2.3 Hugging Face Hub: Datasets
Contents
2.3 Hugging Face Hub: Datasets#
Let’s continue our exploration of the Hugging Face Hub, focusing on datasets now.
Datasets#
There’s a section in the Hugging Face Hub specifically for datasets.
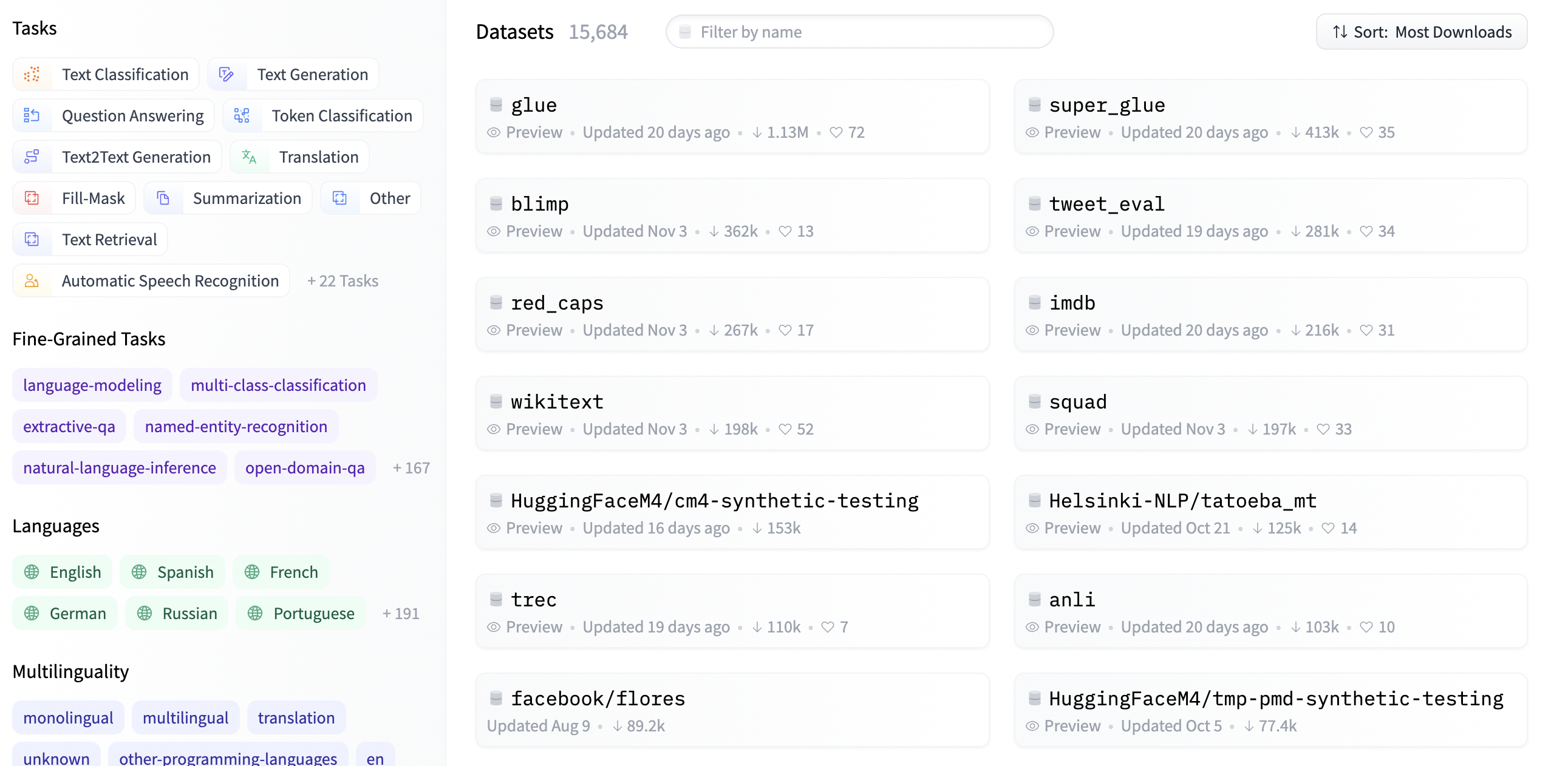
As for models, there are several filters that we can use for filtering datasets, like:
Tasks: The task for which the dataset has been created. They are the same tasks that can be found for models.
Fine-Grained Tasks: More specific tasks. Some examples are
sentiment-analysis,topic-classification,multiple-choice-qa, andfact-checking.Languages: The languages used in the dataset.
Multilinguality: Whether the dataset can be used for multilingual model or not.
Sizes: The number of samples in the dataset.
Licenses: How the dataset can be used (e.g. for commercial use or not).
Let’s see the dataset page of the imdb dataset. The IMDb dataset is a dataset of 25,000 highly polar movie reviews for training, and 25,000 for testing. It’s meant for binary sentiment classification.
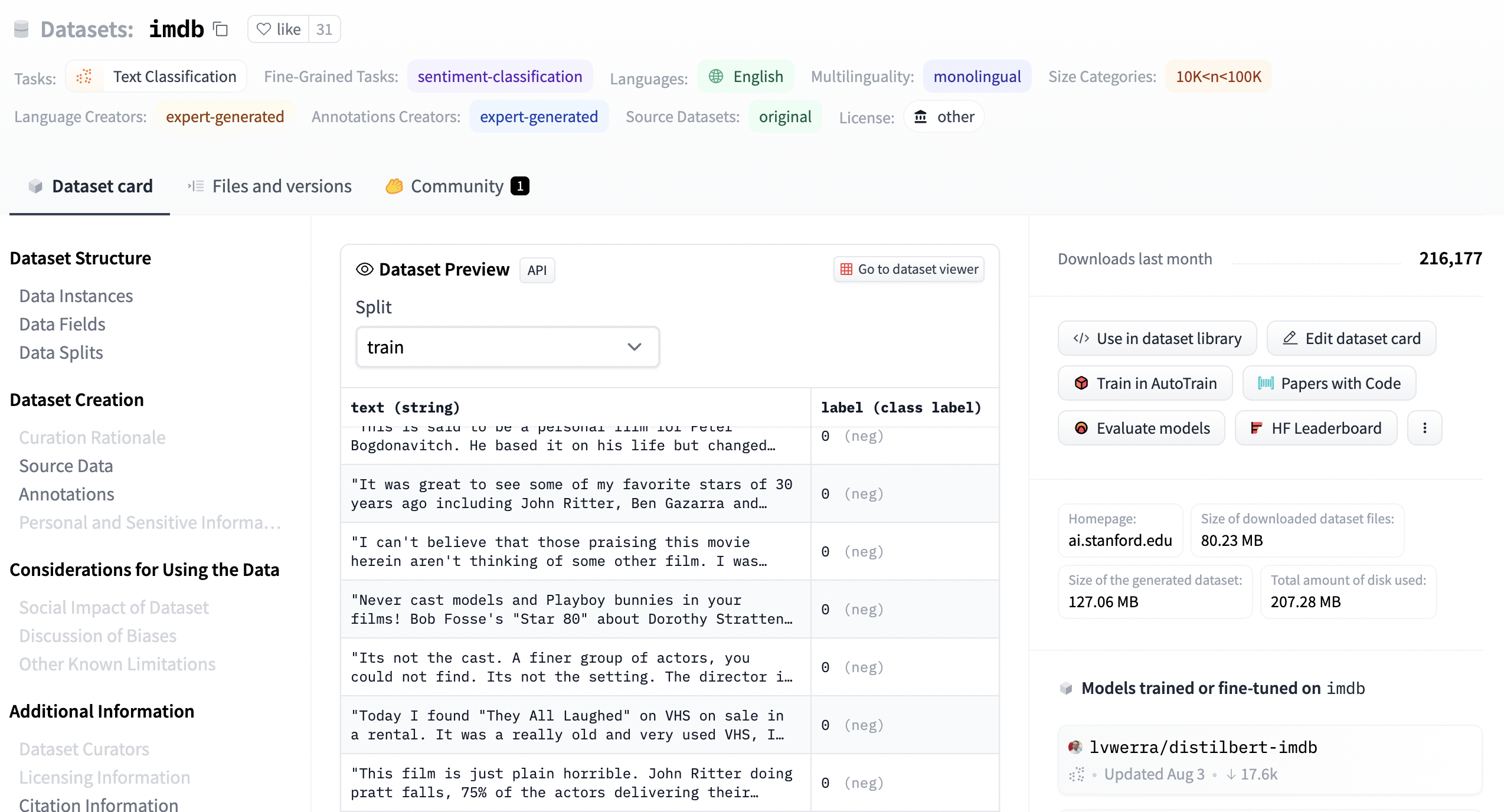
The page is structured similarly to the model pages. You can find the tags associated with the datasets, and the “Files and versions” and “Community” tabs. There’s a section called “Dataset Preview” that lets you see some of the samples from the dataset, specifying from which split (e.g. training set or test set). In this specific dataset, a label with a value of 0 means negative sentiment, whereas a label of 1 is positive.
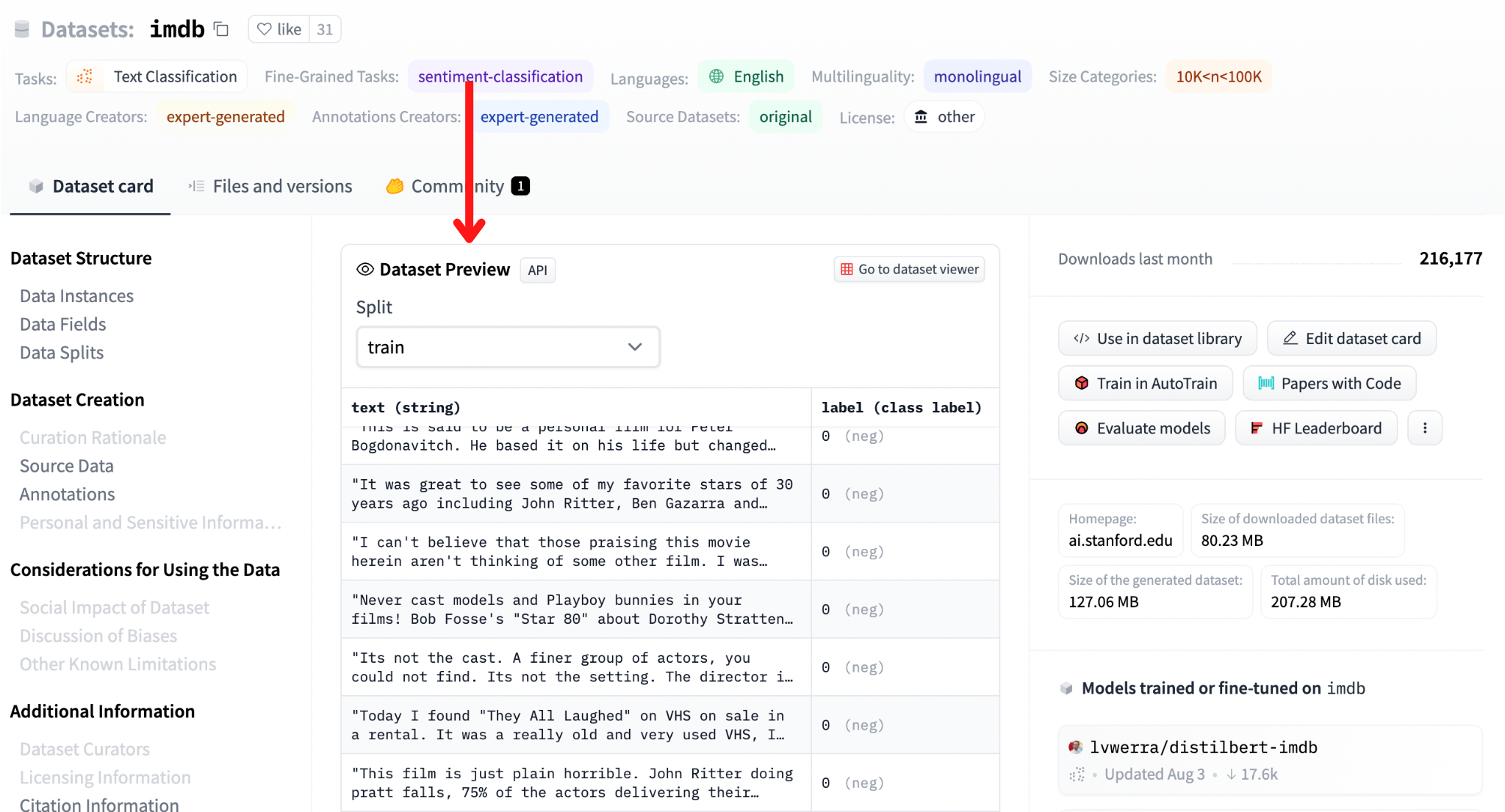
Dataset Card#
Under the “Dataset Preview” section, you’ll find another section called “Dataset card”.
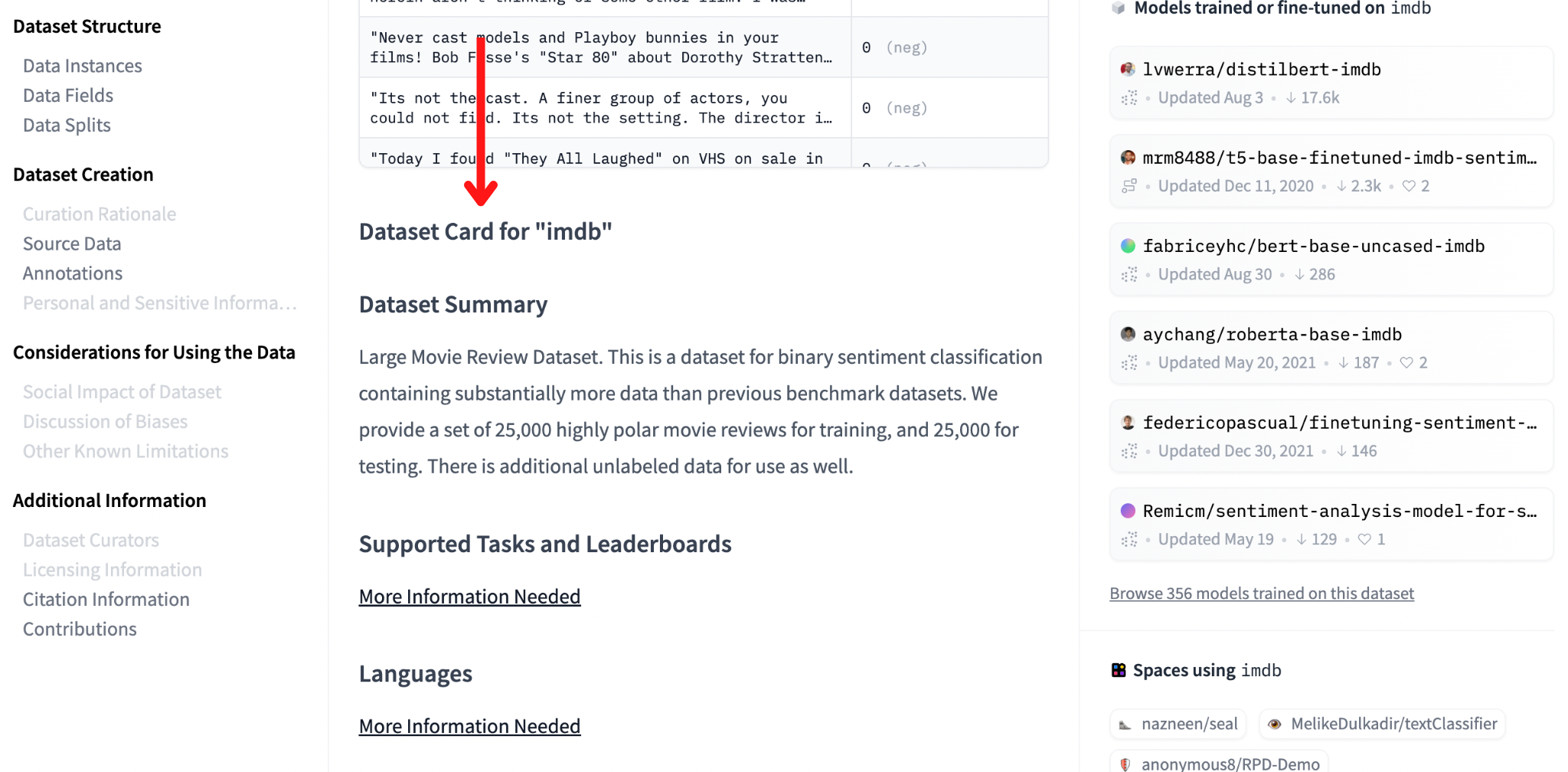
Similarly to the model card, a dataset card lists useful information about a dataset, like:
How the dataset has been created.
Supported tasks and languages.
How to responsibly use the data.
Potential biases within the dataset.
The dataset card is automatically generated from the README.md file in the dataset repository.
Quiz#
Choose the incorrect option. On the Hugging Face Hub, datasets can be filtered by:
License.
Languages of the samples contained.
Number of models that have been trained on the dataset.
Multilinguality, i.e. whether the dataset can be used for multilingual model or not.
Size of the dataset (i.e. the number of samples contained).
Tasks for which the dataset has been created.
Answer
The correct answer is 3.
True or False. Is it possible to see some samples directly from the dataset page?
Answer
The correct answer is True. There is a “Dataset Preview” section on the dataset page.
What is a dataset card and what does it typically contain?
A document that lists useful information about a dataset, like its creation process or how to responsibly use the data.
A document that lists useful information about a dataset, like the best models trained with it and their scores.
A document that lists useful information about a dataset, like its authors and other similar datasets.
Answer
The correct answer is 1.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.