2.10 Semantic Search on Big Data
Contents
2.10 Semantic Search on Big Data#
In the first chapter of the course we had lessons where we leveraged the SBERT (sentence transformers) library to compute similarities between texts, which can be used to build smart search engines, recommender systems, or clustering texts. In this lesson, we’ll learn how to use those models over a large number of texts efficiently.
Models from the SBERT Library#
The models used by the SBERT library are pre-trained models that can be found in the Hugging Face Hub here. Have a look at them and learn about their differences.
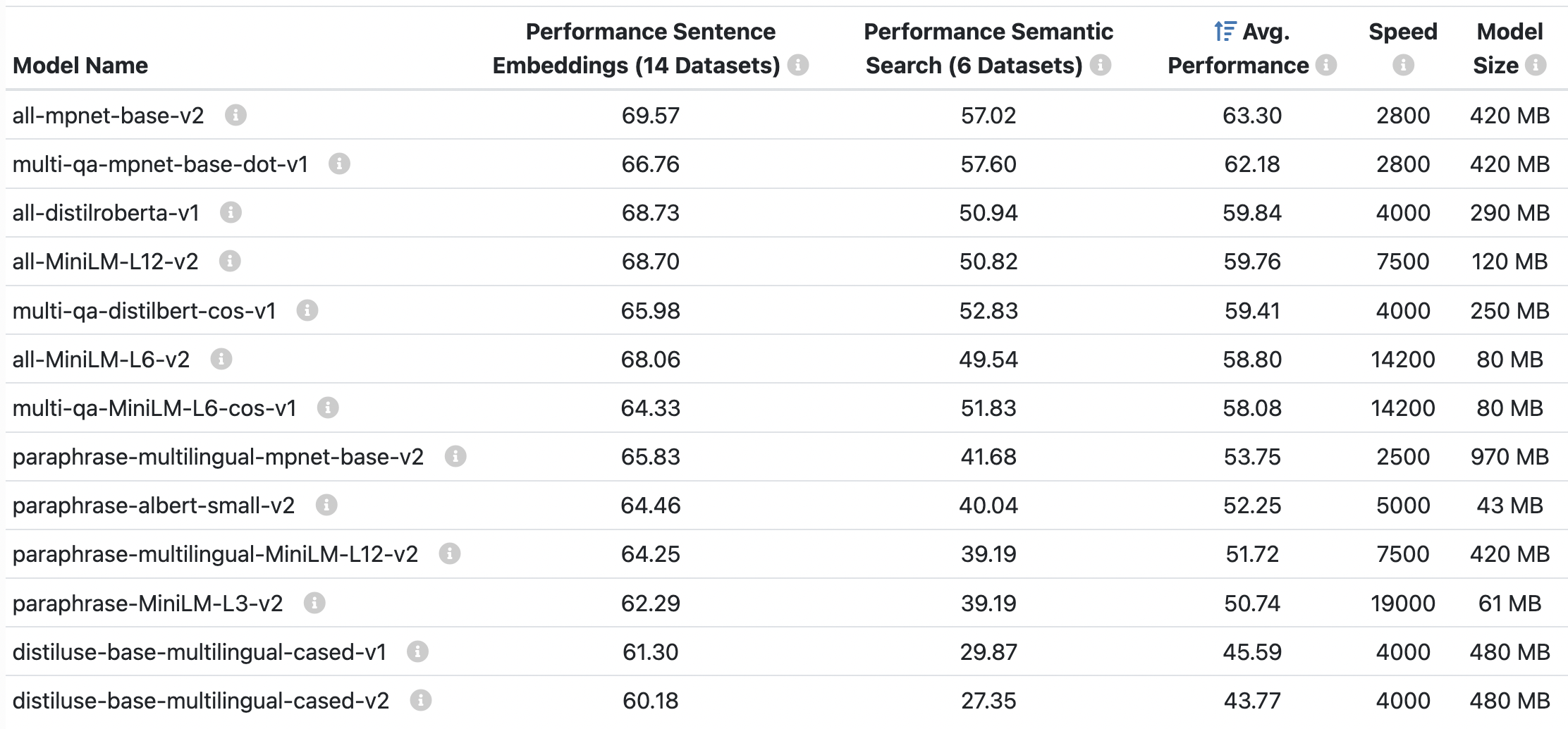
The all-mpnet-base-v2 model achieves good scores both on embedding (e.g. text classification and text similarity) and semantic search tasks, making it the preferable model for most use cases. If your specific use case needs a smaller and faster model, you can trade off output quality for speed/size and choose other models like all-MiniLM-L6-v2.
Semantic Search#
Let’s recap how semantic (a.k.a. smart) search is done with text embeddings:
All the documents are embedded using and embedding model.
The query is embedded using the same model, producing the query embedding.
A similarity between the query embedding and the embedding of each document is computed.
The document with the highest similarity is returned as the best result.
Speeding up Semantic Search#
Step 3 can be performed rather quickly for up to 100k documents as cosine or dot similarity is implemented using vectorization on CPU, making it very fast.
Still, if there are more than 1M documents, the search is too slow for many use cases, requiring several seconds. A solution for this problem is performing step 3 with space-partitioning data structures like vector databases. A vector database allows storing vectors and searching among them using algorithms like approximate nearest-neighbors, which runs fast also for several millions or trillions of documents.
You may easily perform fast semantic search with libraries like Faiss or Annoy. Let’s see a code example with Faiss.
Install and Import Libraries#
Let’s install and import the necessary libraries.
!pip install faiss-cpu
Note that we are installing the CPU version of Faiss. In case we wanted to leverage the GPU, we could install Faiss with pip install faiss-gpu.
Generate Vectors#
Let’s generate 1M vectors of 512 dimensions as our dataset of embeddings to search into.
import numpy as np
from sklearn.preprocessing import normalize
np.random.seed(1234)
num_dimensions = 512
number_of_vectors = 10**6
vectors = np.random.random((number_of_vectors, num_dimensions)).astype('float32')
vectors = normalize(vectors)
Brute-force Search (Slow)#
First, let’s do semantic search in a naive way, computing the L2 distance between a query vector and each vector in the dataset. To do so, we create a IndexFlatL2 index and add our vectors to it.
import faiss
# create index
index = faiss.IndexFlatL2(num_dimensions)
index.add(vectors)
Next, we create a random query vector and use the index to search for its 4 nearest neighbors in the dataset. Notice that we are using the %%time Jupyter notebook magic command to show the total execution time of the cell.
%%time
# create query vector
query_vector = np.random.random((1, num_dimensions)).astype('float32')
query_vector = normalize(query_vector)
# search
num_neighbors = 4
distances, indexes = index.search(query_vector, num_neighbors)
print(distances)
print(indexes)
# [[0.37844324 0.37946755 0.37967968 0.38305143]]
# [[450821 418151 572227 91717]]
# CPU times: user 268 ms, sys: 0 ns, total: 268 ms
# Wall time: 274 ms
The total execution time is of 274ms.
Search with Space-partitioning Index (Fast)#
Now, let’s try a space-partitioning index, such as IndexIVFFlat. This index splits the n-dimensional space of our vectors into a specific number of cells (e.g. 1000 in our code), so that each cell contains several vectors. When search is performed, the index looks for the cell whose centroid is closer to the query vector, and then computes the distances only between the query vector and the vectors in that cells and the adjacent cells. Doing so, a large number of computations is avoided.
import faiss
# create index
n_cells = 1000
quantizer = faiss.IndexFlatL2(num_dimensions)
index = faiss.IndexIVFFlat(quantizer, num_dimensions, n_cells)
index.train(vectors)
index.add(vectors)
Building the index takes some time but it’s done only once as a preprocessing step.
%%time
# create query vector
query_vector = np.random.random((1, num_dimensions)).astype('float32')
query_vector = normalize(query_vector)
# search
num_neighbors = 4
distances, indexes = index.search(query_vector, num_neighbors)
print(distances)
print(indexes)
# [[0.41423807 0.42537403 0.43084937 0.43127912]]
# [[323902 903322 497768 489604]]
# CPU times: user 4.26 ms, sys: 0 ns, total: 4.26 ms
# Wall time: 4.28 ms
Notice how this time it took only 4ms to find the nearest neighbors of our query vector, instead of 274ms for the brute-force search.
Code Exercises#
Quiz#
What should I typically do if the embedding model that I want to use is too slow?
Use a different smaller and faster embedding model, even if it may produce lower quality embeddings.
Increase the speed of the model by optimizing the architecture and hyperparameters.
Implement caching to enable faster embedding retrieval.
Answer
The correct answer is 1.
Why are operations like dot or cosine similarity fast on CPU?
Because of vectorization.
Because the operations are simple and easy to calculate.
Because the calculations are done without involving the memory.
Because of cache locality.
Answer
The correct answer is 1.
What are data structures that split spaces into cells to optimize computations called?
Grid-based data structures.
Spatial indexing data structures.
Space-partitioning data structures.
Answer
The correct answer is 3.
What are two popular Python libraries used to perform fast semantic search?
Pattern and Numpy.
Spacy and NLTK.
Gensim and Scikit-Learn.
Faiss and Annoy.
NLTK and TextBlob.
Answer
The correct answer is 4.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.