1.2 What Tasks Can I Solve with NLP Today?
Contents
1.2 What Tasks Can I Solve with NLP Today?#
Let’s go into more detail and see a rather comprehensive list of tasks that NLP can solve today. Later in the course we will see how to use open-source models to solve these problems in a few lines of code, and how to refine these models for our specific use cases.
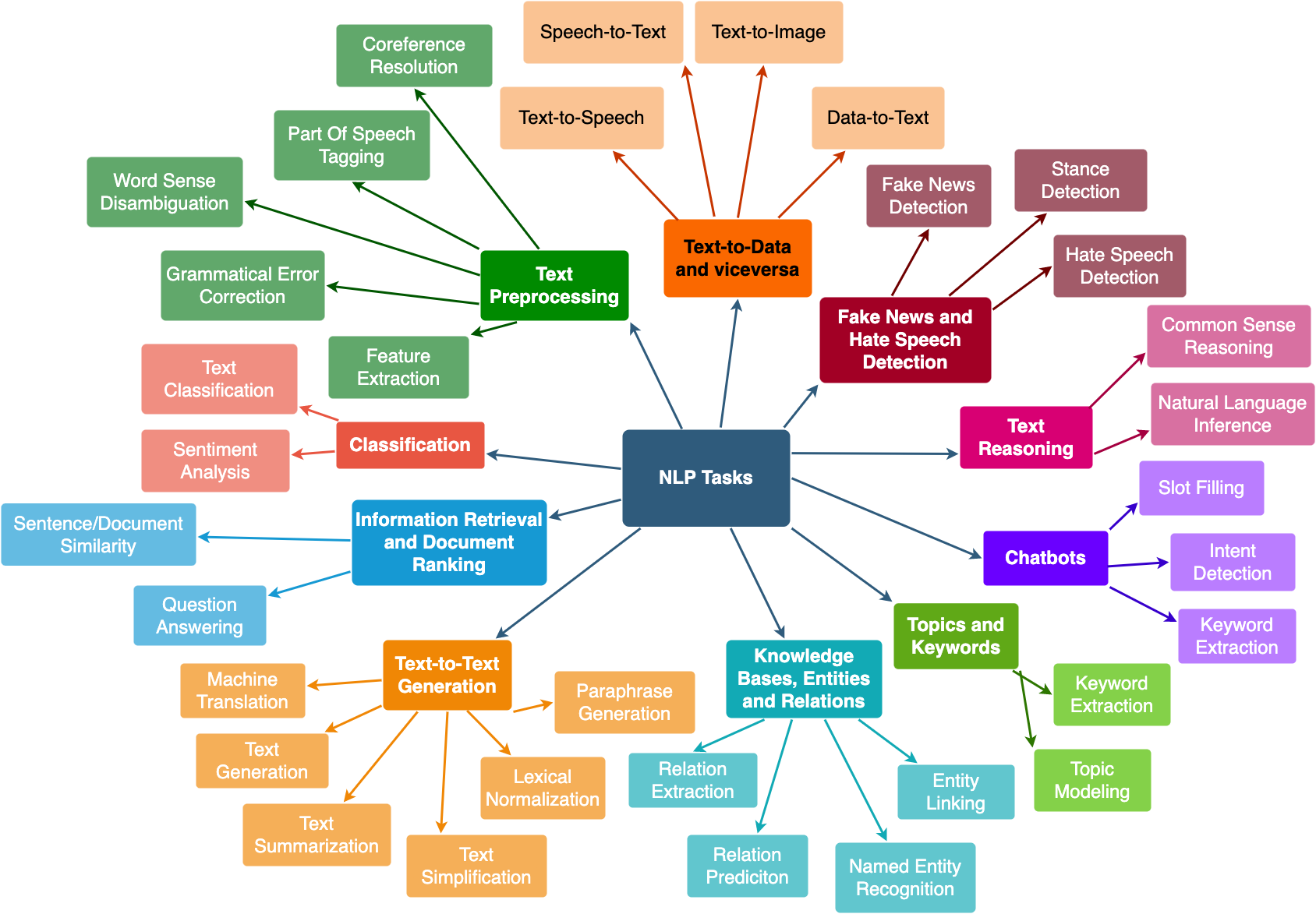
Text Classification#
Text classification is the task of automatically assigning a text document to one or more pre-defined categories (a.k.a. classes), based on its content.
Some examples are:
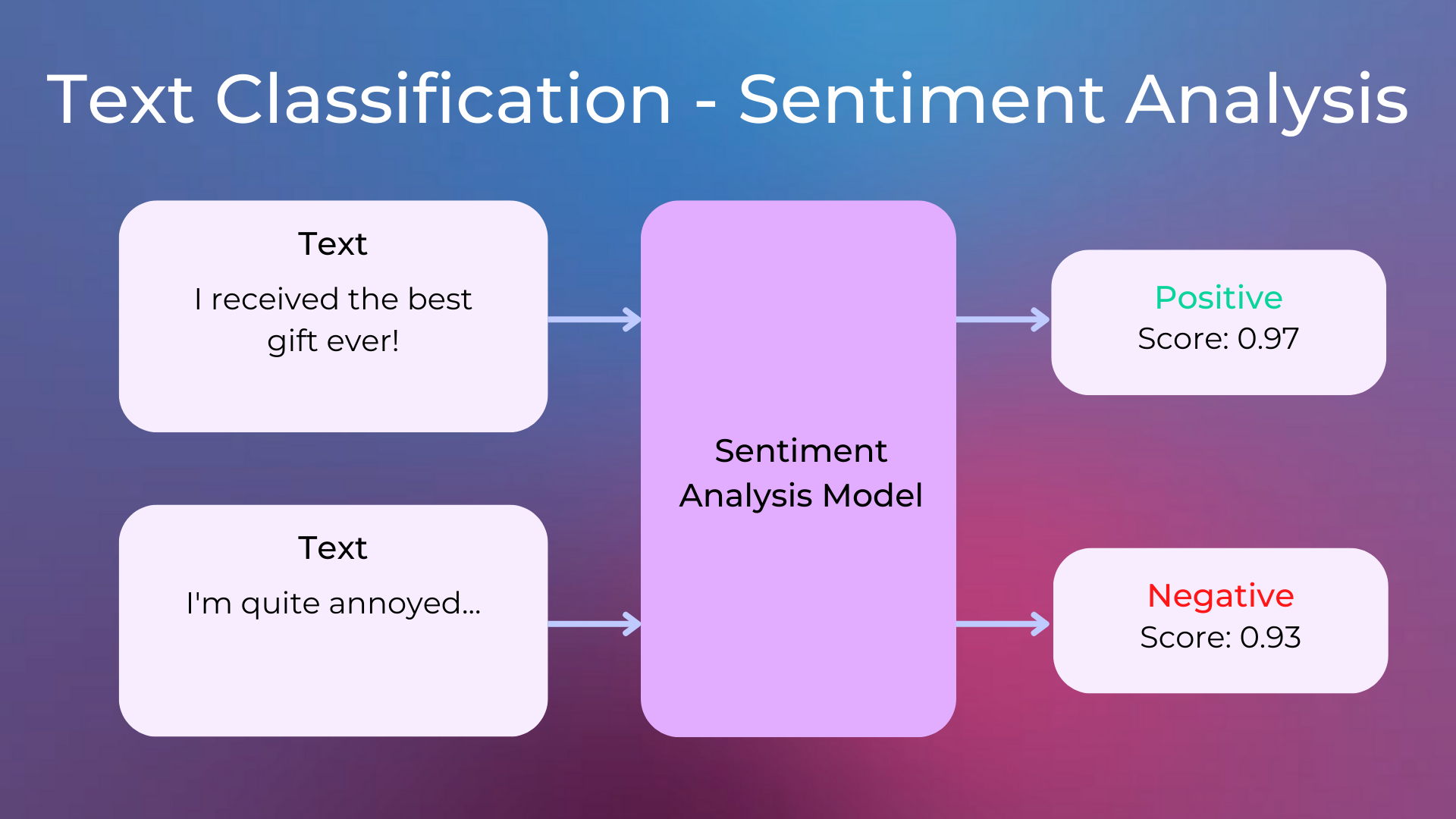
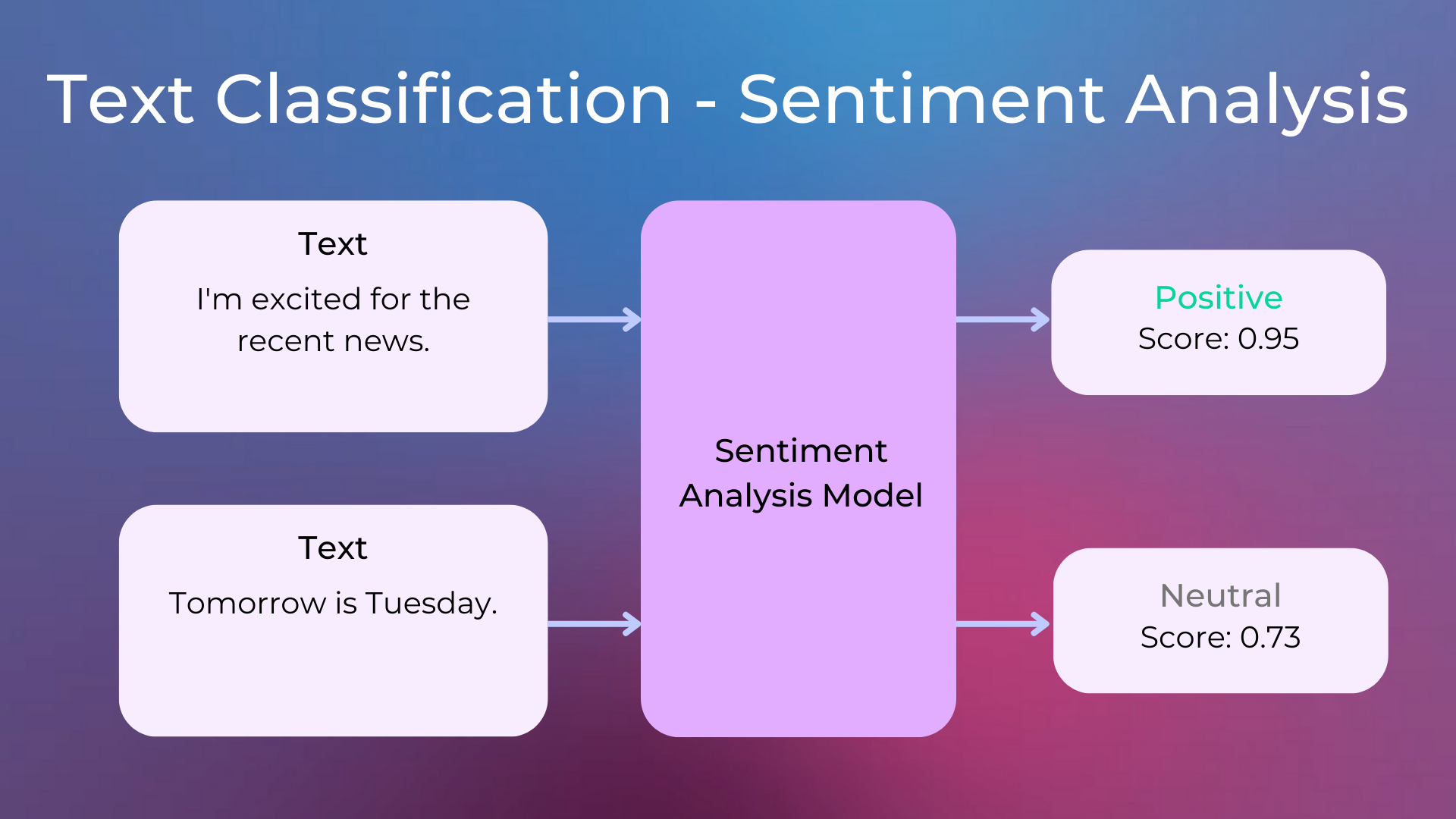
Sentiment Analysis: Understanding whether a text has a positive sentiment (e.g. “the dinner was nice”) or a negative sentiment (e.g. “the dinner was awful”). It’s mainly used to understand whether customers are happy or unhappy about a company, a product, or a service.
Spam Detection: Moving the right emails into the spam folders.
Assigning categories to CRM customer support tickets: Detecting the type of a ticket (e.g. refund or technical problem) and dispatching it automatically to the correct customer support person.
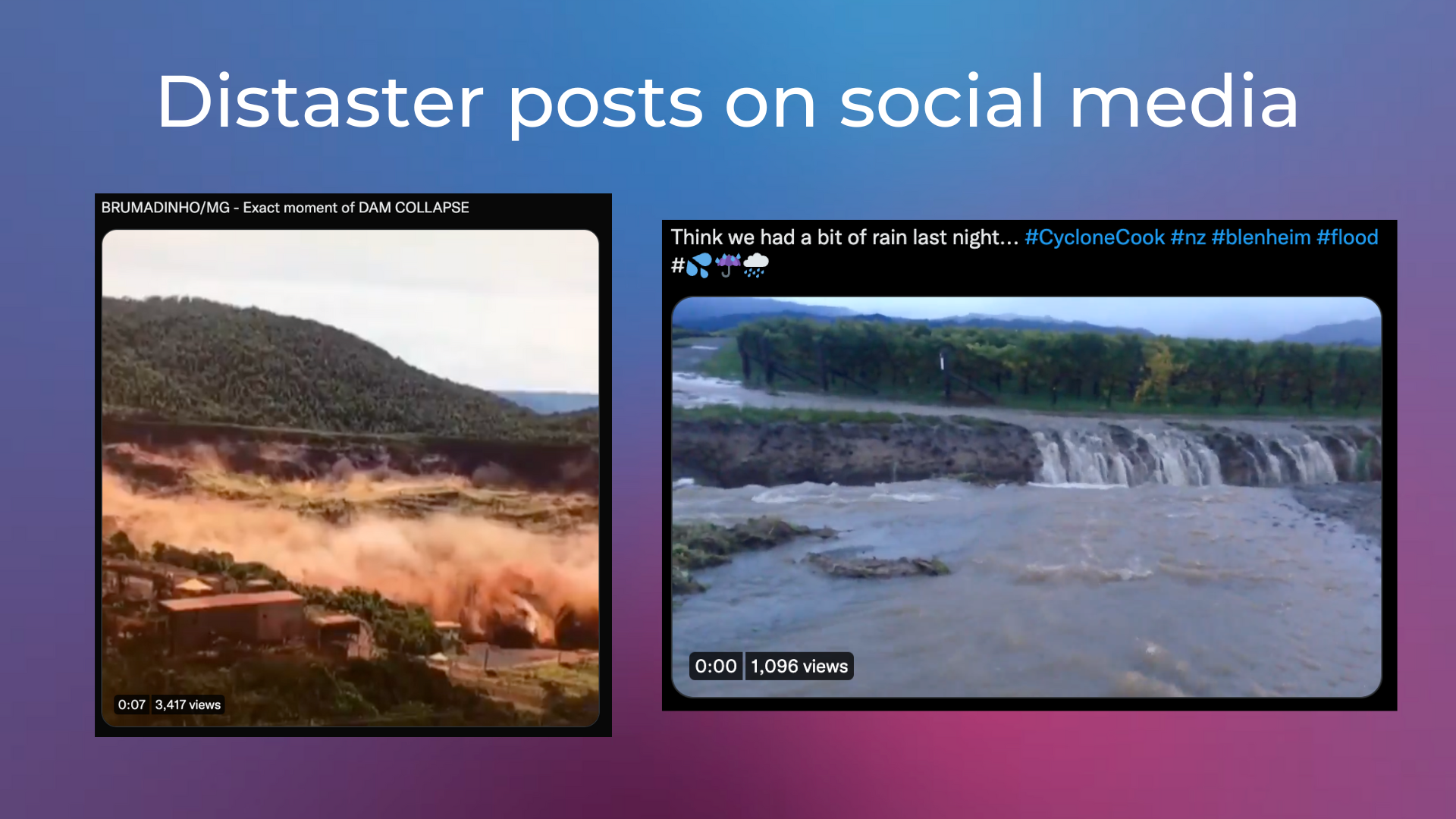
Classification of disaster conversations on social media: Detecting disasters like fires or floods from social media posts (e.g. tweets).
Information Retrieval and Semantic Search#
Information retrieval (IR) is focused on understanding the user’s intent (typically expressed with a query) and providing the most relevant results. Searches can be based on full-text or metadata searches.
Traditional information retrieval systems work by (1) efficiently matching texts between queries and documents, and (2) assigning different importance to different words in a smart way.
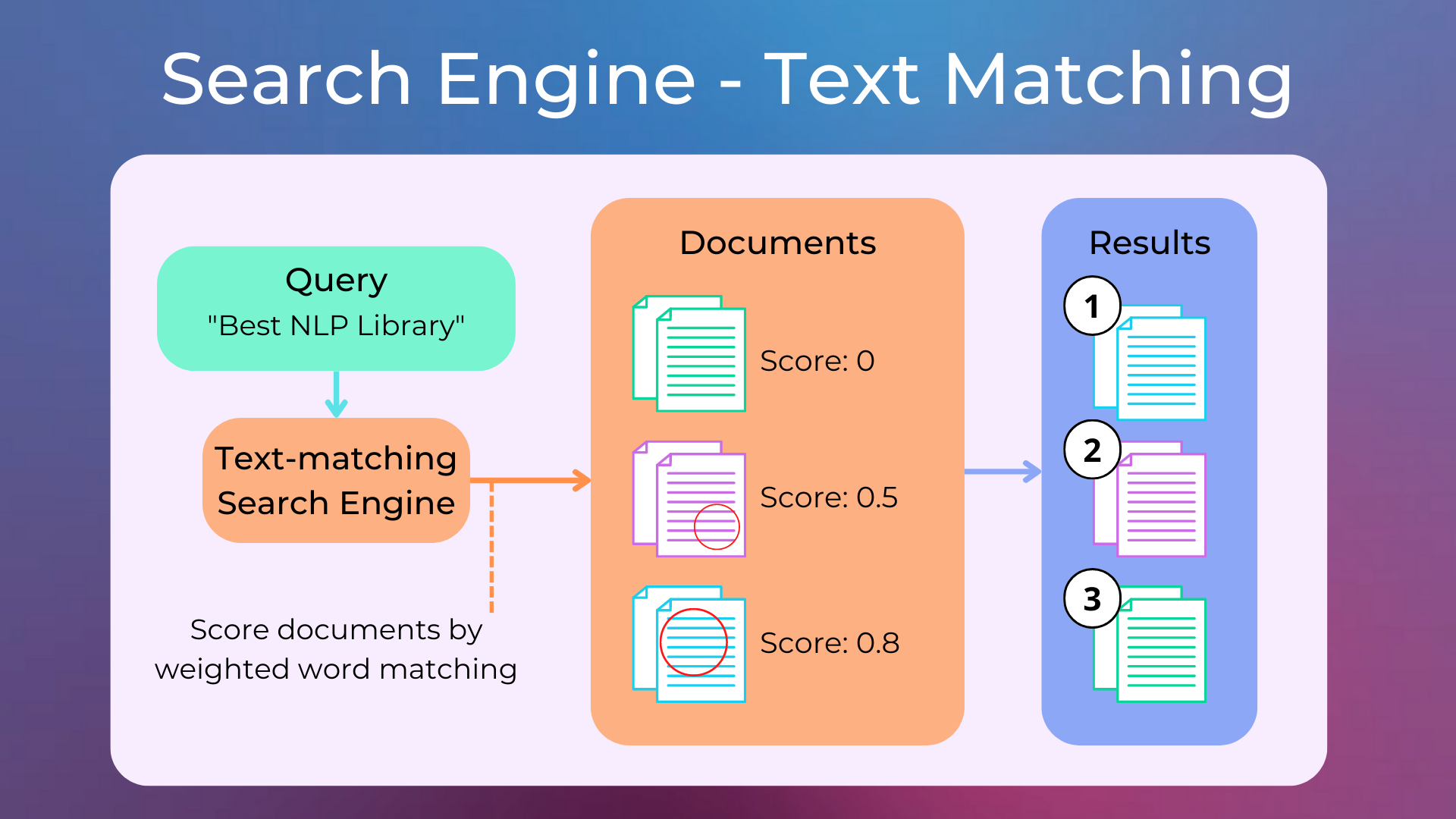
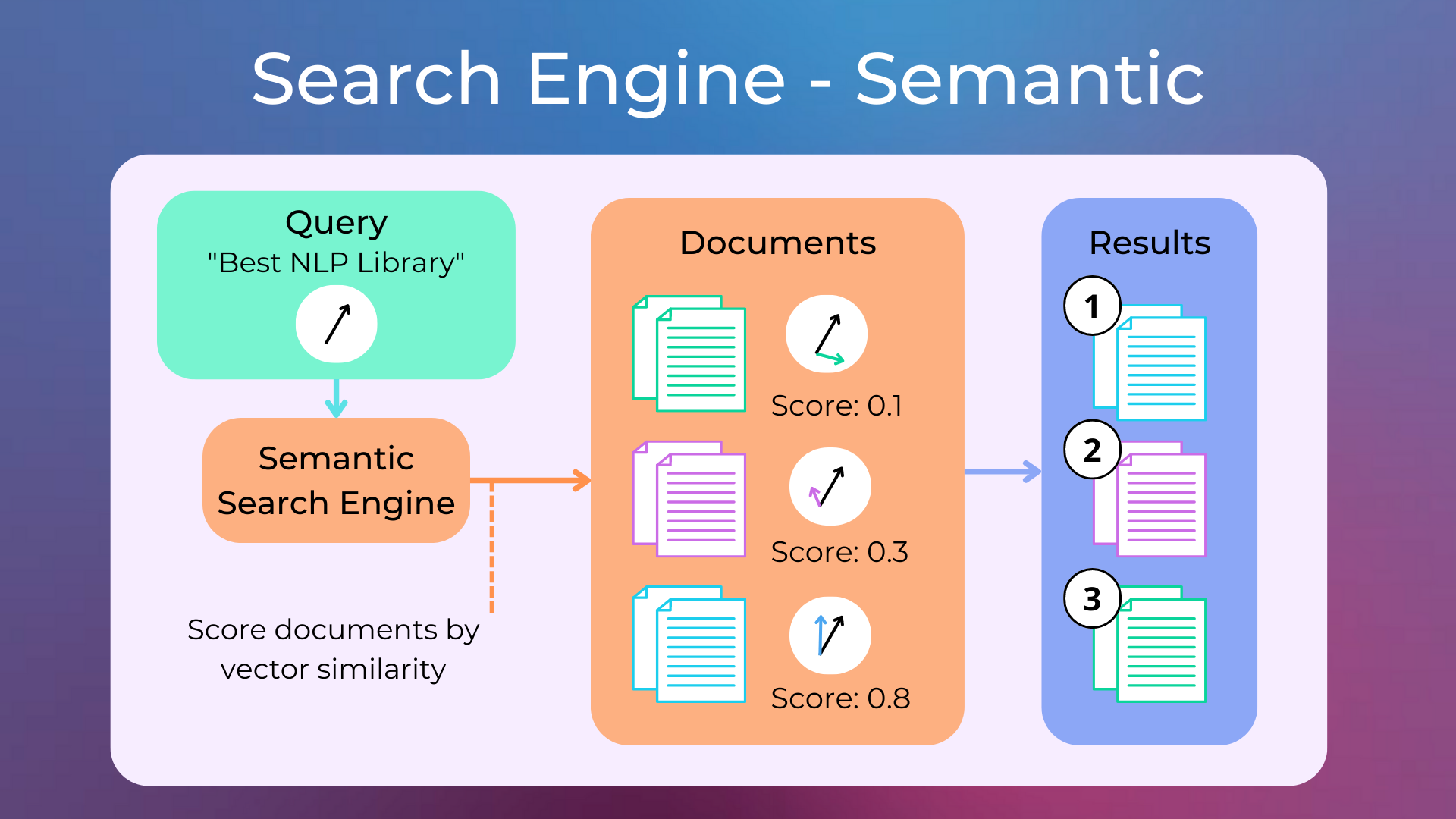
Semantic search is related to information retrieval in that it is concerned with finding the best match for a user’s query, but it goes beyond traditional IR techniques by considering the semantic meaning of the queries and the documents. They typically work with word embeddings.
Recommender Systems#
A recommender system is typically used to recommend items to users based on their past behavior, such as products to be purchased in retail. A recommender system working with NLP would recommend, for example, articles similar to the ones the user has read in the past.
Text Summarization#
Text summarization is the process of generating a short, accurate, and representative summary of a longer text document. The goal of text summarization is to create a condensed version of the original document that captures its essential information while being significantly shorter.
Question Answering#
Question Answering (QA) is focused on techniques to automatically answer questions posed in natural language.
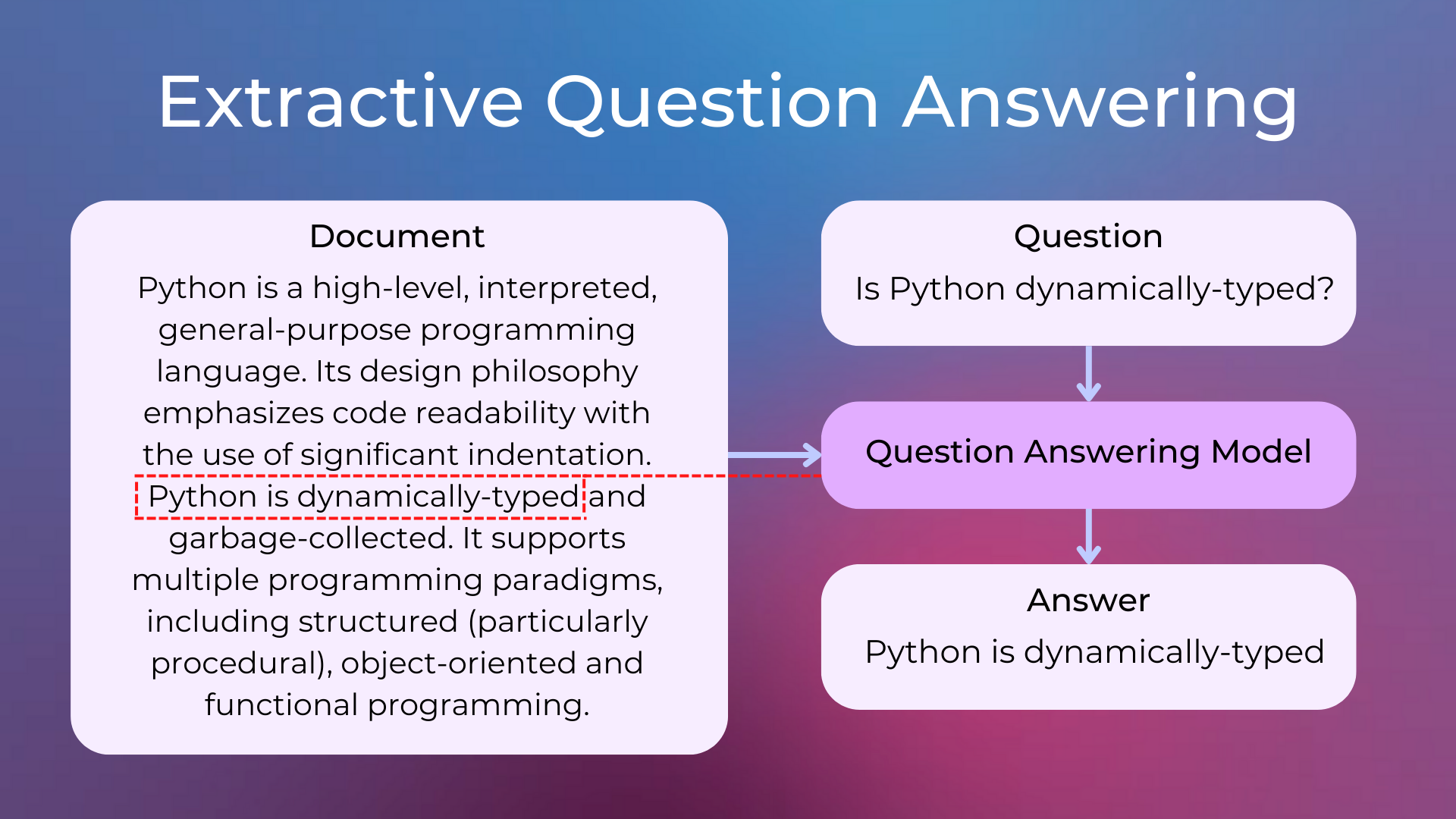
Broadly speaking, there are two types of QA systems: extractive and generative.
Extractive Question Answering takes a question as input and retrieves the most relevant answer from a large database of potential answers (or directly from a text as context).
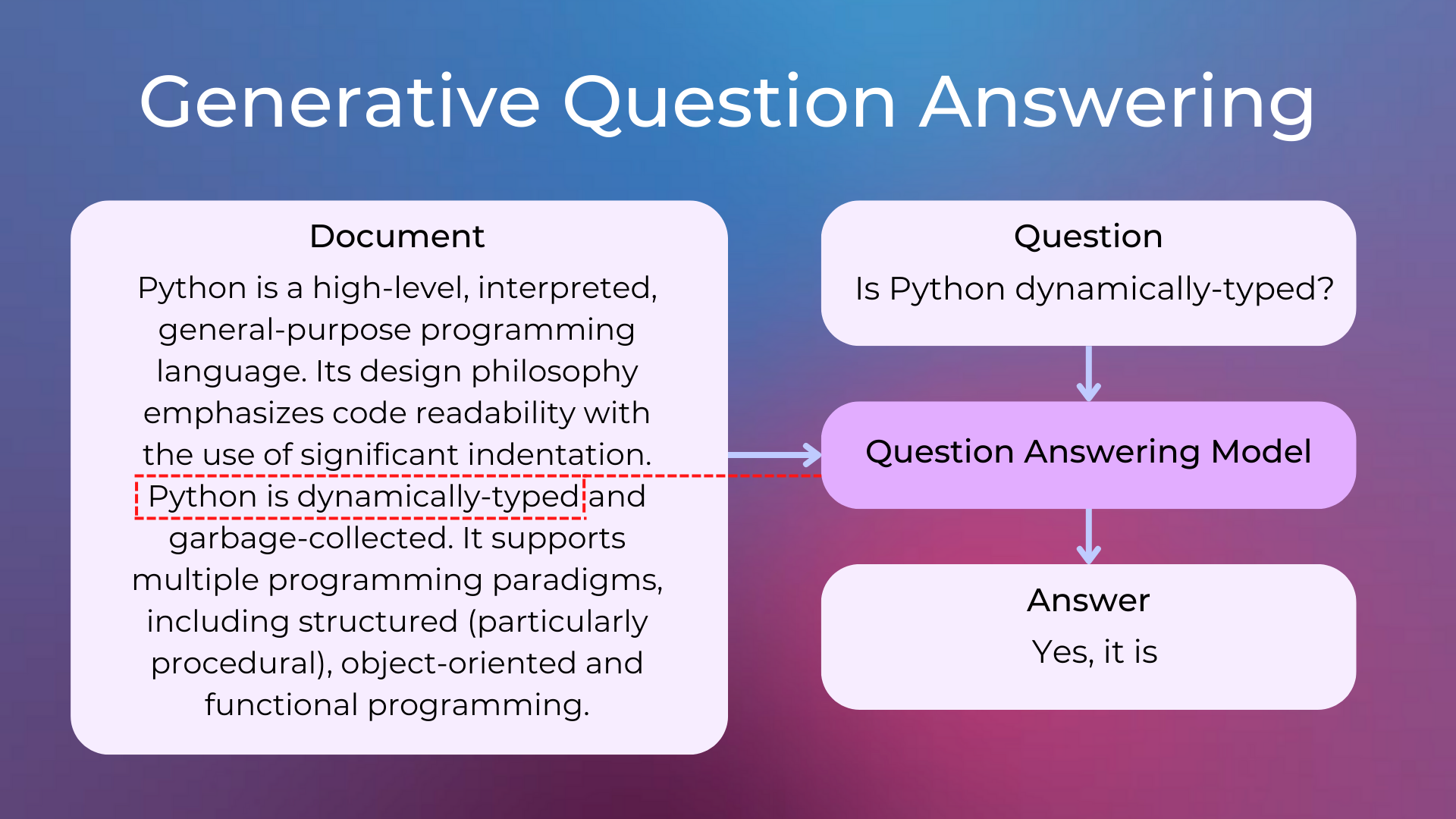
Generative Question Answering, on the other hand, generates an answer from scratch based on the question and sometimes also on additional context information.
Named-Entity Recognition#
Named-Entity Recognition (NER) is a subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
NER systems typically use a combination of machine learning and rule-based methods to identify named entities in text. While machine learning methods can be used to automatically learn patterns from annotated training data, rule-based methods use manually crafted rules to identify named entities.

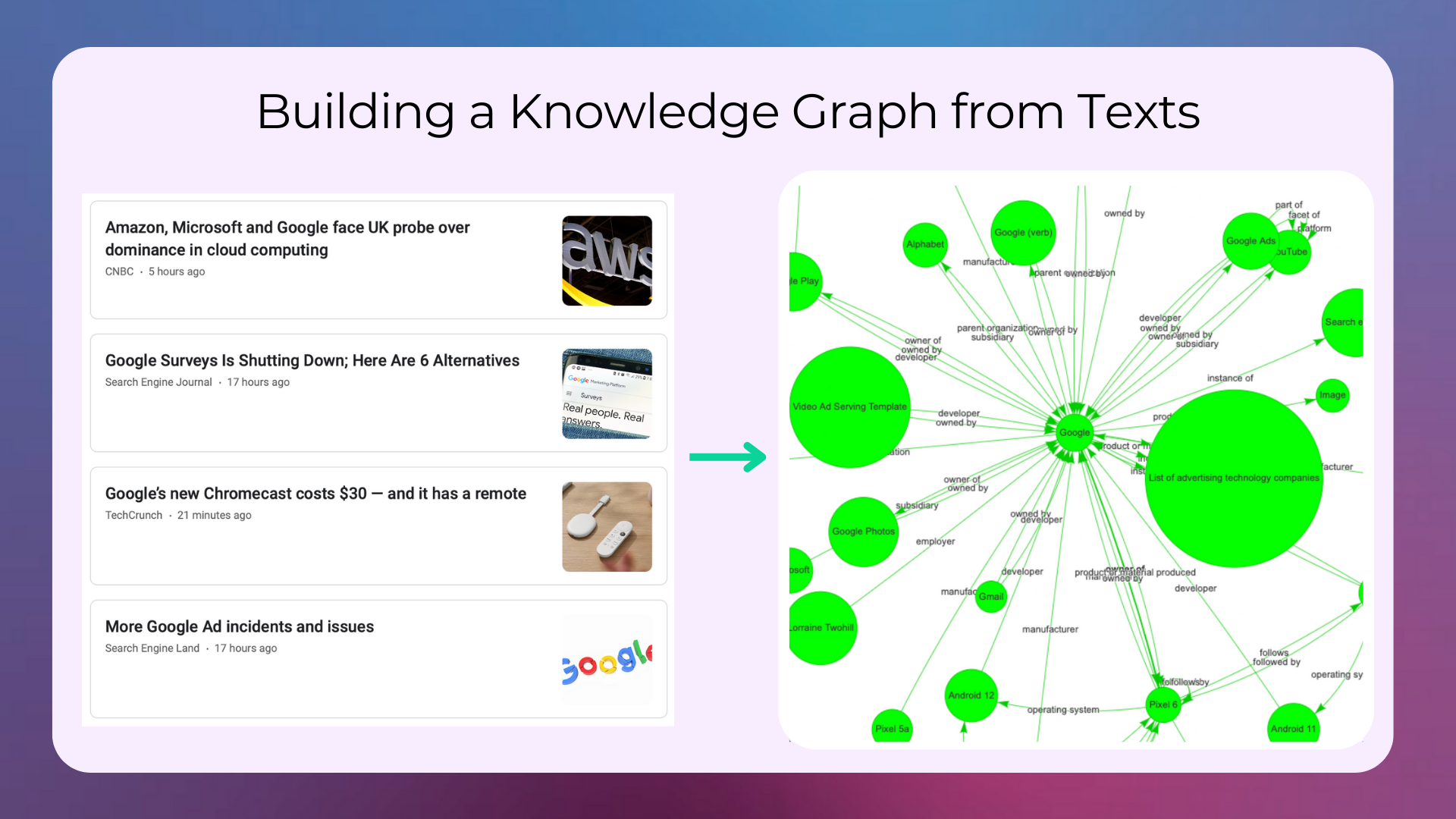
Knowledge Graphs#
A Knowledge Graph is a data structure that stores information in the form of a graph. The nodes in the graph represent entities, and the edges represent relationships between those entities. Knowledge graphs are used in a variety of applications, including search engines, question answering systems, and recommender systems.
One of the most well-known knowledge graphs is the Google Knowledge Graph, which was launched in 2012. The Google Knowledge Graph contains billions of entities and trillions of edges, and is used to power features such as the “People also search for” and “Related searches” boxes that appear on the right-hand side of the search results page.
Machine Translation#
Machine Translation (MT) is the process of translating text or speech from one language to another. It was the first task of historical interest for NLP. First approached in the 1950s, today it has made great strides thanks to deep learning.
Keyword and Keyphrase Extraction#
Keyword and Keyphrase Extraction is the task of automatically identifying the most important words and phrases in a document. It’s currently tackled with graph-based models, statistical models, and word embeddings.
Text Generation#
Text Generation is the task of automatically generating natural language text similar to those produced by humans. The generation of texts has become so accurate in recent years that it is difficult to distinguish from those written by humans in some cases.

Fake News Detection and Text Generation
As text generation models became better, there’s been efforts in monitoring whether such technologies are going to be used to mass-produce fake news articles, influencing the people’s opinions on important topics (e.g. politics). Up to now there’s few evidence of it, but the threat will increase as the models become better and better.
Chatbots and Personal Assistants#
Chatbots and Personal Assistants are computer programs that are designed to simulate human conversation, while also helping users in doing tasks. They are commonly used in online customer service to answer simple questions or requests.
Speech-to-Text and Text-to-Speech#
In Speech-to-Text (STT), also called Automatic Speech Recognition (ASR), the computer listens to a person speaking and converts the sounds into written words. In Text-to-Speech (TTS), the computer reads written text and converts it into spoken words.
Both speech-to-text and text-to-speech have a variety of applications. They can be used to create text documents from audio recordings, generate audio files from text, create subtitles for videos, and provide accessibility for people with disabilities.
Speech-to-text and text-to-speech technology is constantly improving, and it is now possible to create high-quality audio files that sound natural and realistic.
Text-to-Speech Examples
Open this link to listen to machine-generated speech with different voices and tones of voice. They have been generated with the TorToiSe open-source TTS model.
Text-to-Speech and Voice Cloning
Today there are text-to-speech models able to produce audio that resembles the voice of a specific person, thus doing voice cloning. As for all technologies, there are good and bad uses of it. Learn more by reading The Rise Of Voice Cloning And DeepFakes In The Disinformation Wars.
Image Search#
Image Search is the process of searching for images based on their visual content and using textual queries. It’s a multimodal task as it concerns data in different modalities: text and image.
Nowadays, image-based search engines are developed somewhat similar to semantic text-based search engines:
All the images are embedded and represented as vectors.
The query is embedded as well.
The best results are the images with the highest vector similarity to the query.

Quiz#
Select the example that is not about text classification.
Detecting the language of a text.
Classifying a tweet as containing or not containing obscene text.
Translating a sentence from English to Italian.
Labeling a Git issue as “Improvement proposal”.
Answer
The correct answer is 3.
Explanations:
It’s a text classification problem where each language is a separate class.
It’s a text classification problem with the class “obscene”.
The problem consists in transforming a text into another text, i.e. it’s a text-to-text problem.
It’s a text classification problem with the class “Improvement proposal”.
Select the example that is not about text classification.
Getting the most similar document to my search query.
Detecting spam emails.
Categorizing news articles into a known taxonomy of categories.
Automatically filtering tweets about climate disasters.
Answer
The correct answer is 1.
Explanations:
In this problem, we need to rank a collection of documents according to semantic relevance with the search query. It’s a text ranking problem.
It’s a text classification problem with the class “spam”.
This is a little tricky but it’s still a text classification problem where each category is a separate class. There can be some “taxonomy logic” implemented, e.g. automatically classifying an article with “Artificial Intelligence” if the model predicted the category “Machine Learning”.
It’s a text classification problem with the class “is about climate disaster”.
Choose the option that best describes the goal of a semantic search engine.
Matching words in the queries with words in the documents semantically by assigning appropriate weights to words.
Retrieving and ranking all types of documents (texts, images, etc) that are relevant to a query.
Looking for the documents most relevant to a query, going beyond text-matching and taking semantics into account (typically with word embeddings).
Answer
The correct answer is 3.
What are two common types of Question Answering models?
Extractive and Generative.
Generative and Multimodal.
Chatbot-based and Personal Assistant-based.
Answer
The correct answer is 1.
What’s the name of the depicted NLP task?
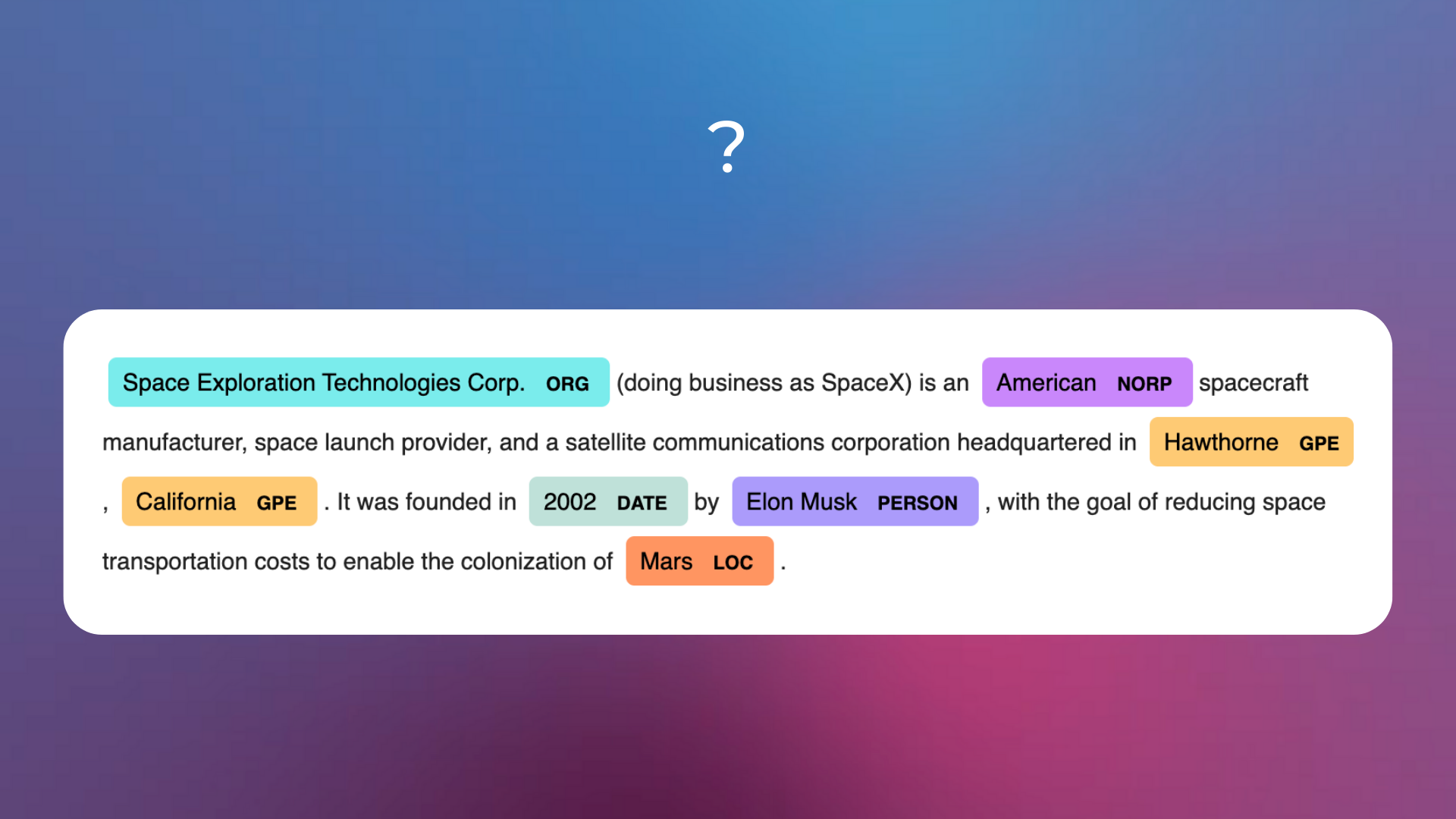
Relation Extraction.
Named-Entity Recognition.
Keyword and Keyphrases Extraction.
Answer
The correct answer is 2.
What do nodes and edges in a Knowledge Graph typically represent?
Nodes represent relationships, and edges represent entities.
Nodes represent words, and edges represent semantic relationships between the words.
Nodes represent entities, and edges represent relationships between the entities.
Answer
The correct answer is 3.
What are two possible names of the task that transcribes speech into text? (2 correct answers)
Automatic Speech Transcription.
Speech-to-Text.
Automatic Speech Recognition.
Answer
The correct answers are 2 and 3.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.