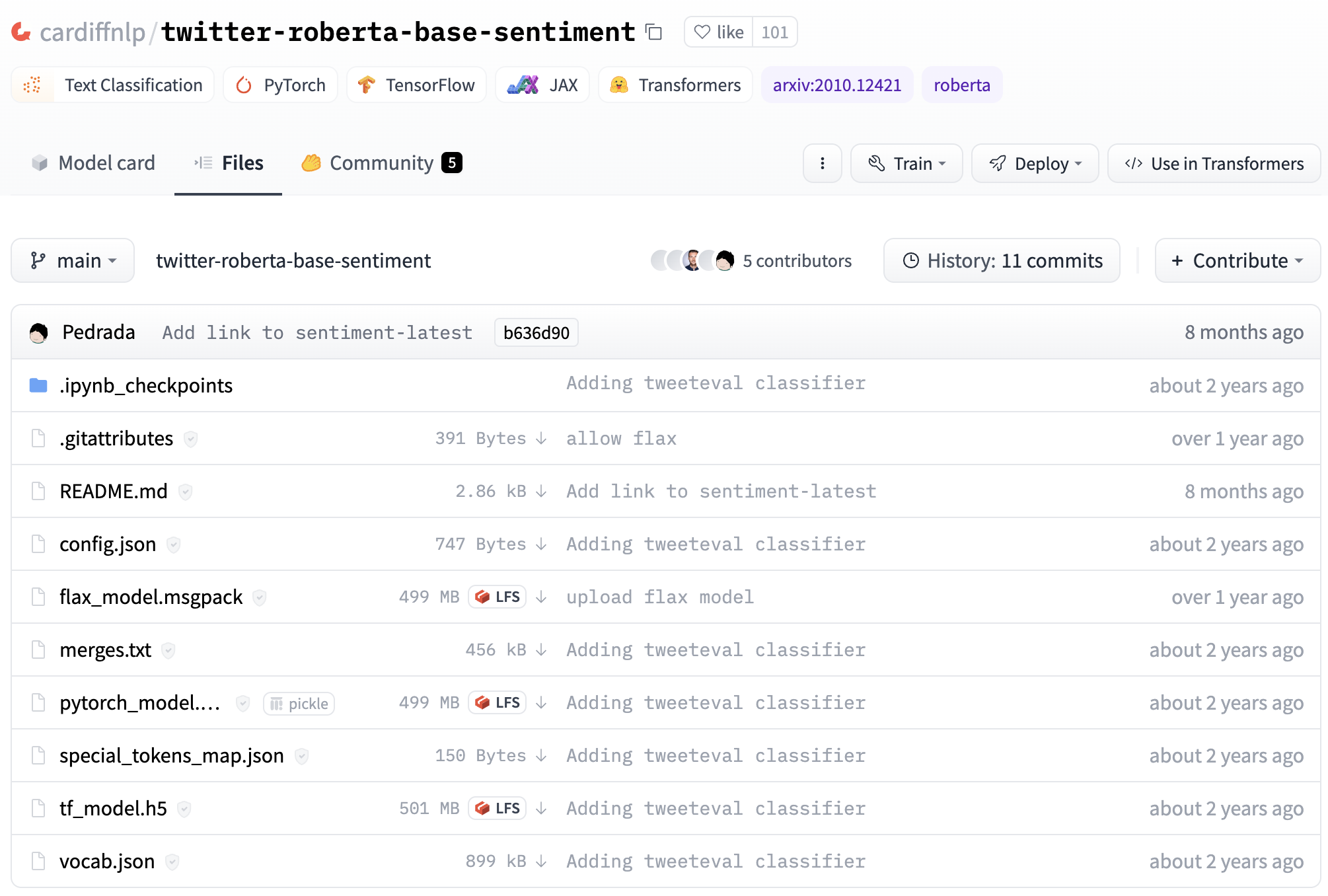
All the info we saw on the model page is generated from a Git repository hosted on Hugging Face on the cardiffnlp account. To see the repository, click on the “Files and versions” tab.
You’ll see the following repository. The model is saved in the pytorch_model.bin, tf_model.h5, and flax_model.msgpack files for each framework respectively. The model card is generated from the README.md file.
Model Discussions and Pull Requests from the Community#
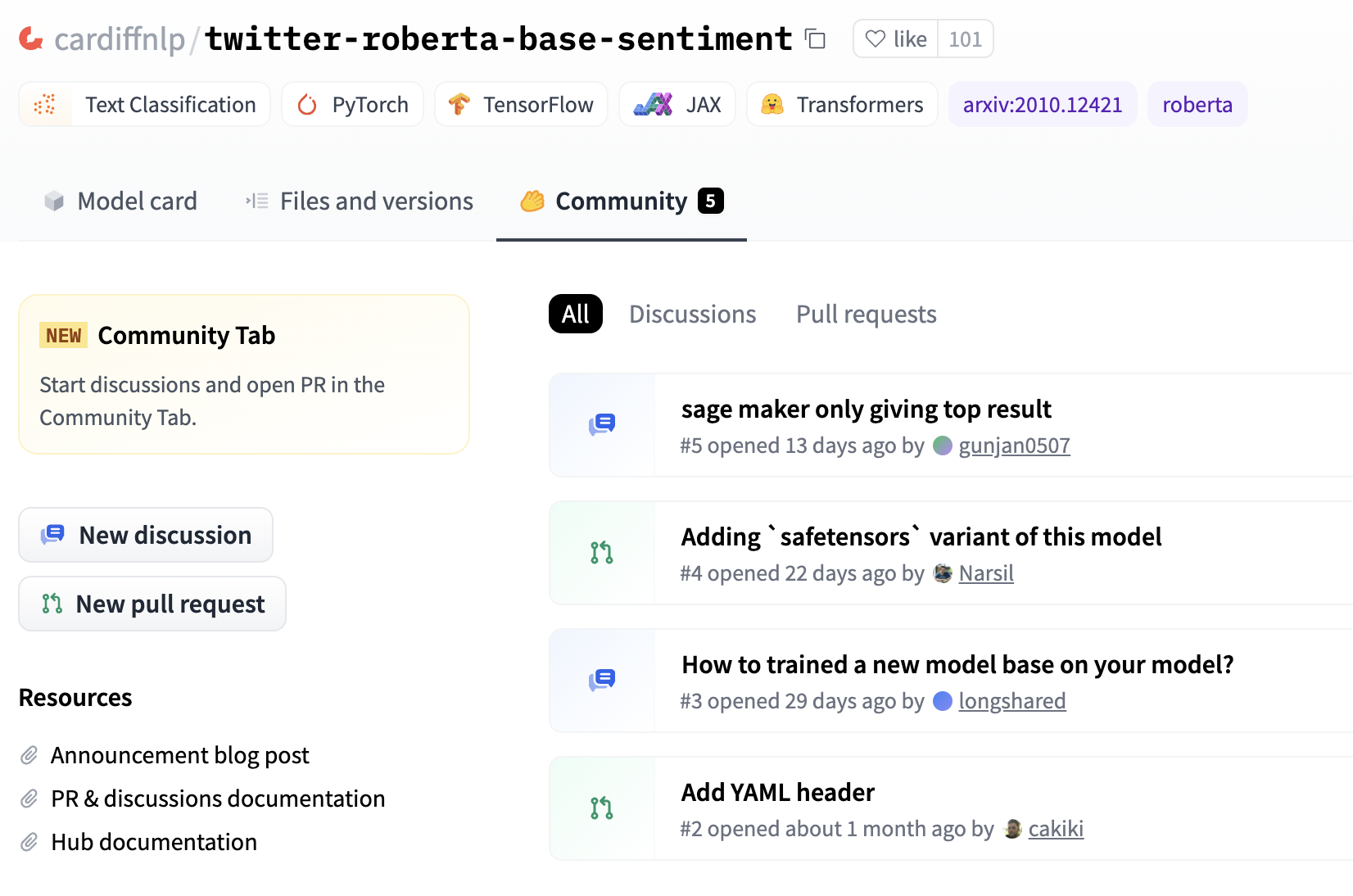
Similar to GitHub, you can find discussions and pull requests about a model by clicking on the “Community” tab.
Here are some discussions and pull requests for the cardiffnlp/twitter-roberta-base-sentiment model.
Model Hosted Inference API#
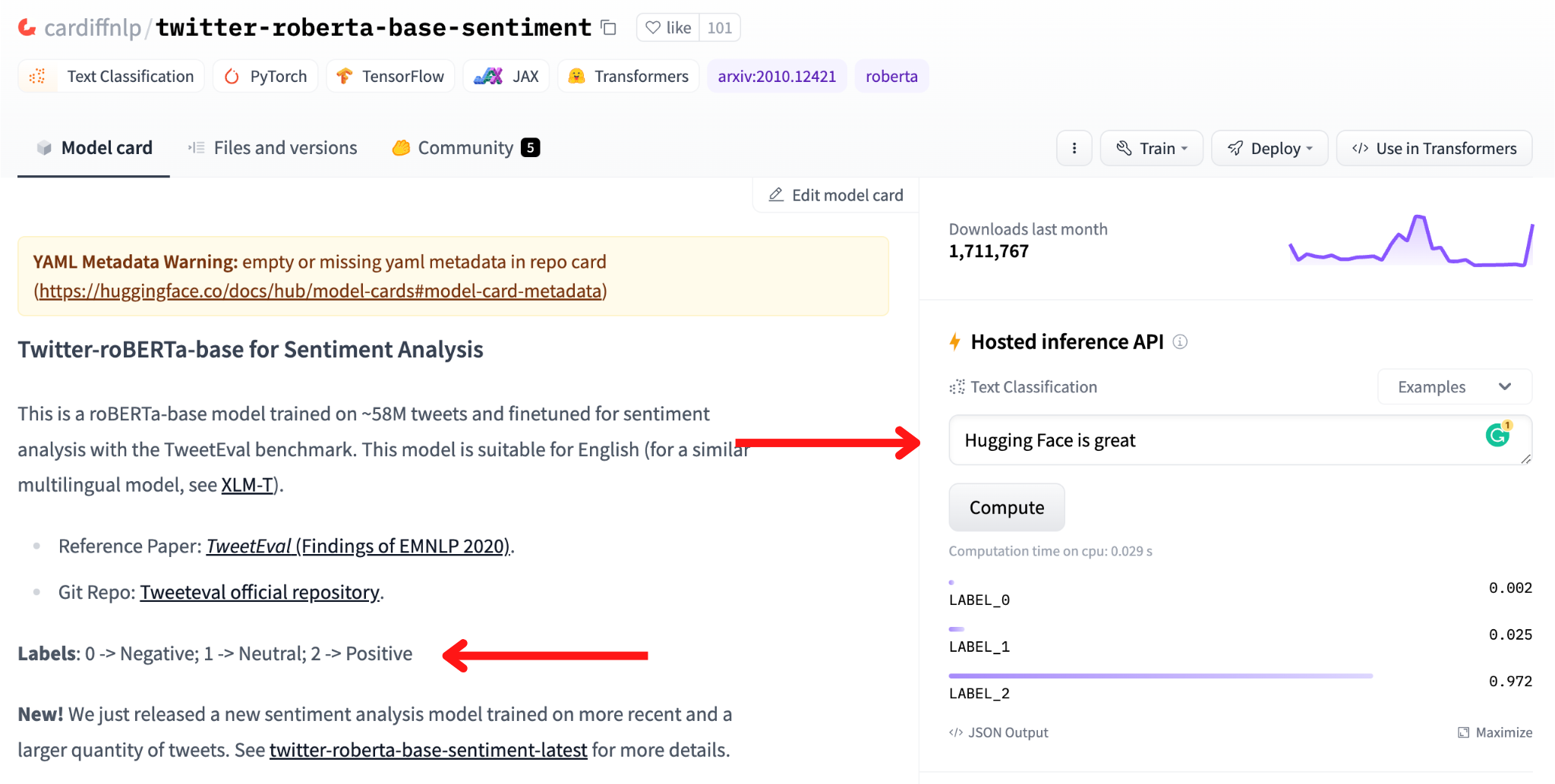
You can try the model directly from the browser using the model Hosted Inference API.
Let’s test the model with the sentence “Hugging Face is great”. The results show that LABEL_2 is the label with the highest score (0.978), and the model card explains that LABEL_2 is the positive label.
The Hosted Inference API is great for quickly testing thousands of models for free. You can also use the Inference Endpoints service to privately host your models on Hugging Face and use them, leveraging a dedicated and autoscaling infrastructure managed by Hugging Face.
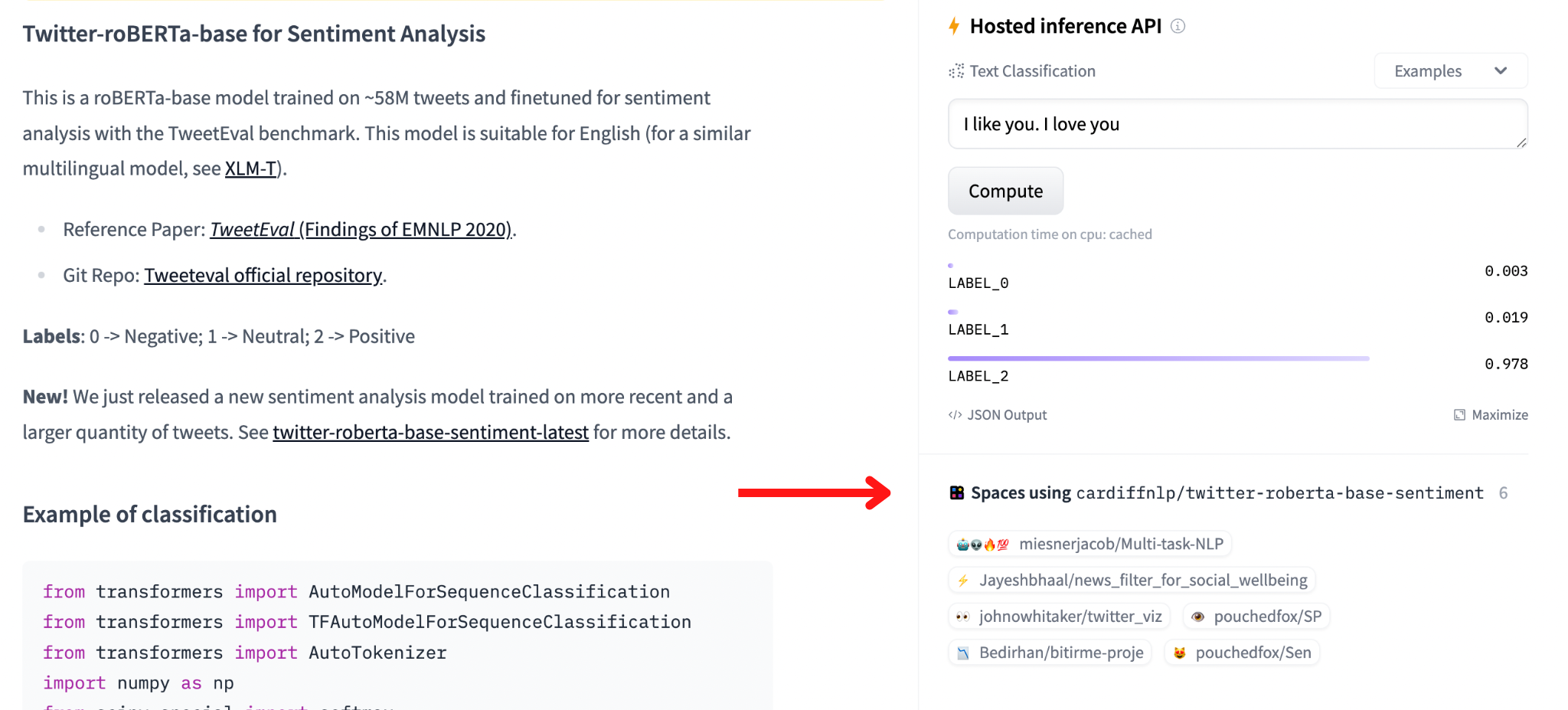
Spaces Linked to the Model#
Last, under the Hosted Inference API section, you should see a list of Hugging Face Spaces that use the cardiffnlp/twitter-roberta-base-sentiment model.
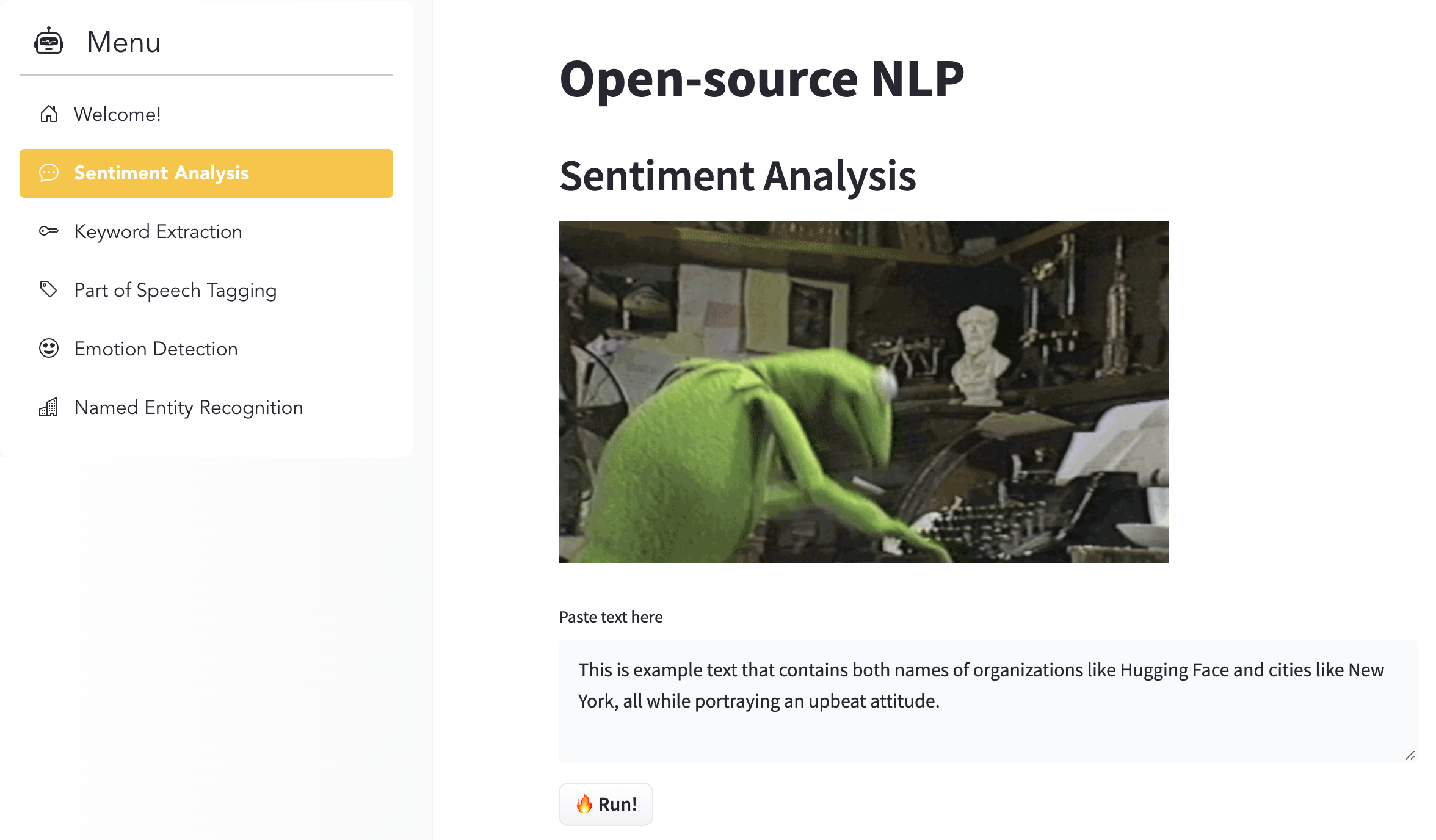
For example, open the miesnerjacob/Multi-task-NLP space and you should see a ML demo of several open models.
Hugging Face Spaces and Arxiv
Lately, Hugging Face annouced that Spaces are now integrated with Arxiv, which means that you’ll find model demos directly under their Arxiv pages. For example, open the Arxiv page of BERT and look under the “Demos” tab.
Quiz#
Select the option that describes something not typically found on a model card.
The evaluation results.
The model intended uses and potential limitations, including biases and ethical considerations.
Training datasets.
The model price.
The model architecture (e.g. BERT, RoBERTa, etc).
The training configuration and experimental info.
Answer
The correct answer is 4.
True or False. All the models in the Hugging Face Hub can be used commercially.
Answer
The correct answer is False. Whether a model can be used commercially or not is specified in the model license.
True or False. If you have a question about a model on the Hugging Face Hub, you should send a message to its author.
Answer
The correct answer is False. While you may be able to send a message to the author, the best way to proceed is to ask the question in the Community section.
True or False. On the Hugging Face Hub you can often test models directly from the browser.
Answer
The correct answer is True, thanks to the Hosted Inference API. Keep in mind that you have a limited amount of calls that you can make daily for free. Moreover, some models can’t be tested directly from the browser if they require complex input (e.g. Reinforcement Learning models).
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.