2.13 Project: Semantic Image Search over Unsplash
Contents
2.13 Project: Semantic Image Search over Unsplash#
OpenAI’s CLIP makes it effortless to find images using natural language searches. Let’s see how we can do it, using the Unsplash dataset.
CLIP#
CLIP (Contrastive Language–Image Pre-training) is a model that can learn visual concepts from natural language supervision. By training with pairs of images and their descriptions, abundantly available online, CLIP can predict which text snippet belongs with a given image and vice-versa. This ability gives CLIP impressive zero-shot performance across a range of image classification datasets.
Powered by the Transformer architecture, CLIP is composed of a text encoder and an image encoder.
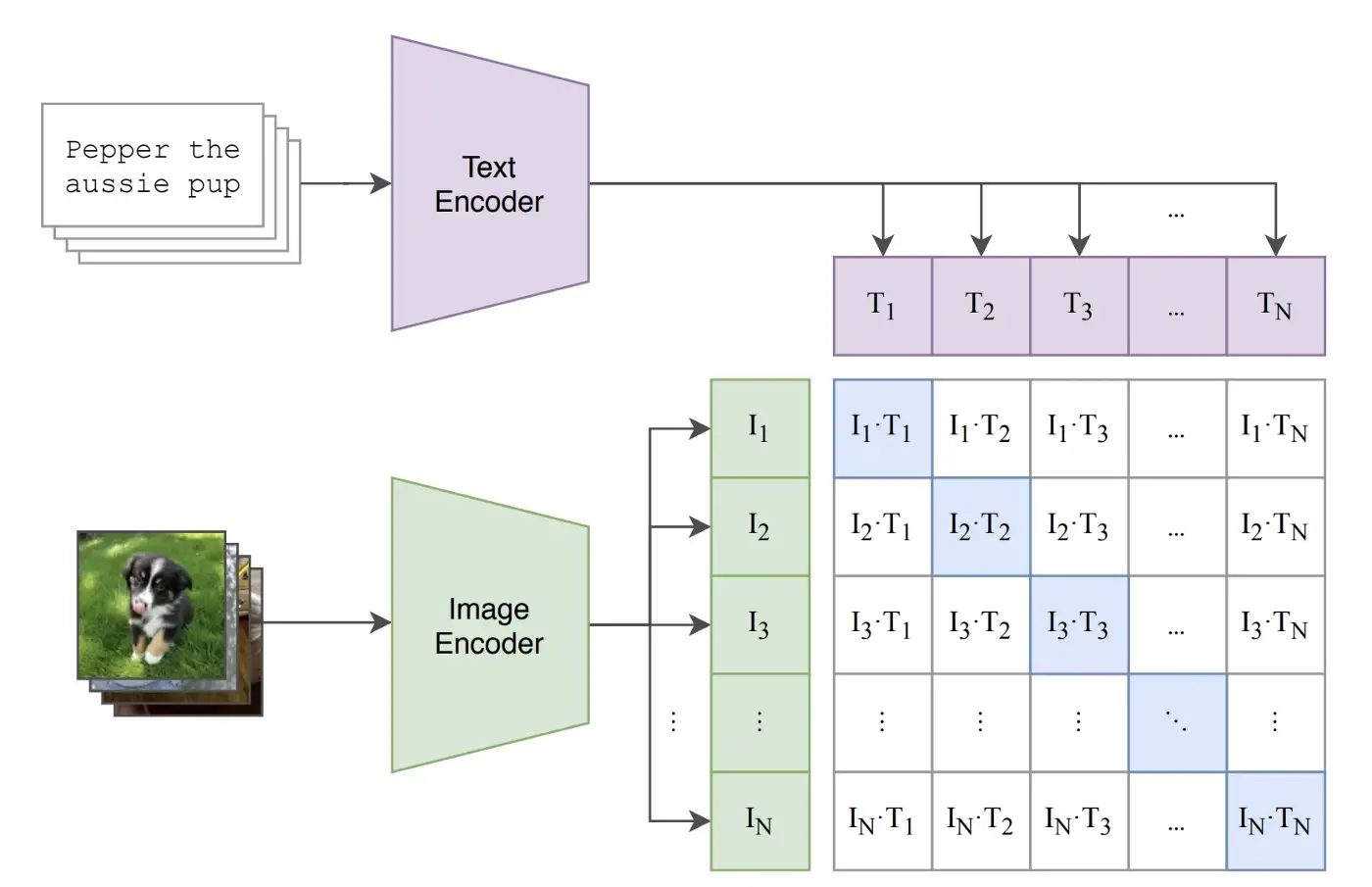
Both the image encoder and the text encoder produce embeddings with the same dimensions, allowing for computing similarity between texts and images. Leveraging these encoders, it’s possible to build semantic search engines that use texts or images as queries and return texts and images as documents.
Unsplash Dataset#
The Unsplash Dataset is a comprehensive, open-source collection of high-resolution images released in 2020 and free to use to further research in machine learning. Its lite version offers 25,000 images for commercial or non-commercial usage, while the full version has over 3 million images exclusively for non-commercial use.
In this project we’ll use its lite version.
Semantic Search with CLIP and Unsplash#
We’re going to implement the following pipeline:
Download the CLIP model and the Unsplash dataset.
Use the CLIP image encoder to encode all the images in the Unsplash dataset and store them.
Use the CLIP text encoder to encode a text query.
Compute the cosine similarity between the query embedding and all the image embeddings.
Retrieve the top N images with the highest similarity and show them to the user.
The sentence-transformers library has several utility functions that make semantic image search quick to implement, so we’re going to use it in our project.
Coding with Python#
We are now ready to start implementing the pipeline in code.
Install and Import Libraries#
Let’s install the necessary libraries.
pip install datasets sentence-transformers
Then we import several libraries. We’ll use urllib.request to download images from urls, multiprocessing to leverage threads to download images faster, and PIL to work with images.
# manage data
from datasets import load_dataset
import pandas as pd
import numpy as np
# download images
import urllib.request
from pathlib import Path
from multiprocessing.pool import ThreadPool
import os
# manage images
from PIL import Image
# semantic image search
from sentence_transformers import SentenceTransformer, util
Download Dataset#
We can download the Unsplash Dataset leveraging a script available as a Hugging Face Dataset.
# download dataset
dataset = load_dataset("jamescalam/unsplash-25k-photos", split="train")
print(dataset)
Dataset({
features: ['photo_id', 'photo_url', 'photo_image_url', 'photo_submitted_at', 'photo_featured', 'photo_width', 'photo_height', 'photo_aspect_ratio', 'photo_description', 'photographer_username', 'photographer_first_name', 'photographer_last_name', 'exif_camera_make', 'exif_camera_model', 'exif_iso', 'exif_aperture_value', 'exif_focal_length', 'exif_exposure_time', 'photo_location_name', 'photo_location_latitude', 'photo_location_longitude', 'photo_location_country', 'photo_location_city', 'stats_views', 'stats_downloads', 'ai_description', 'ai_primary_landmark_name', 'ai_primary_landmark_latitude', 'ai_primary_landmark_longitude', 'ai_primary_landmark_confidence', 'blur_hash'],
num_rows: 25000
})
Then, we convert the dataset to a pandas dataframe.
# convert dataset to pandas dataframe
df = pd.DataFrame(dataset)
df.head()
| photo_id | photo_url | photo_image_url | photo_submitted_at | photo_featured | photo_width | photo_height | photo_aspect_ratio | photo_description | photographer_username | ... | photo_location_country | photo_location_city | stats_views | stats_downloads | ai_description | ai_primary_landmark_name | ai_primary_landmark_latitude | ai_primary_landmark_longitude | ai_primary_landmark_confidence | blur_hash | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | XMyPniM9LF0 | https://unsplash.com/photos/XMyPniM9LF0 | https://images.unsplash.com/uploads/1411949294... | 2014-09-29 00:08:38.594364 | t | 4272 | 2848 | 1.50 | Woman exploring a forest | michellespencer77 | ... | NaN | NaN | 2375421 | 6967 | woman walking in the middle of forest | NaN | NaN | NaN | NaN | L56bVcRRIWMh.gVunlS4SMbsRRxr |
| 1 | rDLBArZUl1c | https://unsplash.com/photos/rDLBArZUl1c | https://images.unsplash.com/photo-141633941111... | 2014-11-18 19:36:57.08945 | t | 3000 | 4000 | 0.75 | Succulents in a terrarium | ugmonk | ... | NaN | NaN | 13784815 | 82141 | succulent plants in clear glass terrarium | NaN | NaN | NaN | NaN | LvI$4txu%2s:_4t6WUj]xat7RPoe |
| 2 | cNDGZ2sQ3Bo | https://unsplash.com/photos/cNDGZ2sQ3Bo | https://images.unsplash.com/photo-142014251503... | 2015-01-01 20:02:02.097036 | t | 2564 | 1710 | 1.50 | Rural winter mountainside | johnprice | ... | NaN | NaN | 1302461 | 3428 | rocky mountain under gray sky at daytime | NaN | NaN | NaN | NaN | LhMj%NxvM{t7_4t7aeoM%2M{ozj[ |
| 3 | iuZ_D1eoq9k | https://unsplash.com/photos/iuZ_D1eoq9k | https://images.unsplash.com/photo-141487280988... | 2014-11-01 20:15:13.410073 | t | 2912 | 4368 | 0.67 | Poppy seeds and flowers | krisatomic | ... | NaN | NaN | 2890238 | 33704 | red common poppy flower selective focus phography | NaN | NaN | NaN | NaN | LSC7DirZAsX7}Br@GEWWmnoLWCnj |
| 4 | BeD3vjQ8SI0 | https://unsplash.com/photos/BeD3vjQ8SI0 | https://images.unsplash.com/photo-141700759404... | 2014-11-26 13:13:50.134383 | t | 4896 | 3264 | 1.50 | Silhouette near dark trees | jonaseriksson | ... | NaN | NaN | 8704860 | 49662 | trees during night time | NaN | NaN | NaN | NaN | L25|_:V@0hxtI=W;odae0ht6=^NG |
5 rows × 31 columns
Notice that the dataframe contains the urls of the images, not the images themselves.
Download Images#
So, we have to use these urls to download all the images. Let’s create a directory unsplash-dataset where we’ll put all the images.
# create directory to store the images
image_directory = "unsplash-dataset"
os.mkdir(image_directory)
# get photo ids and urls
photo_ids_and_urls = df[['photo_id', 'photo_image_url']].values.tolist()
Then, we implement the download_photo function that downloads an image from its url and saves it in the unsplash-dataset directory using its id as name. We run this function once for every photo id in our dataframe, parallelizing over 64 threads to make it faster.
# function to download a single photo
def download_photo(photo_id_and_url):
photo_id, photo_url = photo_id_and_url
photo_url += "?w=640" # set expected width
# path where the image will be stored
photo_path = Path(image_directory + "/" + photo_id + ".jpg")
# download image
if not photo_path.exists():
try:
urllib.request.urlretrieve(photo_url, photo_path)
except:
print(f"Cannot download {photo_url}")
pass
# create thread pool
threads_count = 64
pool = ThreadPool(threads_count)
# start the download of all images
pool.map(download_photo, photo_ids_and_urls) # ~5 minutes of execution time on Colab
After some minutes, we can check how many images have been downloaded (some downloads may have raised errors).
# get the ids of the downloaded photos
photo_ids = [
f.split("/")[-1].split(".")[0]
for f in os.listdir(image_directory)
]
print(f"Downloaded {len(photo_ids)} images")
Downloaded 24948 images
Compute Images Embeddings#
We are now ready to compute the image embeddings. Let’s download the CLIP model using the sentence-transformers library.
# download CLIP model
model = SentenceTransformer('clip-ViT-B-32')
Then, we open each image using PIL and pass them to CLIP to obtain the image embeddings.
# compute image embeddings
num_images_to_encode = 1000
images = [
Image.open(image_directory + "/" + photo_id + ".jpg")
for photo_id in photo_ids[:num_images_to_encode]
]
image_embeddings = model.encode(images)
Compute Text Embeddings#
Similarly, we can pass a text to the CLIP model to get its corresponding text embedding. We can then compute the cosine similarity between the text embedding and all the image embeddings, sort the scores and retrieve the images with the highest cosine similarity.
# compute text embedding
query = "A photo of a dog"
text_embeddings = model.encode(query)
# compute cosine similarity scores with all the images
cosine_scores = util.cos_sim(image_embeddings, text_embeddings)
cosine_scores = cosine_scores.flatten().detach().numpy()
# get the indexes of the images with the highest scores
best_indexes = np.argsort(cosine_scores)[::-1]
# show some results
for i in range(3):
# show image
image = images[best_indexes[i]]
display(image)
Here are some images returned by the pipeline when searching with the query “A photo of a dog”.


And here are an image returned when searching with the query “A photo of a cat”.

When used on the full Unsplash dataset, you’ll get results like the following.

Fig. 3 Result for query “Dogs and cats at home”#

Fig. 4 Result for query “Screaming cat”#

Fig. 5 Result for query “Cooking dog”#
Faiss and Image Search
Of course we could use a space-partitioning index with faiss to make the search more efficient. Try doing that following the examples of faiss usage from the previous lessons.
Code Exercises#
Quiz#
What does the acronym CLIP stand for?
Contrastive Language–Image Pre-training
Computational Linguistics Inference Pipeline
Cross-Lingual Information Processing
Contrastive Learning of Image-Text Representations
Corpus-Level Interpretation Parsing
Answer
The correct answer is 1.
What’s the goal of the training of the CLIP model?
To generate an image from a given description.
To classify images according to a given set of classes.
To generate natural language descriptions from images.
To learn the relationships between words in a sentence.
To learn the correspondences between images and their textual descriptions.
Answer
The correct answer is 5. All the other options are tasks that CLIP can be used for, but they are not the goal of its training.
True or False. Using CLIP, it’s possible to perform image search using an image as query.
Answer
The correct answer is True.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.