1.14 Project: Classify Medium Articles with Embeddings
Contents
1.14 Project: Classify Medium Articles with Embeddings#
Last, let’s upgrade our text classification model as well by leveraging sentence embeddings. The scope of the project is to build a text classification model (a simple logistic regression) leveraging sentence embeddings, capable of distinguishing whether a text is about data science or not.
Install and Import Libraries#
Let’s install and import the necessary libraries.
!pip install datasets sentence-transformers
from huggingface_hub import hf_hub_download
import pandas as pd
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import (classification_report, confusion_matrix,
ConfusionMatrixDisplay)
Download the Dataset#
Let’s download the dataset of Medium articles from the Hugging Face Hub.
# download dataset of Medium articles from
# https://huggingface.co/datasets/fabiochiu/medium-articles
df_articles = pd.read_csv(
hf_hub_download("fabiochiu/medium-articles", repo_type="dataset", filename="medium_articles.csv")
)
df_articles.head()
| title | text | url | authors | timestamp | tags | |
|---|---|---|---|---|---|---|
| 0 | Mental Note Vol. 24 | Photo by Josh Riemer on Unsplash\n\nMerry Chri... | https://medium.com/invisible-illness/mental-no... | ['Ryan Fan'] | 2020-12-26 03:38:10.479000+00:00 | ['Mental Health', 'Health', 'Psychology', 'Sci... |
| 1 | Your Brain On Coronavirus | Your Brain On Coronavirus\n\nA guide to the cu... | https://medium.com/age-of-awareness/how-the-pa... | ['Simon Spichak'] | 2020-09-23 22:10:17.126000+00:00 | ['Mental Health', 'Coronavirus', 'Science', 'P... |
| 2 | Mind Your Nose | Mind Your Nose\n\nHow smell training can chang... | https://medium.com/neodotlife/mind-your-nose-f... | [] | 2020-10-10 20:17:37.132000+00:00 | ['Biotechnology', 'Neuroscience', 'Brain', 'We... |
| 3 | The 4 Purposes of Dreams | Passionate about the synergy between science a... | https://medium.com/science-for-real/the-4-purp... | ['Eshan Samaranayake'] | 2020-12-21 16:05:19.524000+00:00 | ['Health', 'Neuroscience', 'Mental Health', 'P... |
| 4 | Surviving a Rod Through the Head | You’ve heard of him, haven’t you? Phineas Gage... | https://medium.com/live-your-life-on-purpose/s... | ['Rishav Sinha'] | 2020-02-26 00:01:01.576000+00:00 | ['Brain', 'Health', 'Development', 'Psychology... |
Text Preprocessing and Train/Test Split#
First, we concatenate the title and the text content of each article, creating the full_text column. We also create the is_data_science column, which indicates whether the article has the “Data Science” tag.
# create two columns:
# - full_text: contains the concatenation of the title and the text of the article.
# - is_data_science: a boolean which is True if the article has the "Data Science" tag
df_articles["is_data_science"] = df_articles["tags"] \
.apply(lambda tags_list: "Data Science" in tags_list)
df_articles["full_text"] = df_articles["title"] + " " + df_articles["text"]
df_articles.head()
| title | text | url | authors | timestamp | tags | is_data_science | full_text | |
|---|---|---|---|---|---|---|---|---|
| 0 | Mental Note Vol. 24 | Photo by Josh Riemer on Unsplash\n\nMerry Chri... | https://medium.com/invisible-illness/mental-no... | ['Ryan Fan'] | 2020-12-26 03:38:10.479000+00:00 | ['Mental Health', 'Health', 'Psychology', 'Sci... | False | Mental Note Vol. 24 Photo by Josh Riemer on Un... |
| 1 | Your Brain On Coronavirus | Your Brain On Coronavirus\n\nA guide to the cu... | https://medium.com/age-of-awareness/how-the-pa... | ['Simon Spichak'] | 2020-09-23 22:10:17.126000+00:00 | ['Mental Health', 'Coronavirus', 'Science', 'P... | False | Your Brain On Coronavirus Your Brain On Corona... |
| 2 | Mind Your Nose | Mind Your Nose\n\nHow smell training can chang... | https://medium.com/neodotlife/mind-your-nose-f... | [] | 2020-10-10 20:17:37.132000+00:00 | ['Biotechnology', 'Neuroscience', 'Brain', 'We... | False | Mind Your Nose Mind Your Nose\n\nHow smell tra... |
| 3 | The 4 Purposes of Dreams | Passionate about the synergy between science a... | https://medium.com/science-for-real/the-4-purp... | ['Eshan Samaranayake'] | 2020-12-21 16:05:19.524000+00:00 | ['Health', 'Neuroscience', 'Mental Health', 'P... | False | The 4 Purposes of Dreams Passionate about the ... |
| 4 | Surviving a Rod Through the Head | You’ve heard of him, haven’t you? Phineas Gage... | https://medium.com/live-your-life-on-purpose/s... | ['Rishav Sinha'] | 2020-02-26 00:01:01.576000+00:00 | ['Brain', 'Health', 'Development', 'Psychology... | False | Surviving a Rod Through the Head You’ve heard ... |
Let’s then keep only 1,000 samples of articles with the “Data Science” tag and 1,000 samples without it.
# sample 1000 articles is_data_science = True and 1000 articles with
# is_data_science = False
df = pd.concat([
df_articles[df_articles["is_data_science"]].sample(n=1000),
df_articles[~df_articles["is_data_science"]].sample(n=1000)
])
We download a sentence embeddings model, such as all-MiniLM-L6-v2…
# download the sentence embeddings model
embedder = SentenceTransformer('all-MiniLM-L6-v2')
… and then use it to generate an embedding for each article in the dataset using the full_text column.
# embed article texts
corpus = df["full_text"].values
corpus_embeddings = embedder.encode(corpus)
print(corpus_embeddings.shape)
(2000, 384)
We now have 2,000 embeddings (1,000 for articles with the “Data Science” tag, 1,000 for articles without it), each one with 384 dimensions (which is the number of dimensions of the embeddings produced with the specific all-MiniLM-L6-v2 model).
Let’s split the articles into training set and test set.
# train/test split
X = corpus_embeddings
y = df["is_data_science"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42, stratify=y)
Model Training and Evaluation#
Let’s train a LogisticRegression model on the training set.
# train model
model = LogisticRegression()
model.fit(X_train, y_train)
We can then produce the predictions on the test set and use the classification_report utility function from sklearn.metrics to quickly see metrics like precision, recall, and F1 score.
# compute predictions on test set
predictions = model.predict(X_test)
# plot precision, recall, f1-score on test set
print(classification_report(y_test, predictions))
precision recall f1-score support
False 0.89 0.90 0.89 200
True 0.89 0.89 0.89 200
accuracy 0.89 400
macro avg 0.89 0.89 0.89 400
weighted avg 0.89 0.89 0.89 400
Let’s see the confusion matrix over the test set as well.
# plot confusion matrix
cm = confusion_matrix(y_test, predictions, labels=model.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=["No Data Science", "Data Science"])
p = disp.plot()
fig = p.figure_
fig.set_facecolor('white')
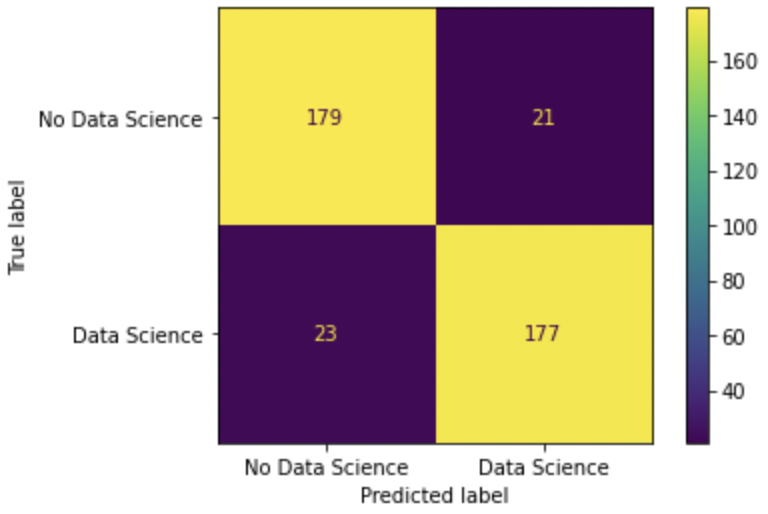
The results are slightly better than the ones using the CountVectorizer from the previous lessons. Last, we can also try the models with custom texts and see if it classifies them correctly.
# try the model with custom text
text = "How to deal with precision and recall"
text_embedding = embedder.encode(text)
result = model.predict([text_embedding])[0]
print(result)
True
# try the model with custom text
text = "How to sleep better"
text_embedding = embedder.encode(text)
result = model.predict([text_embedding])[0]
print(result)
False
Code Exercises#
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.