2.17 Question Answering
Contents
2.17 Question Answering#
In this lesson, we see a branch of NLP dedicated to answering questions using contextual information, usually in the form of documents.
What is Question Answering#
Question Answering (QA) models are able to retrieve the answer to a question from a given text. This is useful for searching for an answer in a document. Depending on the model used, the answer can be directly extracted from text or generated from scratch.
Question Answering Use Cases#
Question Answering models are often used to automate the response to frequently asked questions by using a knowledge base (e.g. documents) as context. As such, they are useful for smart virtual assistants, employed in customer support or for enterprise FAQ bots (i.e. directed towards enterprise employees).
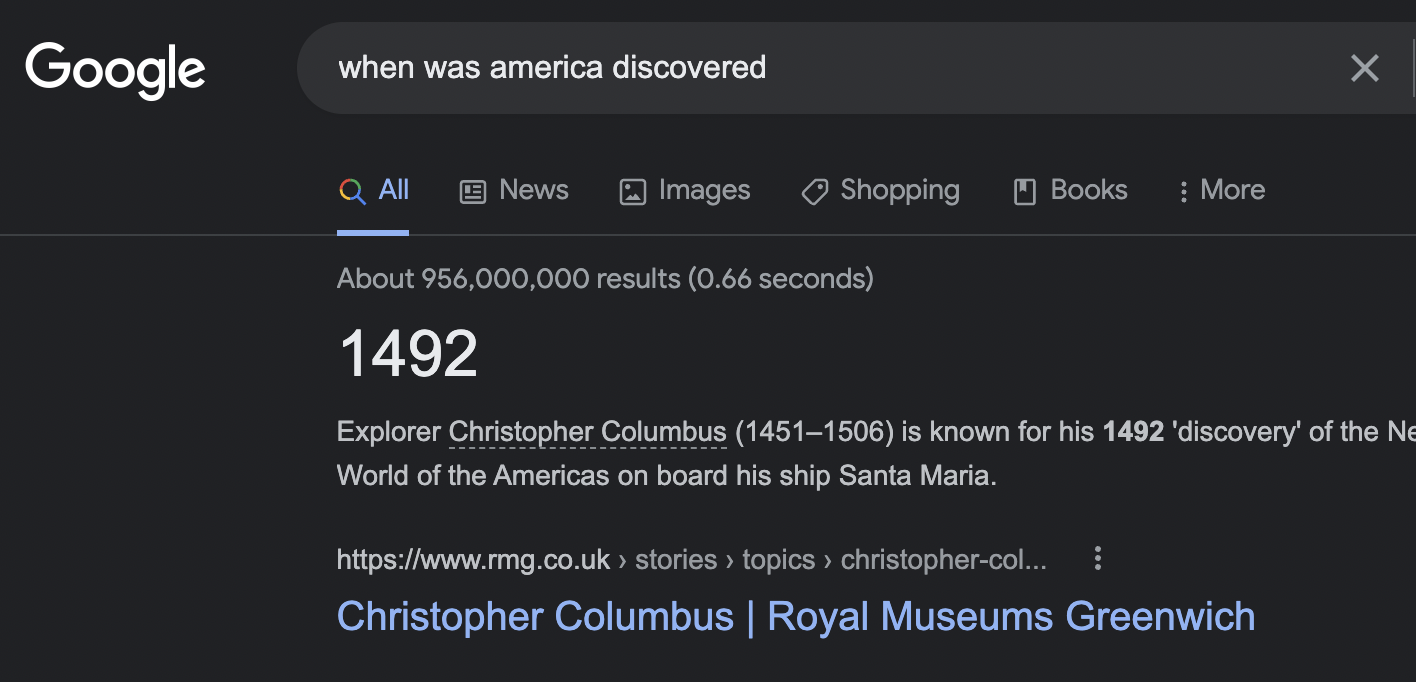
Moreover, many search systems augment their search results with instant answers, which provide the user with immediate access to information relevant to their query. Here’s an example with Google.
Question Answering Variants#
QA systems differ in the way answers are created.
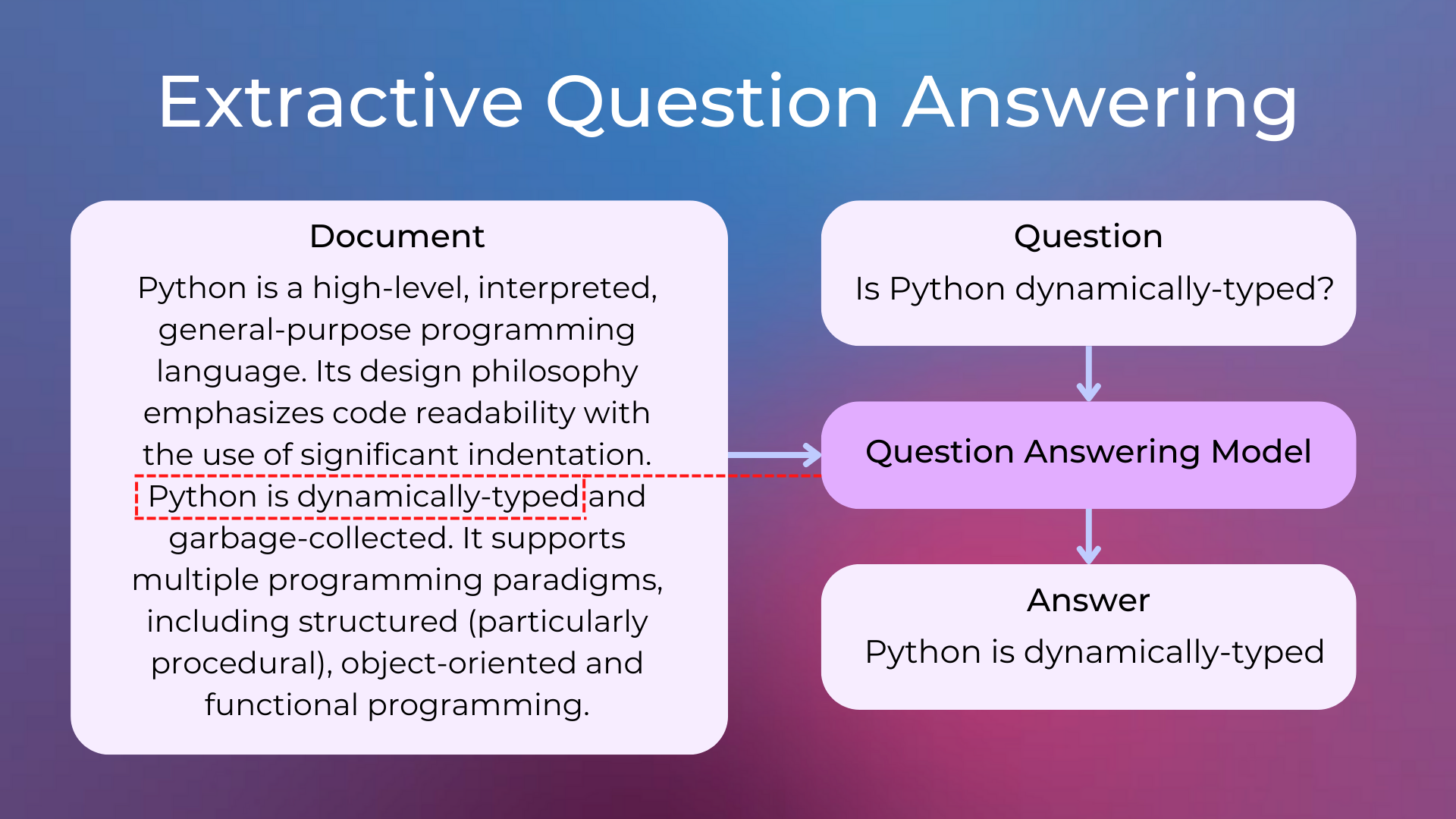
Extractive QA: The model extracts the answer from a context and provides it directly to the user. It is usually solved with BERT-like models.
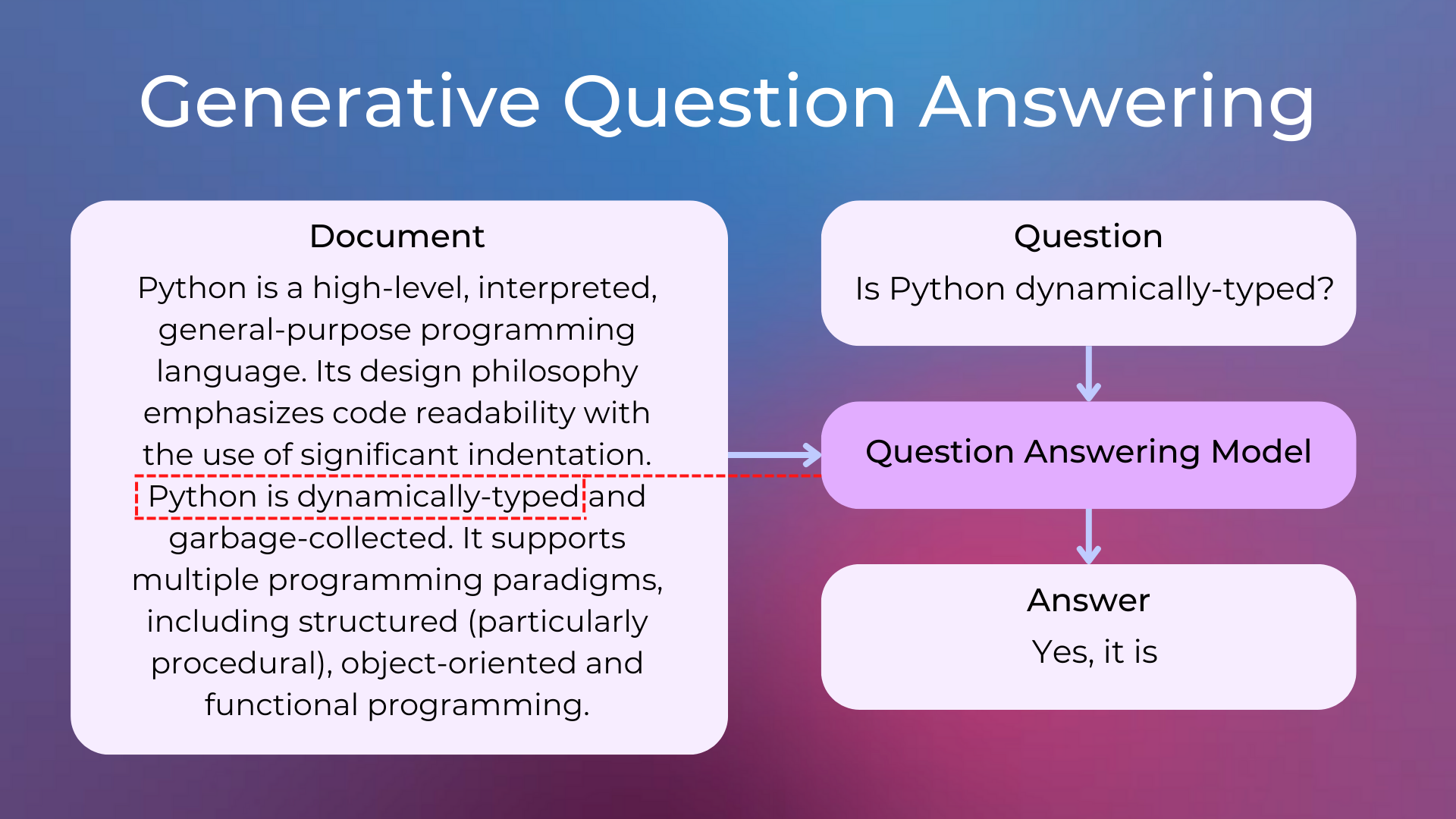
Generative QA: The model generates free text directly based on the context. It leverages Text Generation models.
Moreover, QA systems differ in where answers are taken from.
Question Answering Datasets#
The dataset that is used the most as an academic benchmark for extractive question answering is SQuAD (The Stanford Question Answering Dataset). SQuAD is a reading comprehension dataset, consisting of questions posed by crowd-workers on a set of Wikipedia articles, where the answer to every question is a segment of text from the corresponding reading passage. It contains 100,000+ question-answer pairs on 500+ articles.
There is also a harder SQuAD v2 benchmark, which includes questions that don’t have an answer. It combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowd-workers to look similar to answerable ones.
Question Answering with Python#
You can infer with QA models with the Hugging Face transformers library using the question-answering pipeline, which by default will be initialized with the distilbert-base-cased-distilled-squad model (which is a model for extractive open QA). This pipeline takes a question and a context from which the answer will be extracted and returned.
Install and Import Libraries#
First, let’s install the transformers library using pip as usual.
pip install transformers
from transformers import pipeline
Try Question Answering#
Then, we create a pipeline object with the question-answering task, and use it by providing a question and a context.
# download model
qa_model = pipeline("question-answering")
# test model
question = "Where is the ball?"
context = "The chair is near the table, and the ball is behind the chair."
qa_response = qa_model(question = question, context = context)
print(qa_response)
{'score': 0.8110507726669312, 'start': 45, 'end': 61, 'answer': 'behind the chair'}
The model returns a dictionary containing the keys:
answer: The text extracted from the context, which should contain the answer.start: The index of the character in the context that corresponds to the start of the extracted answer.end: The index of the character in the context that corresponds to the end of the extracted answer.score: The confidence of the model in extracting the answer from the context.
Let’s try the model with a little more complex text from the Python Wikipedia page.
context = "Python is a high-level, general-purpose programming language. Its design " \
"philosophy emphasizes code readability with the use of significant indentation. " \
"Python is dynamically typed and garbage-collected. It supports multiple programming " \
"paradigms, including structured (particularly procedural), object-oriented and " \
"functional programming. It is often described as a \"batteries included\" language " \
"due to its comprehensive standard library."
question = "What does the Python design emphasize?"
qa_response = qa_model(question = question, context = context)
print(qa_response)
{'score': 0.7124277353286743, 'start': 95, 'end': 111, 'answer': 'code readability'}
Fast Question Answering over Many Documents#
Running the QA model over many documents can be slow. To speed up the search, you can first use passage ranking models to see which documents might contain the answer to the question and iterate over them with the QA model.
Code Exercises#
Quiz#
What’s the job of question answering models?
Extracting information from large unstructured datasets.
Automatically generating natural language questions related to a text.
Automatically finding answers to questions posed in natural language.
Answer
The correct answer is 3.
True or False. Many search systems augment their search results with instant answers.
Answer
The correct answer is True.
How are question answering systems usually categorized?
Extractive vs Generative, and Open vs Close.
Rule-based vs Statistical, and Syntactic vs Semantic.
Knowledge-based vs Corpus-based, and Extractive vs Generative.
Answer
The correct answer is 1.
What’s the difference between SQuAD v1 and SQuAD v2?
SQuAD v2 includes a context paragraph for each question.
SQuAD v2 contains also unanswerable questions.
SQuAD v2 includes a confidence score for each answer.
Answer
The correct answer is 2.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.