1.3 How It Started: Grammars and Why Human Language Is Hard for Computers
Contents
1.3 How It Started: Grammars and Why Human Language Is Hard for Computers#
We saw that NLP today can tackle a multitude of different tasks, but this has not always been the case as researchers have faced several challenges presented by natural language. Let’s see how it all started.
The lessons in this chapter are meant to give you an insight into the NLP approaches used over the years, which I think are useful even if they aren’t currently state-of-the-art techniques. From the next chapter, there will be lessons showing how to use state-of-the-art technologies for the most common NLP tasks.
Grammars#
In NLP, a grammar is defined as a set of rules (usually recursive) for forming well-structured sentences in a language. For example, a grammar may describe how noun phrases, verb phrases, nouns, verbs, adjectives, and other parts of speech work together to constitute well-formed sentences.
Ideally, we may create a grammar able to verify whether an English sentence is grammatically correct or not, or to analyze the parts-of-speech of the sentences. In practice, creating such grammars is a very huge effort and it’s very difficult to cover all the irregularities and facets of human languages.
To get a better grasp of what we are talking about, here’s a sample grammar made of production rules that can derive the sentence “the little bear saw the trout”.
"""
S -> NP VP
NP -> Det Nom | Det N
Nom -> Adj N
VP -> V NP
Det -> "the"
Adj -> "little"
N -> "bear" | "trout"
V -> "saw"
"""
The whole process of deriving the sentence with the production rules can be visualized in the following image.
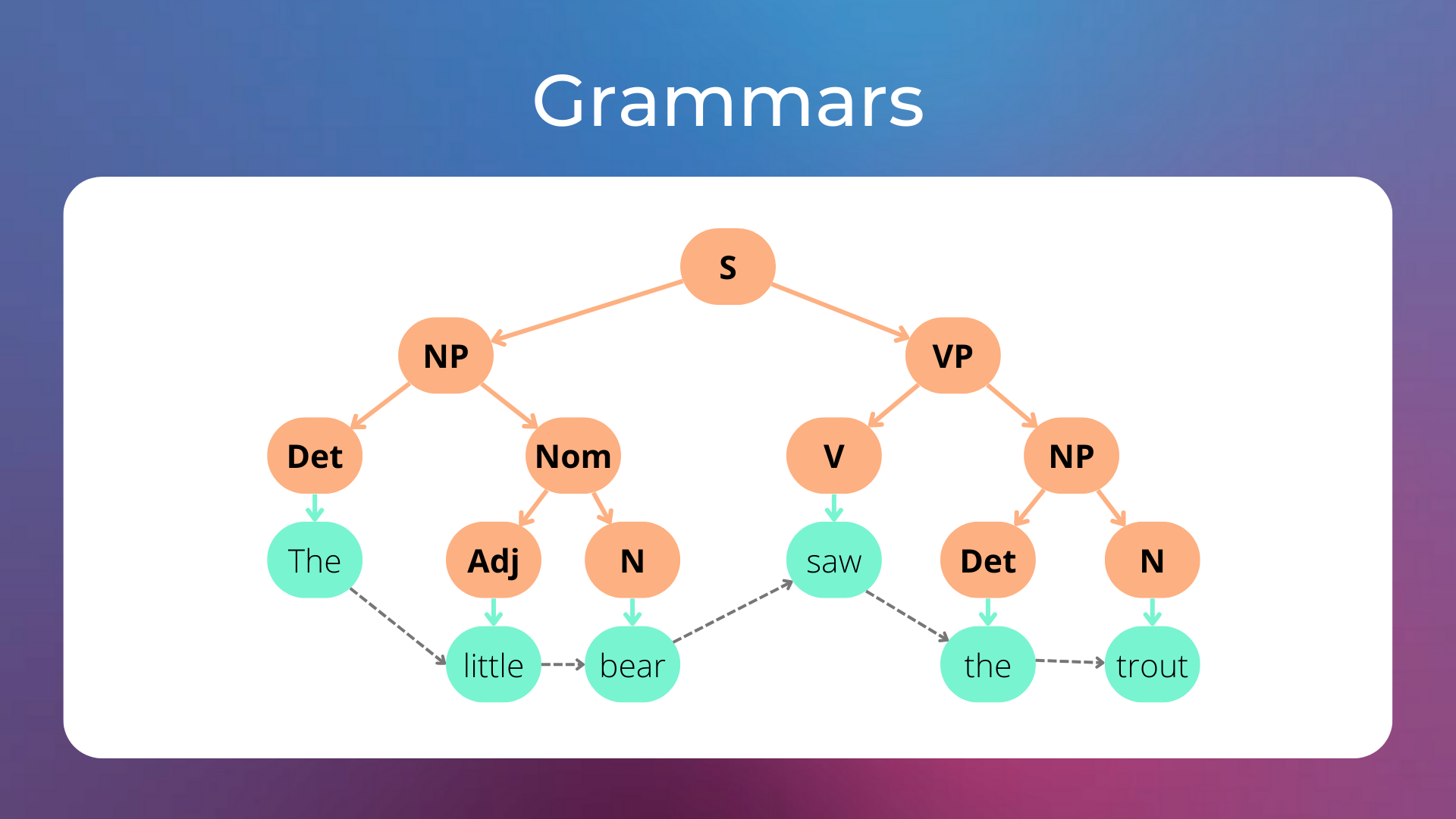
Here’s a step-by-step explanation of how the production rules can parse the sentence (feel free to skip it):
First, we try to derive the sentence from the symbol
S, which is the starting symbol.The symbol
Scan be replaced only by the symbolsNP VP(which stand for “noun phrase” and “verb phrase”). Now we haveNP VP.The symbol
NPcan be replaced by the symbolsDet NomorDet N, and we want to parse the sentence piece “the little bear”. AsNomcan be later replaced byAdj Nand we need to parse the adjective “little”, we can replaceNPbyDet Nom. Now we haveDet Nom VP.We replace
Detwith"the", obtaining"the" Nom VP.We replace
NomwithAdj N, obtaining"the" Adj N VP.We replace
Adjwith"little"andNwith"bear", obtaining"the" "little" "bear" VP.We replace
VPwithV NP, obtaining"the" "little" "bear" V NP.We replace
NPwithDet N, obtaining"the" "little" "bear" V Det N.We replace
Vwith"saw",Detwith"the", andNwith"trout", obtaining"the" "little" "bear" "saw" "the" "trout".
Quite cumbersome to verify that the sentence “the little bear saw the trout” is grammatically correct (according to our grammar), but you get the idea.
We can easily define a grammar in Python using the NLTK library, a Python library that provides many ready-to-use functions for analyzing texts. Let’s install it with pip.
pip install nltk
We’ll experiment with a specific type of grammar called Context Free Grammar, which is very similar to the grammar we used for the “the little bear saw the trout” example.
Context Free Grammar
A Context Free Grammar is a grammar whose derivation rules do not depend on context. Indeed, in each derivation rule that we saw in the previous example, such as VP -> V NP | VP PP or Det -> 'an' | 'my', on the left-hand side of the rule there is always one symbol (VP for the first example, Det for the second example).
On the other hand, a Context-Sensitive Grammar leverages context in the left-hand side of its rules, such as V NP -> Adv V N.
Let’s import nltk in our code and define a grammar to parse the sentence “I shot an elephant in my pajamas” using the CFG class (abbreviated for Context Free Grammar).
import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
PP -> P NP
NP -> Det N | Det N PP | 'I'
VP -> V NP | VP PP
Det -> 'an' | 'my'
N -> 'elephant' | 'pajamas'
V -> 'shot'
P -> 'in'
""")
We can then create a parser with the ChartParser class and generate all the possible parse trees using its parse method.
text = ['I', 'shot', 'an', 'elephant', 'in', 'my', 'pajamas']
parser = nltk.ChartParser(grammar)
for i, tree in enumerate(parser.parse(text)):
print(f"Parse tree number {i + 1}")
print(tree)
print()
Parse tree number 1
(S
(NP I)
(VP
(VP (V shot) (NP (Det an) (N elephant)))
(PP (P in) (NP (Det my) (N pajamas)))))
Parse tree number 2
(S
(NP I)
(VP
(V shot)
(NP (Det an) (N elephant) (PP (P in) (NP (Det my) (N pajamas))))))
The sentence “I shot an elephant in my pajamas” has two parse trees, let’s see why.
In the first tree, the person is in her/his pajamas.
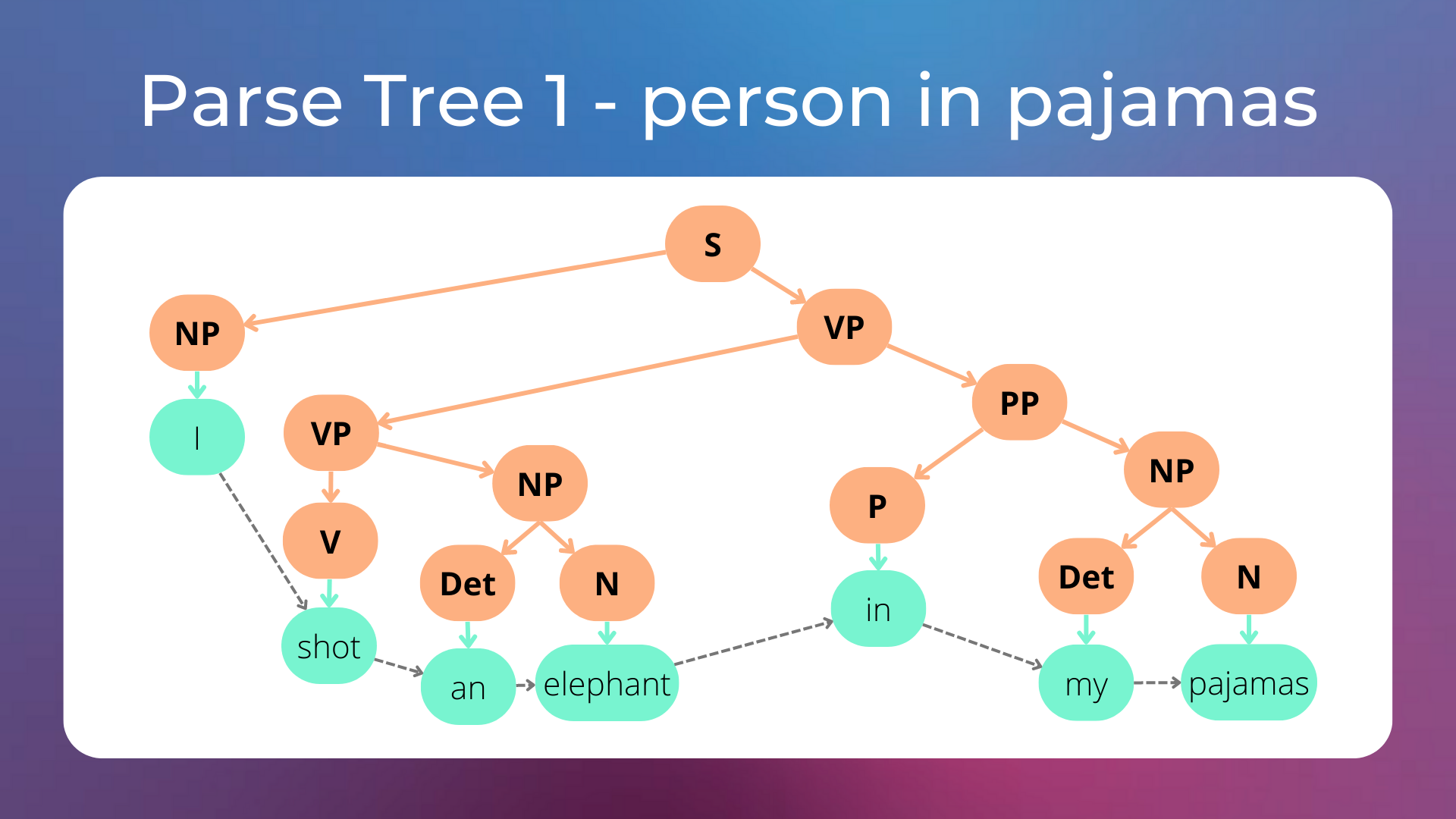
In the second tree, the elephant is in the person’s pajamas.
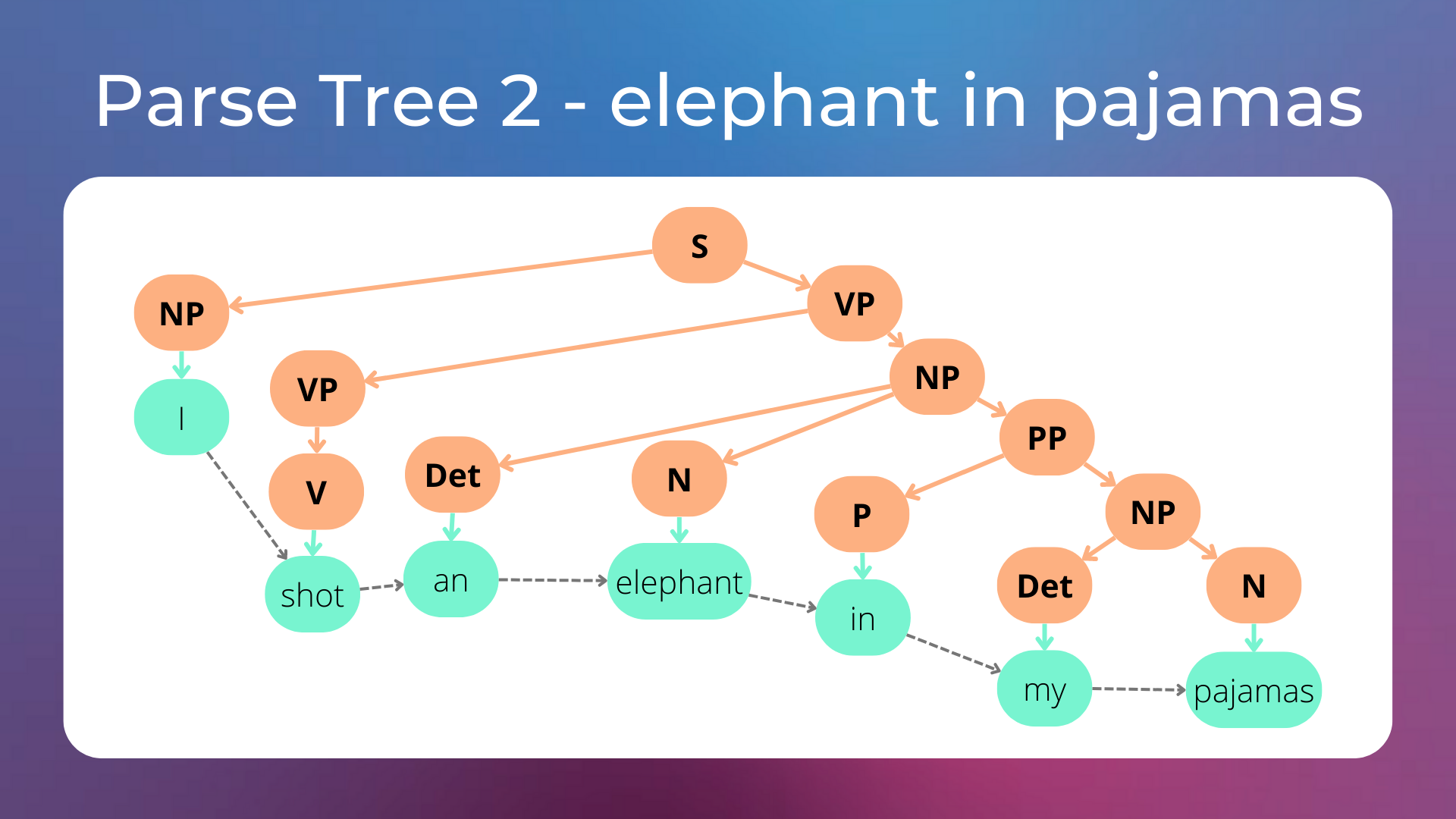
As humans, we know that it’s unlikely that the elephant is wearing a pajama, and therefore the first parse tree is probably the correct one. We may want to manage these cases by adding probabilities to derivation rules (i.e. with a Probabilistic Context Free Grammar), and then choose the parse tree generated by the production rules with the highest probabilities. However, as the number of production rules increases, the number of possible parse trees for each sentence grows astronomically, and it becomes computationally intractable to find the best parse tree each time. Moreover, it’s intuitive that we, as humans, do not reason that way.
Treebanks
A treebank (e.g. the Penn treebank) is a parsed text corpus with syntactic or semantic annotations about sentence structure. In the 1990’s, statistical models greatly benefitted from these datasets for building state-of-the-art natural language processing systems.
In the previous example, we passed the text to the parser as a list of syntactic units (e.g. words), which we can call tokens.
text = ['I', 'shot', 'an', 'elephant', 'in', 'my', 'pajamas']
The step of splitting text into these units is called tokenization.
Tokenization#
Tokenization is the process of splitting text into meaningful units called tokens.
Let’s import from NLTK two functions that split texts into tokens:
word_tokenize: Each token is a single word, punctuation character, or number.sent_tokenize: Each token is an entire sentence extracted from the text.
We also need to download the punkt NLTK package, which contains models needed for tokenization.
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize, sent_tokenize
We can now test both tokenization methods. Let’s try word_tokenize first.
text = "Good muffins cost $3.88\nin New York. Please buy me... two of them.\n\nThanks."
tokens = word_tokenize(text)
print(tokens)
['Good', 'muffins', 'cost', '$', '3.88', 'in', 'New', 'York', '.', 'Please', 'buy', 'me', '...', 'two', 'of', 'them', '.', 'Thanks', '.']
As expected, the word_tokenize function returns tokens like “Good”, “$”, “3.88”, and “.”.
Let’s try the sent_tokenize function now.
text = "Good muffins cost $3.88\nin New York. Please buy me... two of them.\n\nThanks."
sentences = sent_tokenize(text)
print(sentences)
['Good muffins cost $3.88\nin New York.', 'Please buy me... two of them.', 'Thanks.']
Indeed, the sent_tokenize function successfully split the text into three sentences.
The first approaches to NLP involved using tokenizations and grammars to model human languages. Later, to cope with problems such as that of homonyms (i.e. words with different meanings), grammars have been paired with lexical databases, such as WordNet. Let’s see how to link each token to its definition using WordNet.
WordNet#
WordNet is a lexical database of semantic relations (e.g. synonyms, hyponyms, etc) between words and definitions in more than 200 languages. Synonyms are grouped into “synsets” with short definitions and usage examples.
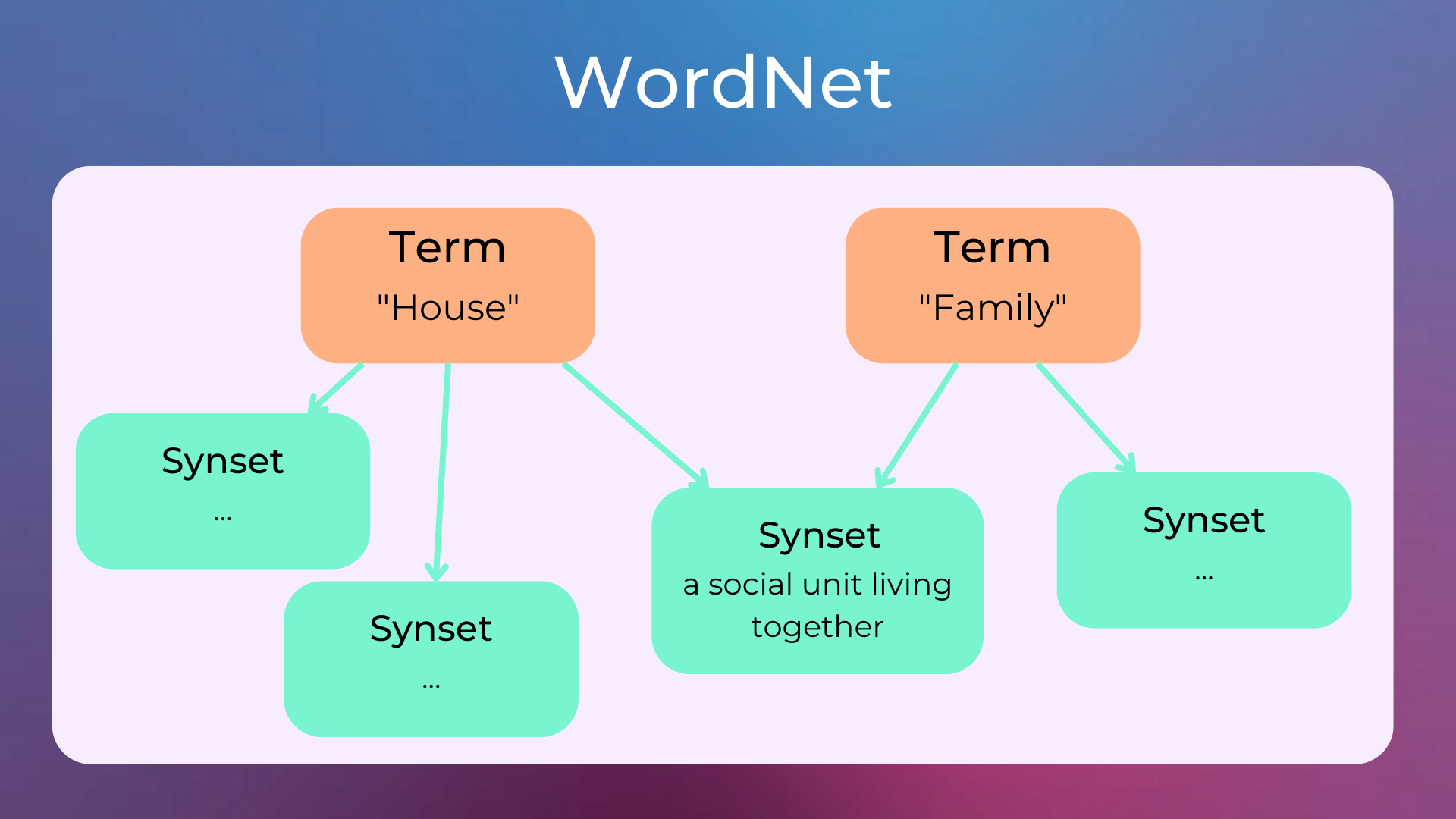
Let’s try to disambiguate the meaning of the word “trout” in the sentence “The little bear saw the trout”. The NLTK library provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet.
We import the library, along with some modules and functions:
wordnet: Provides a simple interface to WordNet.wsd: Provides word-sense disambiguation algorithms, i.e. algorithms that disambiguate homonyms in a sentence and link them to the correct synset in WordNet.
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4')
nltk.download('punkt')
from nltk.corpus import wordnet as wn # wordnet API
from nltk import wsd # word sense disambiguation with NLTK
from nltk.tokenize import word_tokenize # tokenization
Let’s see what possible meanings the word “trout” can have.
synsets_trout = wn.synsets("trout")
for synset in synsets_trout:
print("- " + synset.definition())
- flesh of any of several primarily freshwater game and food fishes
- any of various game and food fishes of cool fresh waters mostly smaller than typical salmons
The word “trout” has two different meanings stored in WordNet:
“trout” as the flesh of the animal.
“trout” as the animal per se.
Now, let’s try inferring which of these meanings is the correct one in the sentence “The little bear saw the trout”. First, we split the sentence into single words using the word_tokenize function.
sentence = "The little bear saw the trout"
sentence_tokenized = word_tokenize(sentence)
print(sentence_tokenized)
['The', 'little', 'bear', 'saw', 'the', 'trout']
Then, using the Lesk word-sense disambiguation algorithm implemented in the wsd.lesk function, we infer the correct meaning of the word “trout” in the sentence (i.e. the “trout as an animal” meaning).
synset_inferred = wsd.lesk(sentence_tokenized, "trout")
print("- " + synset_inferred.definition())
- any of various game and food fishes of cool fresh waters mostly smaller than typical salmons
The Lesk algorithm works by comparing the dictionary definitions of an ambiguous word (in this case “trout”) with the definitions of the terms contained in its neighborhood (so, the definitions of “the”, “little”, “bear”, and “saw”). The best dictionary definition of “trout” is the one that has the most overlap with the definitions of the other words in the sentence.
Let’s see now what possible meanings the word “bear” can have.
synsets_trout = wn.synsets("bear")
for synset in synsets_trout:
print("- " + synset.definition())
- massive plantigrade carnivorous or omnivorous mammals with long shaggy coats and strong claws
- an investor with a pessimistic market outlook; an investor who expects prices to fall and so sells now in order to buy later at a lower price
- have
- cause to be born
- put up with something or somebody unpleasant
- move while holding up or supporting
- bring forth,
- take on as one's own the expenses or debts of another person
- contain or hold; have within
- bring in
- have on one's person
- behave in a certain manner
- have rightfully; of rights, titles, and offices
- support or hold in a certain manner
- be pregnant with
They are a lot! The correct synset in our case is the first, where “bear” is the mammal. Let’s see what meaning is inferred by the Lesk algorithm.
synset_inferred = wsd.lesk(sentence_tokenized, "bear")
print("- " + synset_inferred.definition())
- take on as one's own the expenses or debts of another person
The Lesk algorithm infers the wrong sense for the word “bear”. While it may work for several cases, there is still a vast amount of special cases where word-sense disambiguation algorithms would need ad-hoc rules to properly function.
Why Human Language is Hard#
As you read in the chapter on the history of NLP, natural language was initially approached from the point of view of linguistics, with grammars and formal languages.
In a short time, researchers came across several aspects that make natural language difficult to be analyzed by computers (and that were the reasons that led to the ALPAC report in 1966 that greatly reduced NLP funding).
Ambiguity#
Human language is hard for computers because it is full of ambiguity. For example, the phrase “I saw the man with the binoculars” could mean that you saw a man who was using binoculars, or it could mean that you saw a man who was carrying a pair of binoculars.
Moreover, there are words with multiple meanings depending on the context (i.e. homonyms). For example, “bark” can be the bark of a dog or tree bark.
Ever Changing#
Another reason why human language is hard is that it’s constantly changing. New words are created all the time, and old words can change their meanings over time. For example, the word “cool” used to mean “cold” but now it means “good” or “great”. Computers have a hard time keeping up with these changes because they are not equipped to learn as humans do.
Contextual Information#
Contextual information is also important in understanding the meaning of a sentence. For example, the phrase “I’m hungry” could mean that the speaker is feeling physically hungry or that they feel emotionally hungry.
Sarcasm#
Sarcasm is another aspect of human language that is difficult for computers to understand. For example, the statement “That was a great presentation” said with a sarcastic tone could actually mean that the presentation was terrible.
Idioms#
An idiom is an expression that commonly has a figurative, non-literal meaning. What should a computer understand when a person says “it’s raining cats and dogs”?
On the Difficulties Of Grammars to Deal with Natural Language#
The approach with grammars and lexical databases didn’t lead to results of high-enough quality because of the aforementioned difficulties in understanding human language. Approaching all these aspects computationally soon becomes impractical, as it degenerates into a long list of ad-hoc rules for each exception.
Still, grammars and formal languages found their way into programming languages, designed from the start to be not ambiguous and easy to parse by computers. Unfortunately, natural language didn’t evolve that way. For this reasons, new approaches have been developed in NLP.
Code Exercises#
Quiz#
What is a grammar?
A set of rules for forming well-structured sentences in a language.
A set of rules for estimating the probability of each word in a language.
A set of rules describing the meaning of the sentences in a language.
Answer
The correct answer is 1.
How are groups of synonyms called in WordNet?
Synonym groups.
Synsets.
Homonyms.
Answer
The correct answer is 2.
What’s the name of a popular Python library that provides a simple interface to the WordNet lexical database?
NLTK.
WordNetAPI.
PythonNLP.
Answer
The correct answer is 1.
What is tokenization in NLP?
The process of splitting text into tokens, which are usually individual words but they can be also single characters or subwords.
The process of inferring tokens from text, such as noun phrase, verb phrase, noun, adjective, etc.
The process of solving ambiguities in sentences, linking words to their meanings in lexical databases.
Answer
The correct answer is 1.
What are two common tokenization functions from NLTK?
token_splitandsentence_splitword_splitandsentence_splitword_tokenizeandsent_tokenize
Answer
The correct answer is 3.
Why is it hard to deal with natural language with grammars?
Because it’s computationally intractable.
Because grammars are hard to define.
Because of aspects like ambiguity, the need for contextual information, and idioms.
Answer
The correct answer is 3.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.