3.1 Intro to Transformers and Why They Are So Used Today
Contents
3.1 Intro to Transformers and Why They Are So Used Today#
What are Transformers#
Transformers are a type of neural network architecture that has revolutionized the field of Natural Language Processing. They were introduced in the seminal paper Attention is All You Need by Vaswani et al. in 2017.
At their core, Transformers are built on the encoder-decoder architecture (we’ll see it in a later lesson). Thanks to their ability to model long-range dependencies and capture contextual information, Transformers quickly became the state-of-the-art approach for most NLP tasks, and also in other fields like computer vision and reinforcement learning.
This is how a Transformer neural network is structured.
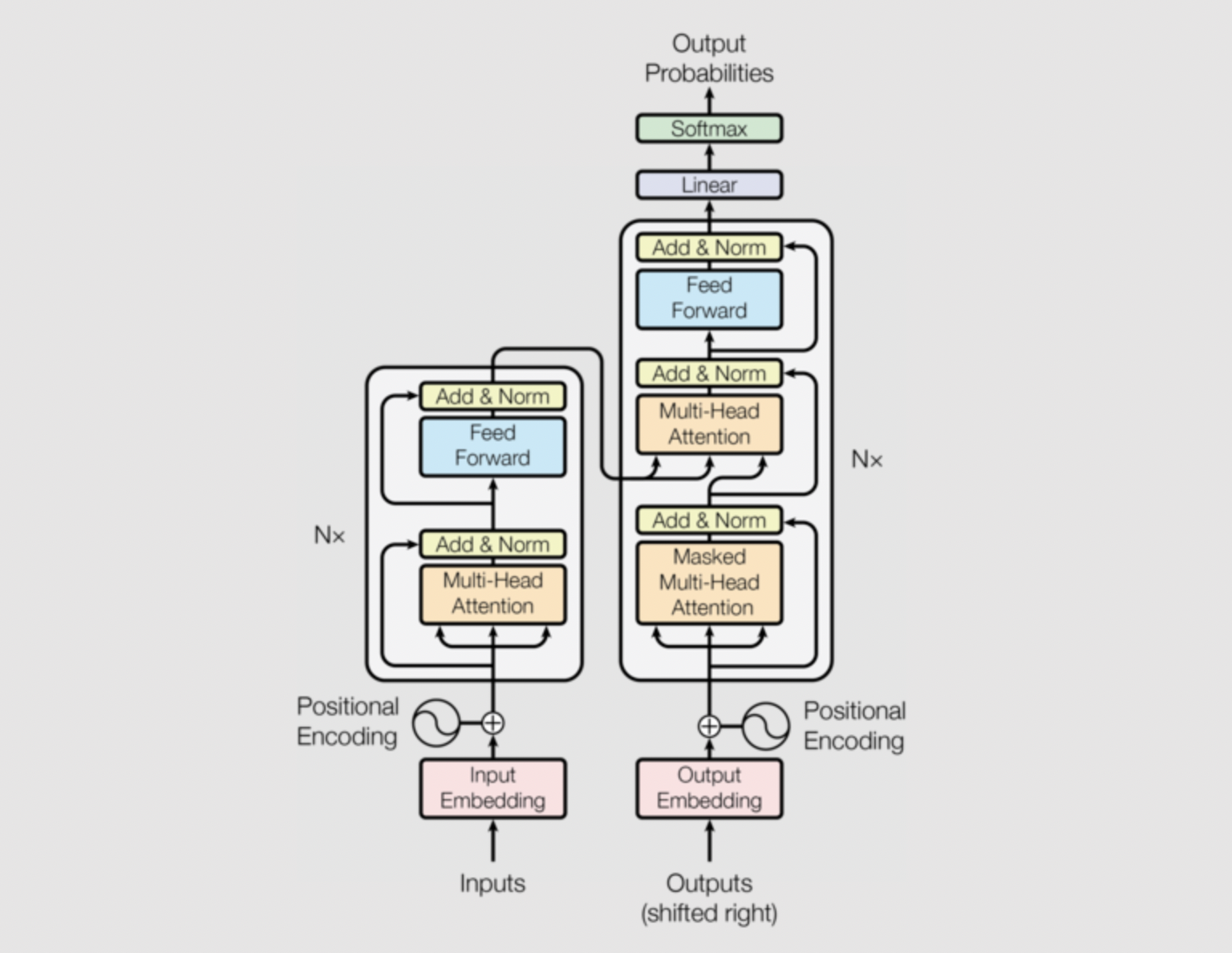
Fig. 9 Image from the paper Attention is All You Need.#
In the following lessons we’ll build an intuition of all its components. Also, consider reading the article The Illustrated Transformer and the Annotated Transformer, i.e. the “Attention is all you need” paper annotated with a PyTorch implementation by the Stanford NLP team.
For now, you can think of Transformers simply as encoder-decoder architectures:
An encoder (neural network) analyzes the input and builds an intermediate representation (a.k.a. context vector) of it;
A decoder (neural network) analyzes the intermediate representation and creates an output.
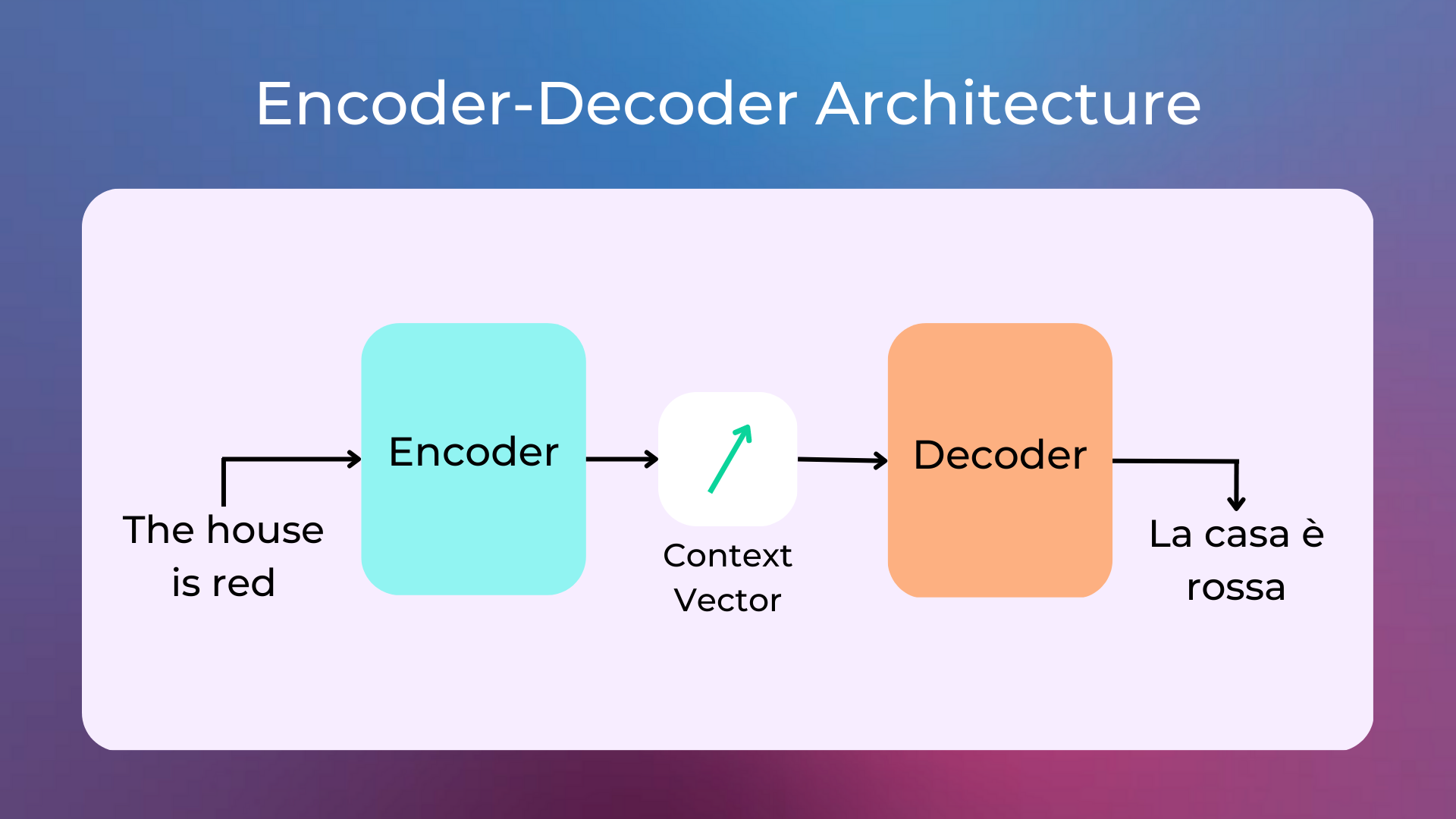
A big benefit of Transformers with respect to Recurrent Neural Networks (RNNs) is the possibility to train them with high parallelization.
Recurrent Neural Networks are a type of neural networks able to learn sequence patterns with sequences of any length, thanks to cyclic connections between their neurons.
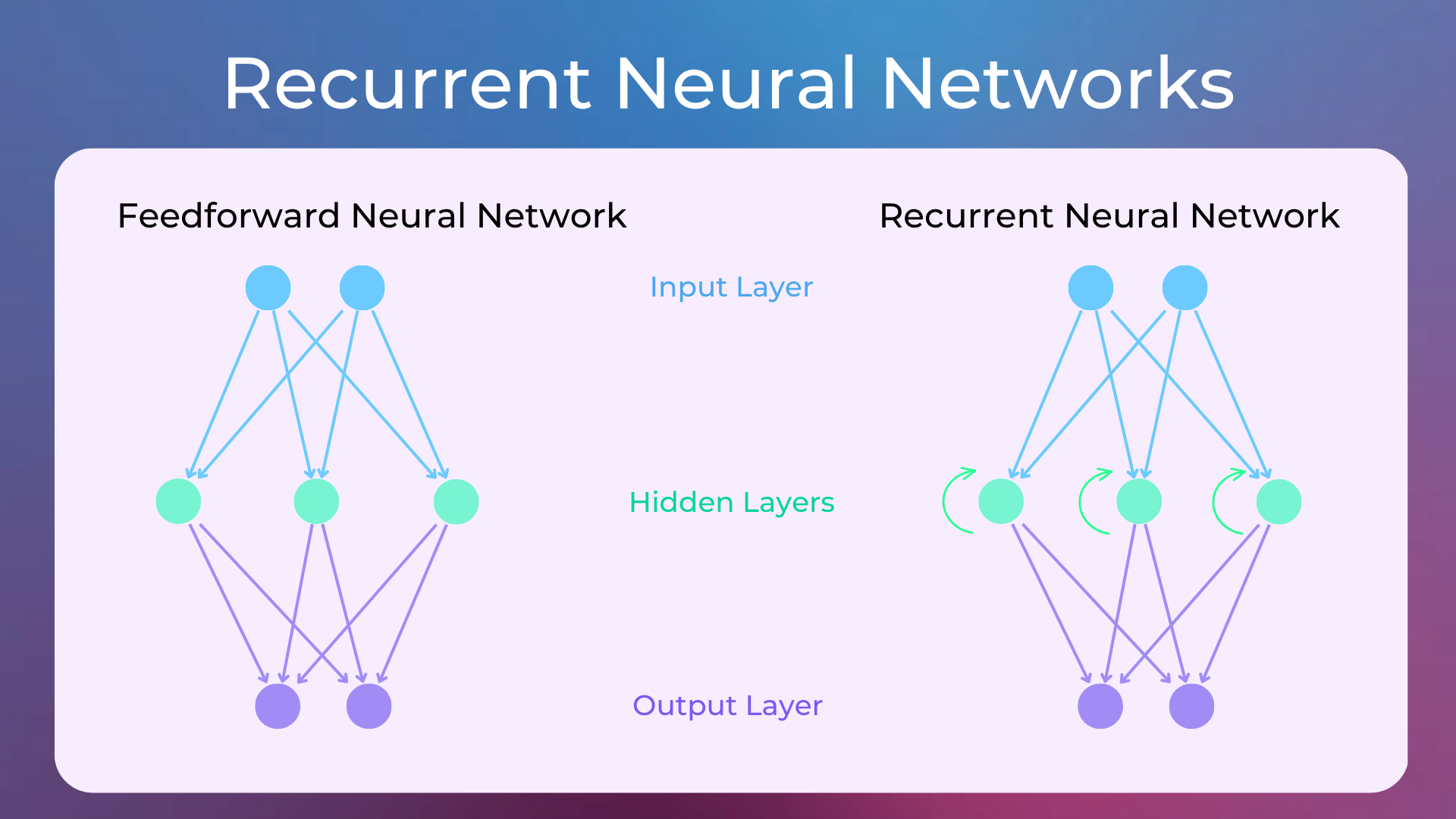
In NLP, RNNs allow computing embeddings over entire documents of any length, which is impossible with standard feedforward neural networks. RNNs later evolved with LSTM neurons to capture long-term dependencies, and to Bidirectional RNNs to capture left-to-right and right-to-left dependencies. Eventually, Encoder-Decoder RNNs emerged, where an RNN creates a document embedding (i.e. the encoder) and another RNN decodes it into text (i.e. the decoder).
Quick Intro to Attention Mechanisms#
One of the key innovations of Transformers is the attention mechanism. Attention allows the model to focus on the most relevant parts of the input sequence when generating the output. The idea of attention has been around for a while, but it was only with the introduction of Transformers that it became the dominant mechanism for most NLP tasks.
Think about the encoder-decoder architecture we introduced earlier: an encoder encodes the input into a context vector, and a decoder decodes the context vector into the output. This seems great, but empirical experience shows that a context vector is not able to remember long input sequences, as it tends to forget the earlier parts of the sequence.
The attention mechanism was born to resolve this problem: instead of using a single context-vector, multiple context-vectors are used (where each one refers to a different part of the input text, as showed in the following image) and the neural network learns which ones to use every time an output is produced.
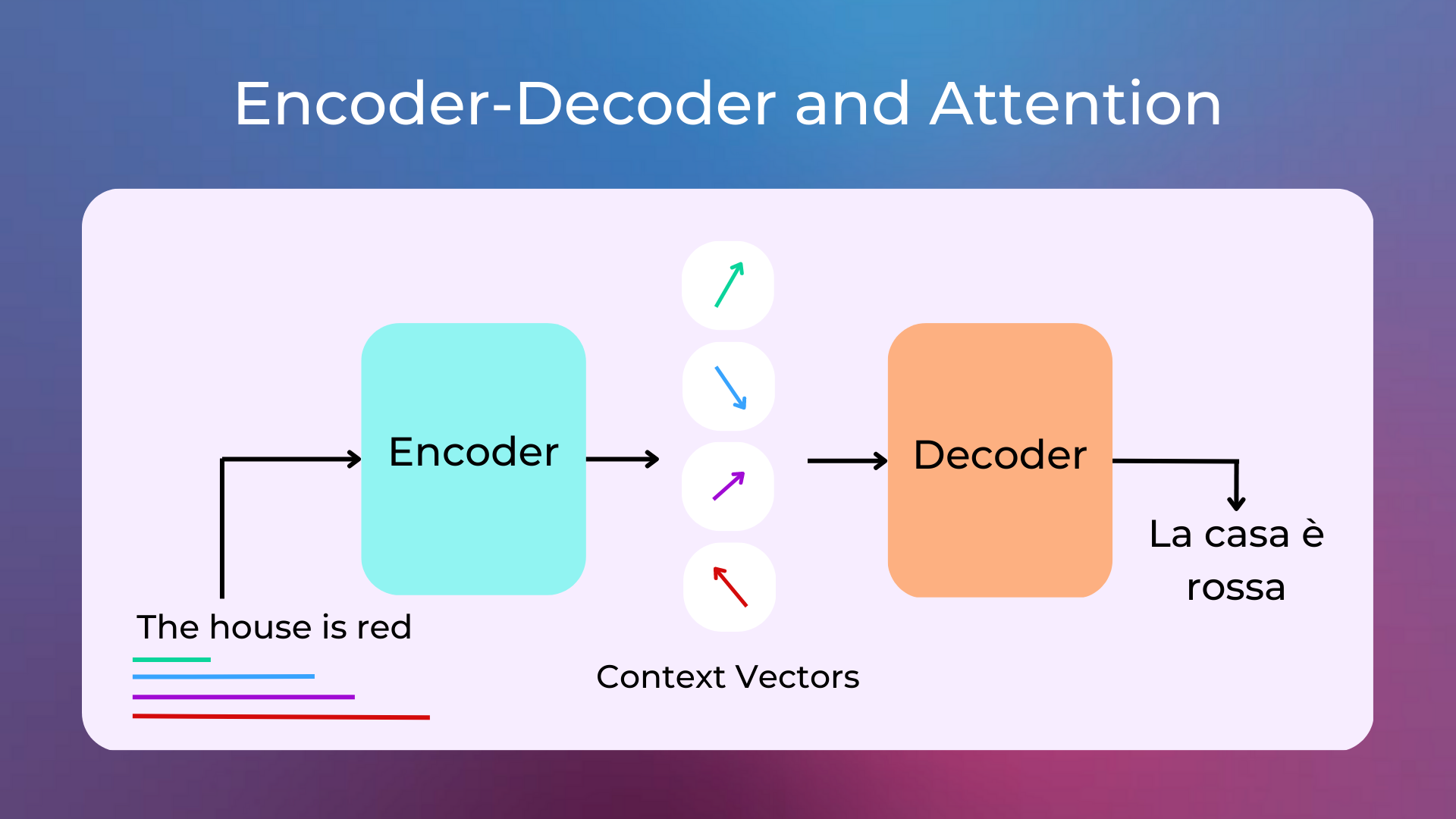
The attention mechanism also comes with a significant computational cost, which has led to the development of various approximations and optimizations to make it more efficient.
Transformers and Large Language Models#
First, transformers with 100M-1B parameters like BERT, GPT2, and T5 have been trained on a lot of self-supervised data on language modeling objectives (i.e. learning the conditional distribution of the words in the language). These models are called language models.
This first step in training language models is commonly called pre-training and feeds the model with a lot of background knowledge about language that could be useful for a variety of tasks. Then, these models are usually fine-tuned, i.e. trained for downstream specific tasks with supervised learning, like text classification. The pre-training phase is expensive and must be done only once on a lot of data, whereas fine-tuning is way cheaper and can be done on fewer samples.
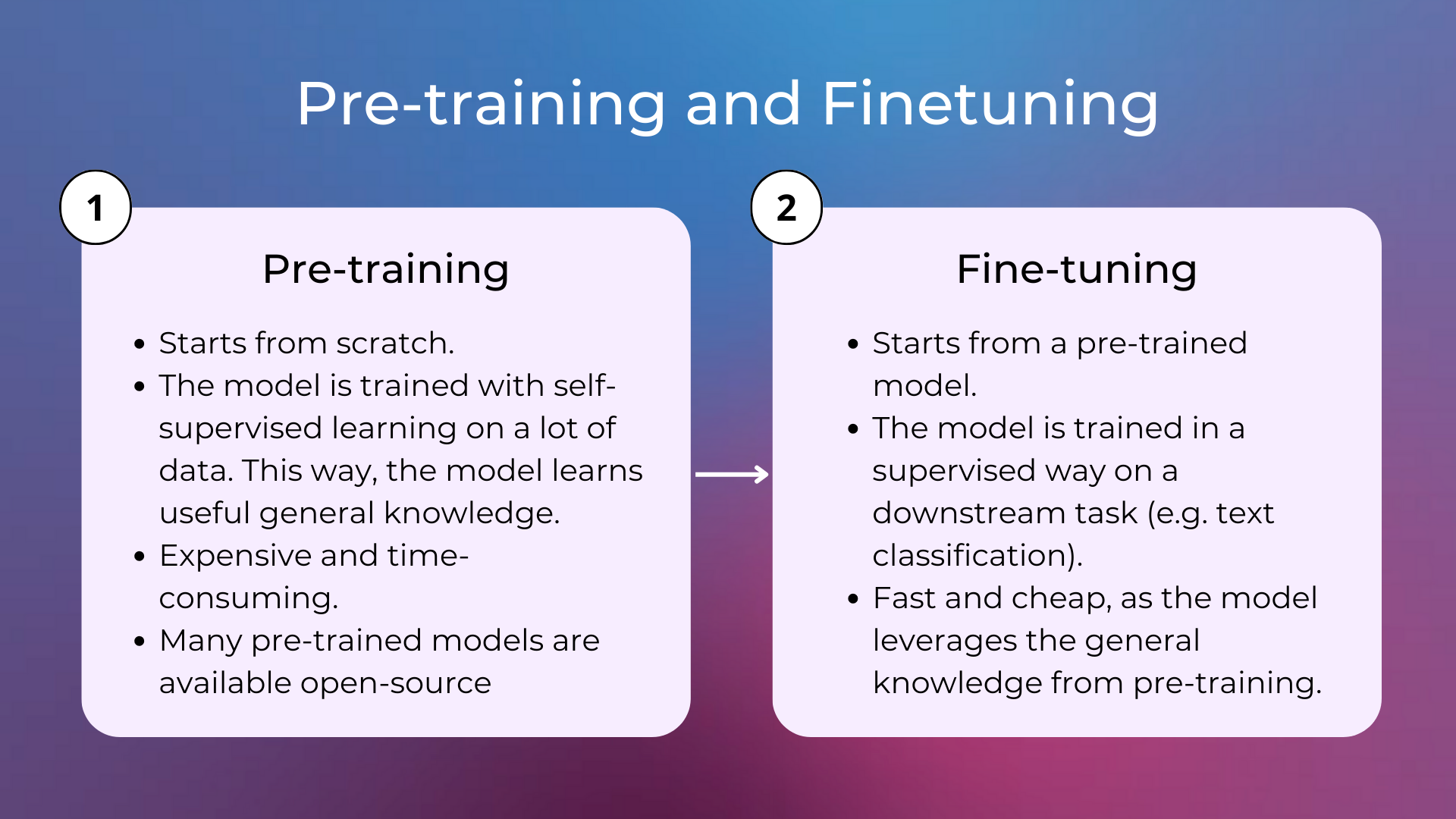
Later, experiments proved that the performance of language models could be improved simply by scaling these models, i.e. using more parameters and training on more data. With scaling only and reaching more than 100B parameters, these models learned to do tasks using few-shot or zero-shot approaches, without the need for finetuning on specific tasks. This means that these models need only the pre-training phase, and finetuning is replaced by specifying in natural language what is the expected output and eventually providing some examples. Language models with a lot of parameters today are called large language models.
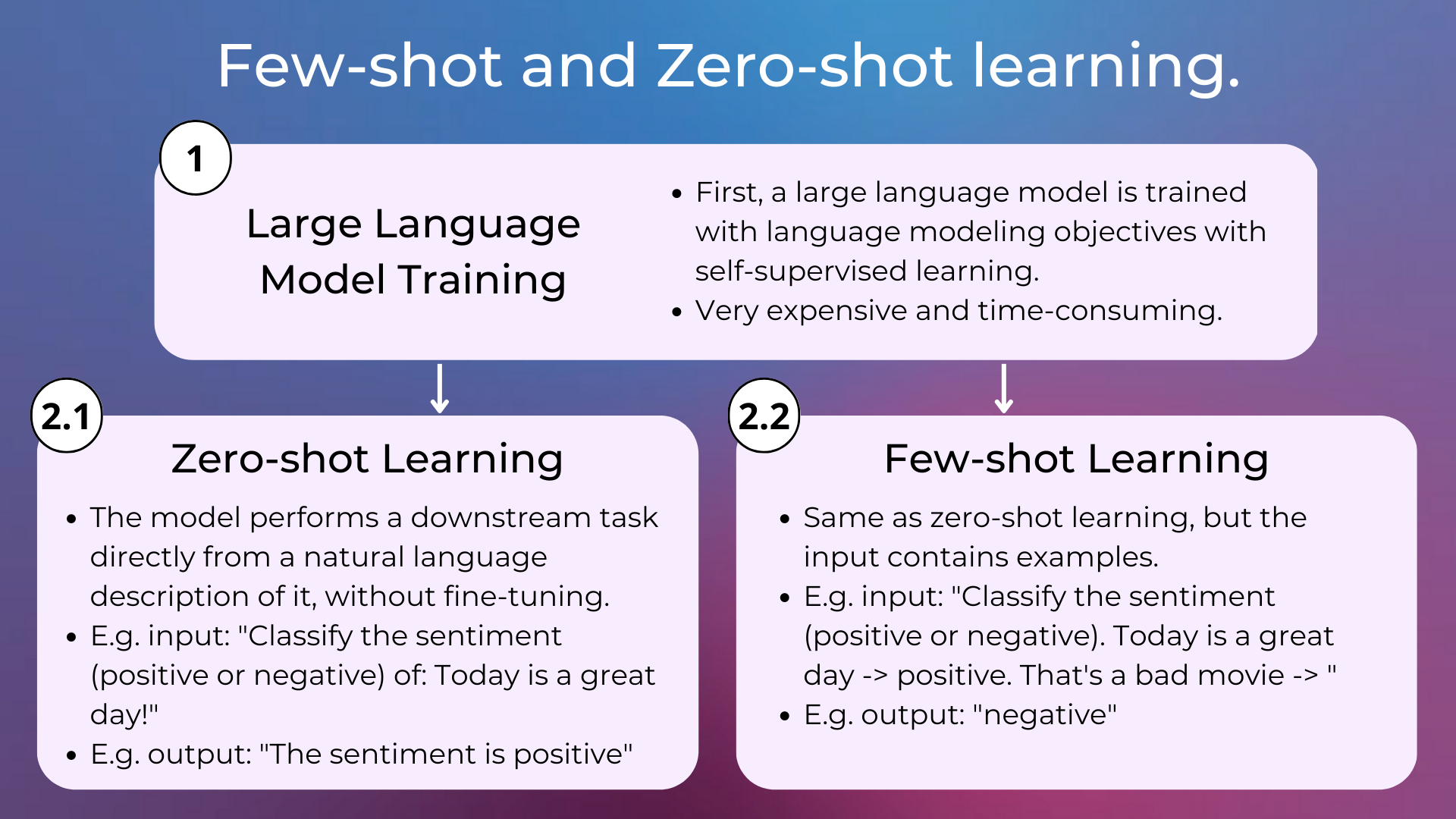
Very popular large language models are GPT-3 and ChatGPT. These models have been trained on massive amounts of text data using a self-supervised learning approach and are capable of generating human-like text, answering questions, and even carrying on a conversation with a user.
Quiz#
What’s the name of the paper that introduced Transformers?
Attention is all you need.
Encoder-decoder is all you need.
Finetuning is all you need.
Answer
The correct answer is 1.
True or False. Transformers can be used for NLP only.
Answer
The correct answer is False. Transformers are currently used in other fields as well, like computer vision and reinforcement learning.
What’s a big benefit of Transformers with respect to Recurrent Neural Networks?
Transformer training is easily parallelizable, whereas RNN training isn’t.
Transformers are faster at inference time, allowing them to be used for more tasks than RNNs.
Transformers can be pre-trained and then fine-tuned, whereas RNNs can’t.
Answer
The correct answer is 1.
What’s the goal of attention mechanisms?
Allowing for focused training, which greatly improves training times.
Allowing for focused training, which greatly improves inference times.
Allowing the model to focus on the most relevant parts of the input sequence when generating the output.
Answer
The correct answer is 3.
What’s the number of parameters typically used in large language models?
10M to 100M.
100M to 1B.
1B to 10B.
Typically +100B.
Answer
The correct answer is 4.
What’s the name of the vectors passed between the encoder and the decoder in an encoder-decoder architecture?
Embedding vectors.
Context vectors.
Knowledge vectors.
Answer
The correct answer is 2.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.