2.7 Evaluating a Sentiment Analysis Model
Contents
2.7 Evaluating a Sentiment Analysis Model#
We saw in the previous lesson how to use a pre-trained model to compute the sentiment of tweets regarding specific products or services. In this lesson, we learn how to evaluate models to understand which one is better for our task.
Finding Benchmarks for Sentiment Analysis#
Research uses standard datasets to evaluate sentiment analysis models, so that results from different methods are comparable. Let’s look at the PapersWithCode page about sentiment analysis.
In that page, you should find a “Benchmarks” section, containing a list of datasets commonly used for evaluation.
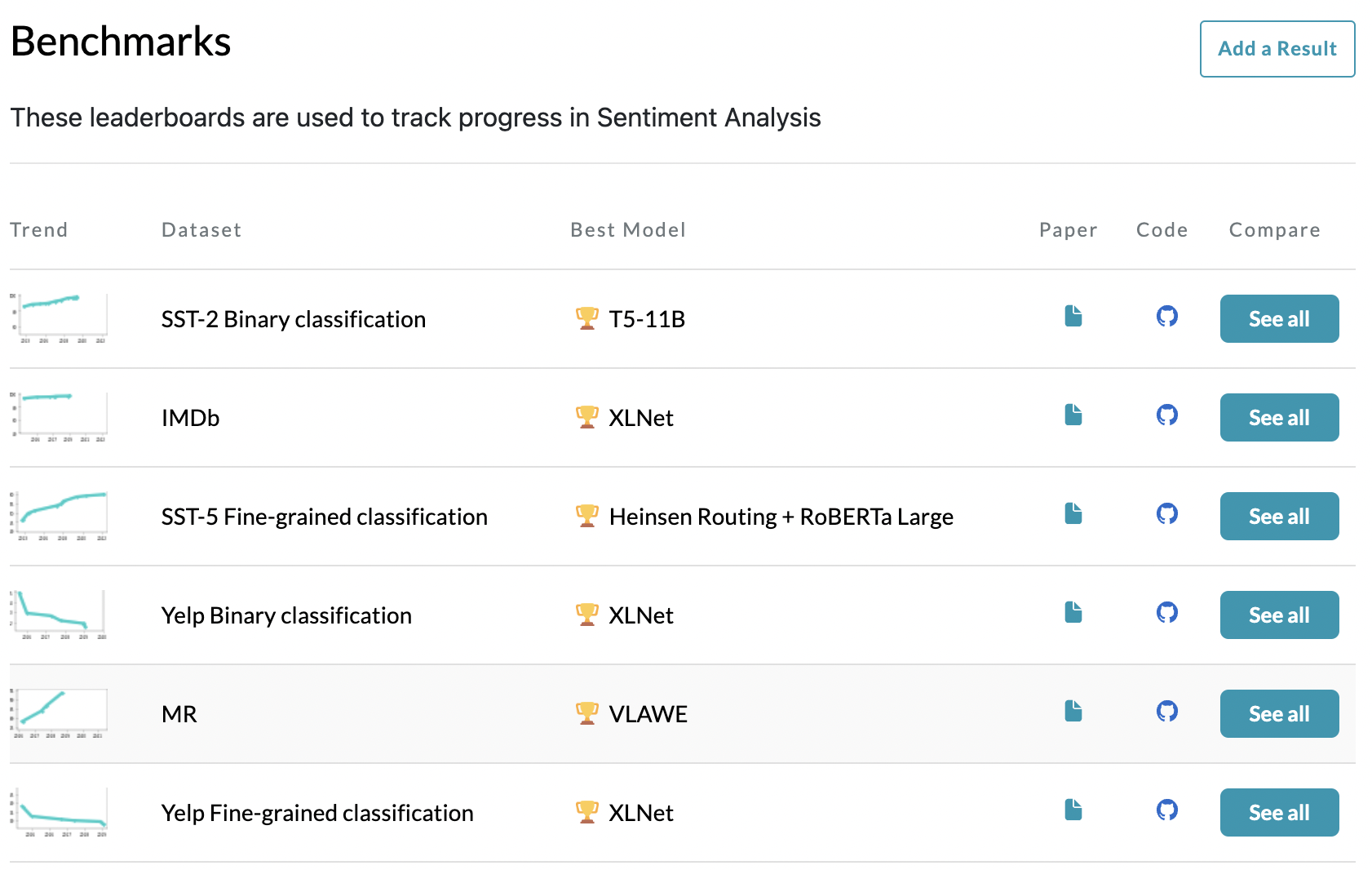
Let’s open the page of the IMDb dataset, a dataset for binary sentiment classification of movie reviews. You should see the leaderboard of the best models for the task, sorted by accuracy.
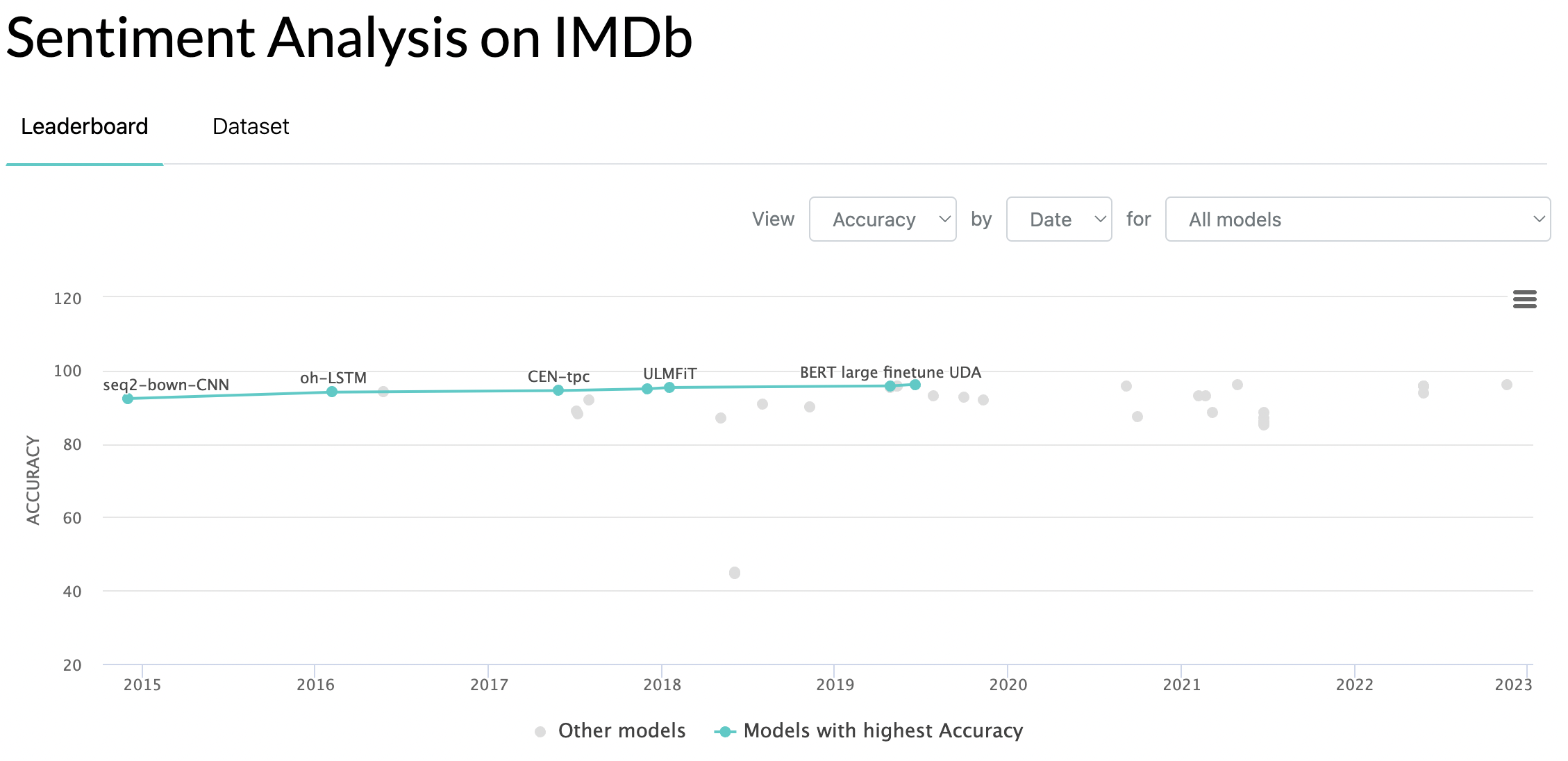
The best models achieve an accuracy of about 96% over the test set.
Evaluating a Model over IMDb#
Let’s see what accuracy we can get using pre-trained models from the Hub.
Install and Import Libraries#
First, let’s install and import the necessary libraries.
pip install transformers datasets
from datasets import load_dataset, load_metric
from transformers import pipeline
import pandas as pd
We also import the load_metric function from the datasets library, which contains the code for computing metrics such as accuracy.
Download IMDb Dataset#
Then, we download the test split of the IMDb dataset. Luckily, it can be found on the Hub.
# download the tweets dataset
dataset = load_dataset("imdb", split="test")
print(dataset)
Dataset({
features: ['text', 'label'],
num_rows: 25000
})
The dataset contains 25k samples, and each one is composed of the text of the movie review in the text field and the associated sentiment in the label field. Sentiment is expressed with 0 if negative, and 1 if positive.
Let’s convert the dataset to a pandas dataframe.
# convert dataset to pandas dataframe
df = pd.DataFrame(dataset)
df.head()
| text | label | |
|---|---|---|
| 0 | I love sci-fi and am willing to put up with a ... | 0 |
| 1 | Worth the entertainment value of a rental, esp... | 0 |
| 2 | its a totally average film with a few semi-alr... | 0 |
| 3 | STAR RATING: ***** Saturday Night **** Friday ... | 0 |
| 4 | First off let me say, If you haven't enjoyed a... | 0 |
Load Pre-trained Sentiment Model#
Next, we load a sentiment-analysis pipeline with the pre-trained distilbert-base-uncased-finetuned-sst-2-english model. This model is a checkpoint of DistilBERT-base-uncased, fine-tuned on SST-2 (so on movie reviews, but a different dataset from IMDb).
# download pre-trained sentiment model
model = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english", device=0)
Predict Sentiment#
We then use the model to compute the sentiment of all the reviews in the dataset. We are using the parameters truncation=True and max_length=512 because there are movie reviews longer than 512 tokens and in such cases the model would raise an error since it can handle at most 512 tokens. By specifying those parameters, texts longer than 512 tokens will be truncated, keeping only the first 512 tokens and ignoring the rest.
# compute the sentiment of each tweet using the model. It may take some minutes
all_texts = df["text"].values.tolist()
all_sentiments = model(all_texts, truncation=True, max_length=512)
df["prediction"] = [0 if d["label"] == "NEGATIVE" else 1 for d in all_sentiments]
df.head()
| text | label | prediction | |
|---|---|---|---|
| 0 | I love sci-fi and am willing to put up with a ... | 0 | 0 |
| 1 | Worth the entertainment value of a rental, esp... | 0 | 0 |
| 2 | its a totally average film with a few semi-alr... | 0 | 0 |
| 3 | STAR RATING: ***** Saturday Night **** Friday ... | 0 | 0 |
| 4 | First off let me say, If you haven't enjoyed a... | 0 | 0 |
Compute Accuracy (SST-2 Model)#
Let’s load the accuracy metric with the load_metric function. This function downloads the code to compute the accuracy from Hugging Face. In this way, new metrics can be uploaded and downloaded without changing the library.
# load "accuracy" metric
metric = load_metric('accuracy')
We are now ready to compute the accuracy using the predicted sentiment and the ground-truth labels. Notice the use of metric.compute().
# compute accuracy over test set
predictions = df["prediction"]
references = df["label"]
score = metric.compute(predictions=predictions, references=references)
print(score) # 0.89072
{'accuracy': 0.89072}
The distilbert-base-uncased-finetuned-sst-2-english achieves an accuracy of ~0.89. Is it good or bad compared to other pre-trained models? Let’s check it out.
Compute Accuracy (Tweets Model)#
Let’s compute the accuracy using the cardiffnlp/twitter-roberta-base-sentiment-latest model, which has been finetuned on tweets.
# download pre-trained sentiment model
model = pipeline("sentiment-analysis", model="cardiffnlp/twitter-roberta-base-sentiment-latest", device=0)
# compute the sentiment of each tweet using the model
all_texts = df["text"].values.tolist()
all_sentiments = model(all_texts, truncation=True, max_length=512)
df["prediction"] = [0 if d["label"] == "negative" else 1 for d in all_sentiments]
# compute accuracy over test set
metric = load_metric('accuracy')
predictions = df["prediction"]
references = df["label"]
score = metric.compute(predictions=predictions, references=references)
print(score) # 0.80772
{'accuracy': 0.80772}
The accuracy is now ~0.81, which is far lower than the ~0.89 accuracy obtained by the distilbert-base-uncased-finetuned-sst-2-english. This difference is expected, as movie reviews and tweets are different, and we are evaluating on movie reviews. Still, the model fine-tuned on tweets is much better than the random baseline (that would reach ~0.5 accuracy), because there is obviously a lot of reasoning in common in computing sentiment on tweets and movie reviews.
Compute Accuracy (IMDb Model)#
Last, let’s check also the accuracy achieved by a model finetuned on the train split of the IMDb dataset (the same dataset we are evaluating on).
# download pre-trained sentiment model
model = pipeline("sentiment-analysis", model="lvwerra/distilbert-imdb", device=0)
# compute the sentiment of each tweet using the model
all_texts = df["text"].values.tolist()
all_sentiments = model(all_texts, truncation=True, max_length=512)
df["prediction"] = [0 if d["label"] == "NEGATIVE" else 1 for d in all_sentiments]
# compute accuracy over test set
metric = load_metric('accuracy')
predictions = df["prediction"]
references = df["label"]
score = metric.compute(predictions=predictions, references=references)
print(score) # 0.928
{'accuracy': 0.928}
The model fine-tuned on the training split of IMDb reaches an accuracy of ~0.93, which is even better than the model fine-tuned on SST-2 (~0.89 accuracy). Indeed, even if both IMDb and SST-2 are about movie reviews, their movie reviews are different, and such differences result in the accuracy gain/drop on the test set.
Lessons on Using Pre-trained Models vs Fine-tuning Your Own Model#
So, if we had to compute the sentiment of movie reviews published on our site, which model should we use? Is it better to use a pre-trained model trained on other (different) movie reviews like IMDb or SST-2, or is it better to take one of these and do further fine-tuning on my own movie reviews?
The typical answer to this category of questions is: it depends.
If you estimate that a ~4% improvement in accuracy (taken from the movie reviews example in this lesson) on your data will bring more benefits than the costs of building your dataset and finetuning a model, then it is better to proceed with the finetuning.
Otherwise, it’s best to use a pre-trained model and have a good-enough solution right away, without the extra expenses.
For example, if you are Google and you want to improve your ad placement algorithm, then probably every 0.01% of model improvement brings you millions of dollars in profit, and therefore it makes sense to spend a lot of resources to find the best model. If you are a small business that wants to improve its customer service by finding tweets with negative sentiment and responding to those users, then it probably makes sense to use a good-enough pre-trained model directly, without spending any additional resources.
Code Exercises#
Quiz#
Select the option that is not related to a sentiment analysis dataset.
IMDb
SST-2
SQuAD.
Answer
The correct answer is 3. SQuAD is a popular dataset for question answering.
What’s the name of the function from the datasets library that allows downloading and computing metrics, such as accuracy?
accuracy_scoreload_metricevaluatecompute_metric
Answer
The correct answer is 2.
What type of data is contained in the IMDb dataset?
Tweets
General info about each movie
Movie ratings
Movie reviews
Answer
The correct answer is 4.
When should someone fine-tune a model on new data instead of using a pre-trained model directly, even if trained on similar data?
When the improvements that fine-tuning brings to your model have more benefits than the costs of building a dataset and fine-tuning the model.
When the data you have is specialized to a particular domain or task.
When the pre-trained model does not have enough capacity to capture the complexity of your data.
When the pre-trained model has not been trained on a sufficiently large dataset.
Answer
The correct answer is 1.
What’s the meaning of the device parameter of a Hugging Face pipeline?
It specifies the size of the output data to be produced by the model.
It specifies which type of algorithm to use for natural language processing tasks.
It specifies the size of the input data to be processed by the model.
It specifies the device (e.g. CPU or GPU) to use for computations by the model.
Answer
The correct answer is 4.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.