1.1 A Brief History of NLP
Contents
1.1 A Brief History of NLP#
What is NLP#
Natural Language Processing (NLP) is a subfield of artificial intelligence that is concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze natural language data.
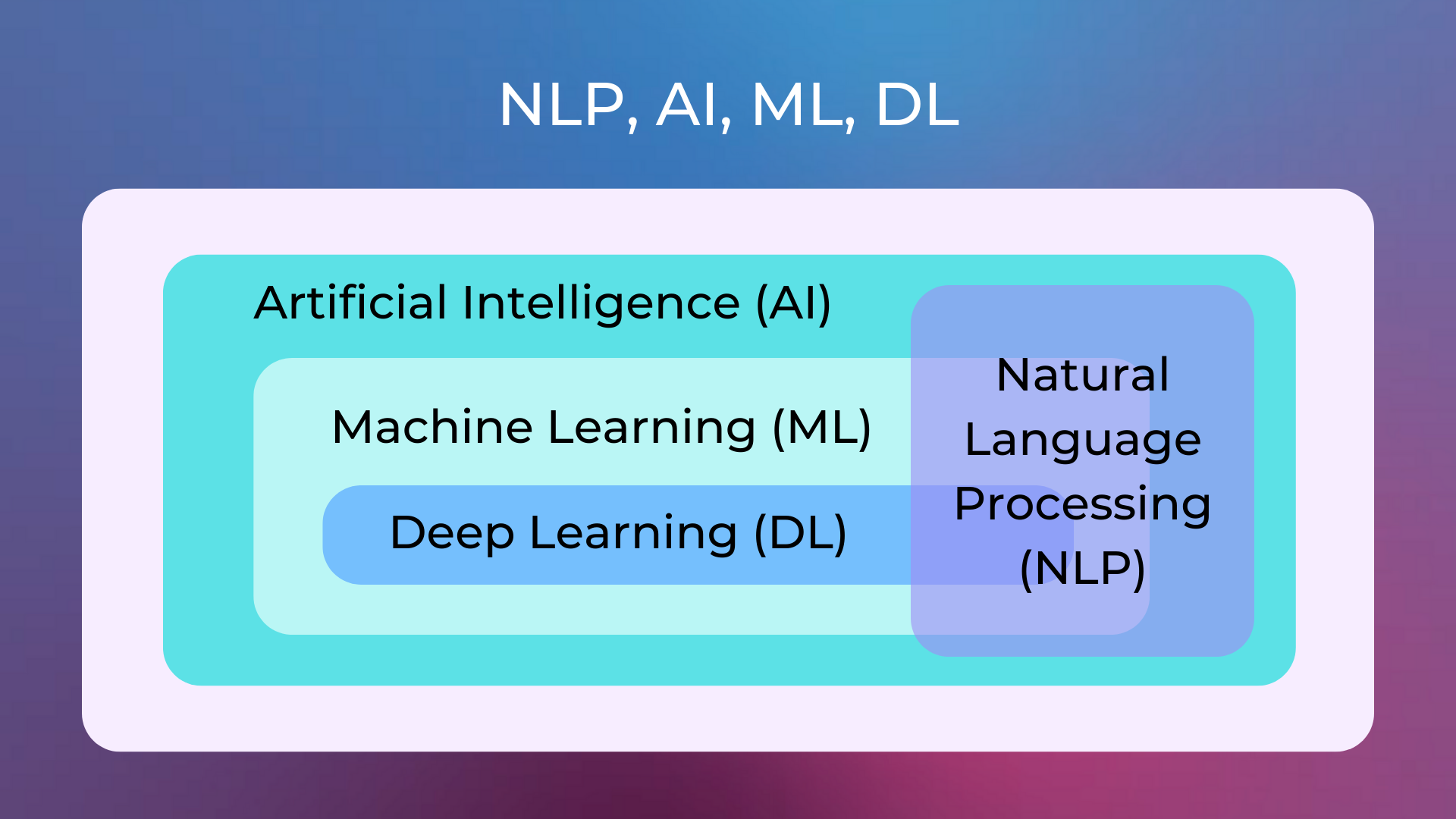
NLP is used to apply computational methods to text in order to extract meaning from it in a way that is similar to the way humans do. This can be used for a variety of tasks, such as automated machine translation, sentiment analysis, topic modeling, and text summarization.
NLP is a very active area of research, with new techniques and applications being developed all the time. Thanks to the advent of machine learning and deep learning, the quality of NLP results has improved a lot, thus fueling a great variety of valuable applications.
To be clearer about what NLP is capable of doing today, here are a couple of examples that I find particularly significant.
Generating Draft Articles#
There are NLP models that can generate draft articles written with quality very similar to that of a human writer. We can ask one of these models to write a small article explaining why sleep is important.

Here follows the article generated by the model (not cherry-picked).

As you can see, the generated article is very similar to what a writer would do. This is possible because this model has been trained on a huge amount of texts from around the Internet, trying to learn the distribution of words in the language. Therefore, when the model reads the instruction about writing an article about sleep, it generates the next most plausible text, rearranging the knowledge it has acquired during its training. The written article is therefore a reorganization of his acquired knowledge on training data, it is not a direct copy/paste from an already existing article.
Language Models
A model like the one in the previous examples is called language model. A language model is trained on a huge amount of texts, trying to learn the distribution of the words in the language. This can be done by training the model to predict the words that follow a sentence, or trying to recover masked words from their surrounding context.
GPT3
The previous examples have been produced using the GPT3 language model. This model is a transformer neural network consisting of 175 billions of parameters and requiring approximately 800GB of storage. The training data consists of hundreds of billions of words from texts from around the Internet. It has been trained by OpenAI, which hosts it and make it available as a service. GPT3 and its experiments are described in the paper Language Models are Few-Shot Learners.
The Turing Test
The Turing Test is a test for determining whether a machine is able to exhibit intelligent behaviour, indistinguishable from what a human would do. It is named after Alan Turing, who proposed it in 1950. The test is simple: a human judge engages in a natural language conversation with two other parties, one of whom is a machine and the other is a human. If the judge cannot tell which is which, then the machine is said to have passed the test.
In an experiment, human were asked to read short articles (about 200 words long) and distinguish whether they were generated by GPT3 or written by a human. As a result, 52% of the times the humans guessed correctly, which is really close to the performance of choosing at random (50%).
Does this mean that GPT3 passes the Turing Text? No. While GPT3 is very good at generating articles and writing coherent text, it tends to produce inconsistencies in long text. In addition, holding a conversation has numerous additional challenges, as the model must give plausible and coherent responses to a series of messages.
Rewriting Screenplays#
Similarly, a model of this type is also able to rewrite an existing text following specific instructions. Suppose we want to change the following scene from The Lord of the Rings.

In case you don’t remember, this is the Balrog.

Fig. 2 Image from the movie The Lord of the Rings.#
We can use as input to the model the screenplay and instructions on what to do with it. For example, let’s try to modify this scene to make Gandalf befriend the Balrog (i.e. the monster featured in the famous “You shall not pass” scene), rather than fight him.

Here is the revisited screenplay, in which a situation is reached where Gandalf and the Balrog begin to forge a bond. How is it possible? The model simply wrote the continuation of text it deemed most likely, thanks to the knowledge gained from its training data.

I hope these two examples show the current state of NLP advancement. Obviously, these models have limitations and they are not perfect, not all that glitters is gold. Despite this, results that were unthinkable only 5 years ago can now be achieved, and few people are aware of them. In this course, we’ll learn more about how these models work, their pros and cons, and what to expect in the near future.
A Brief History of NLP#
NLP has had a history of ups and downs, influenced by the growth of computational resources and changes in approaches.
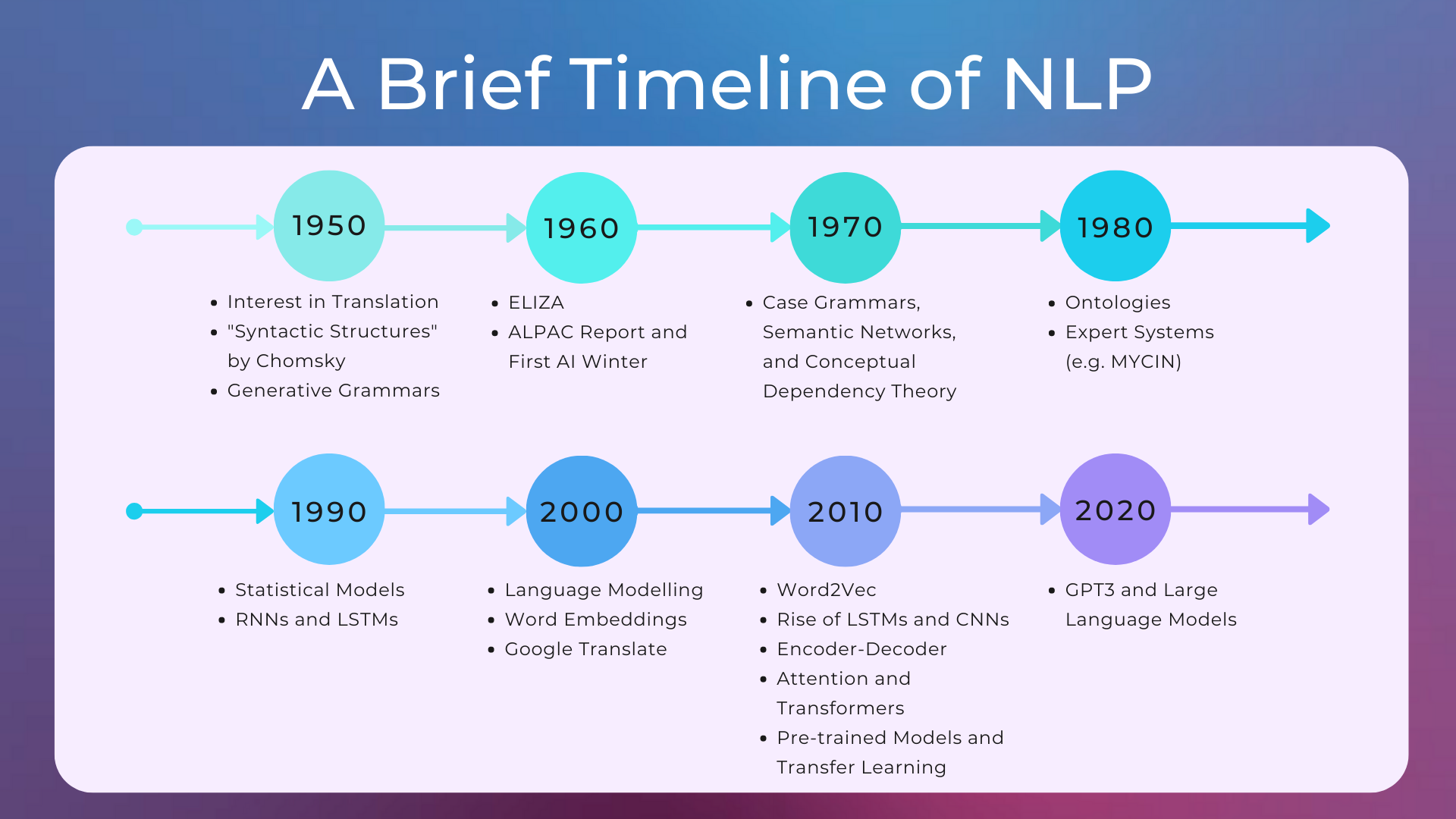
The 1950s, 1960s, and 1970s: Hype and the First AI Winter#
The first application that sparked interest in NLP was machine translation. The first machine translation systems were very simple, using dictionary lookup and basic word order rules to produce translations.
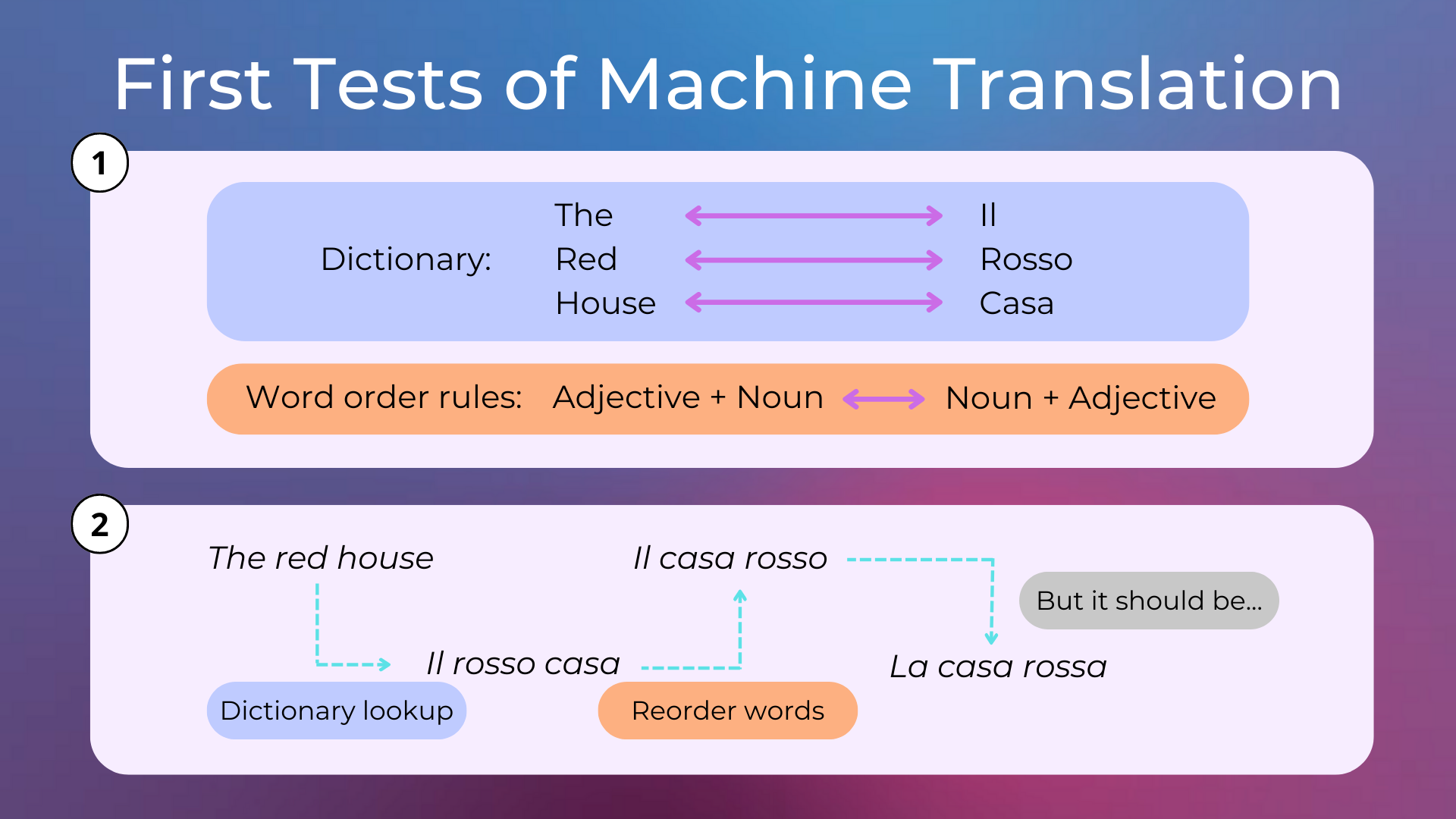
In 1957, the idea of generative grammar was introduced by Chomsky in the famous book Syntactic Structures, which helped researchers to better understand how machine translation could work.
Generative grammar
A generative grammar is an attempt at creating a set of rules able to correctly predict whether a text is grammatically (with respect to a specific language) correct or not. It’s a system of explicit (and usually recursive) rules that can be used to generate all the possible sentences in a language.
The 1950s saw a lot of excitement around the potential for fully automatic high-quality translation systems. However, this was quickly dampened by the reality that such systems were far from achievable at the time. These systems were not very effective, as they did not take into account the ambiguity of natural language. In 1966, the ALPAC (Automatic Language Processing Advisory Committee, a committee established in 1964 by the United States government in order to evaluate the progress in computational linguistics) released a report that recommended research into machine translation be halted, which had a significant impact on research in natural language processing and artificial intelligence more broadly.
The ALPAC report of 1966
As a conclusion, the recommendations of the report were to support machine translation research less on the achievement of a full end-to-end solution and more on being able to aid translators in their work. For example, the report suggested to look for practical methods for evaluating translations, evaluation of available sources of translations, and ways of speeding up the human translation process.
AI Winters
The history of artificial intelligence has experienced several hype cycles, followed by disappointment for not meeting high expectations, followed by research funding cuts, followed by a period of several years of little research (called AI winters), followed by renewed interest and hype again.
The first cycle began with the enthusiasm of the 1950s and ended with the 1966 ALPAC report and the subsequent AI winter until the end of the 1970s.
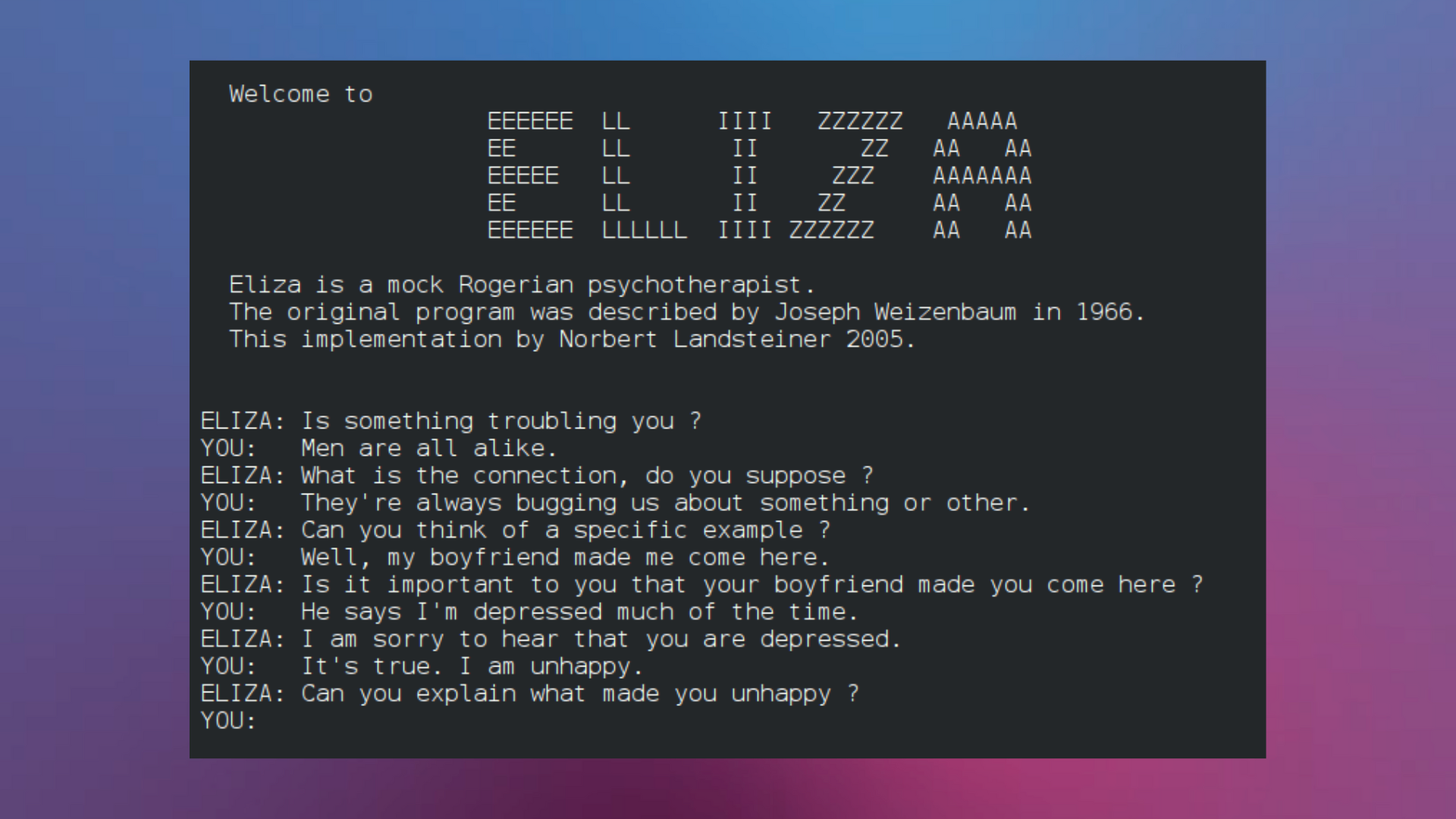
In addition to the development of language theories, several prototypes were also created during this period. The most famous prototype is perhaps ELIZA, designed to replicate the conversation between a psychologist and a patient. Here is a sample conversation with ELIZA.
Despite the slowdown in NLP research in the 1970s, there have been development in new computationally tractable theories of grammar, such as case grammars, semantic networks, and conceptual dependency theory.
The 1980s and 1990s: Expert Systems and Statistical Models#
In the 1980s, symbolic approaches (also called expert systems) were used in NLP, with hard-coded rules and ontologies (i.e. a knowledge base of facts, concepts and their relationships about a specific domain). Here’s an example of a fact stored in an ontology.
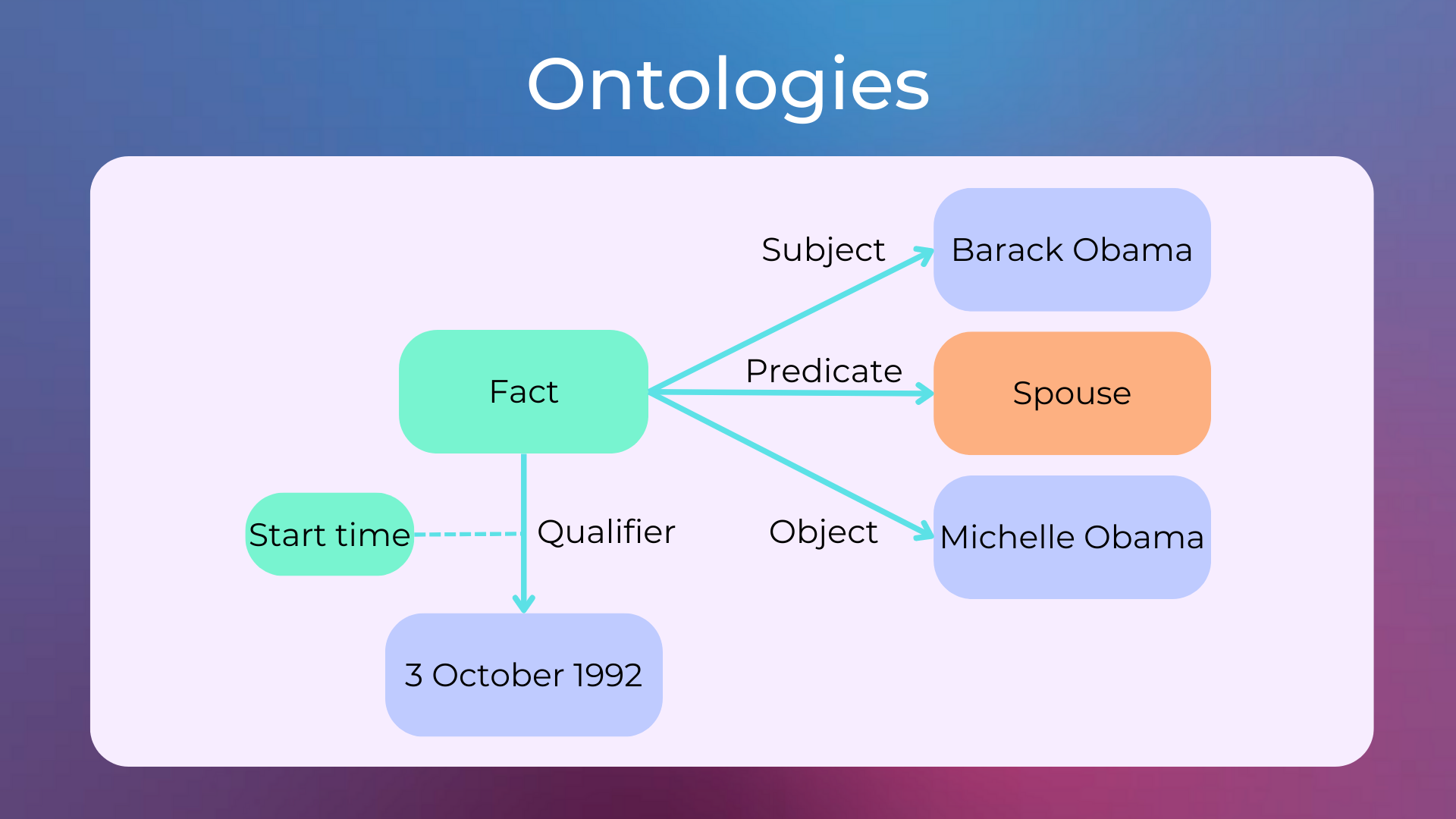
These were programs designed to mimic human experts in specific domains, such as medicine or law. One of the most famous expert systems was MYCIN, which was used to diagnose blood infections.
In the late 1980s and early 1990s, statistical models took over the symbolic approach. Statistical models were able to learn by themselves, through machine learning, the multitude of hard-coded rules of the expert systems. This was made possible above all by the increase in computational resources. The first recurrent neural networks (RNNs) were trained in these years.
The 2000s, 2010s, and 2020s: Neural Networks, Embeddings, and Transformers#
In the 2000s, neural networks are used more and more, initially for learning the distribution of language words and predicting the next words in a text given the previous ones (i.e. language modeling). Also in this period we begin to represent words with dense vectors of numbers called word embeddings, so that words with similar meanings are associated with similar vectors.

However, early algorithms were unable to efficiently learn this representation and so they were trained on a small amount of text, thus producing suboptimal vectors.
One of the first commercially successful natural language processing systems was the Google Translate service, which was launched in 2006. Google Translate used statistical models to automatically translate documents from one language to another.
In 2013 the Word2Vec paper Efficient Estimation of Word Representations in Vector Space was published, i.e. the first algorithm capable of learning word embedding efficiently, thus greatly improving previous word embedding. In the first experiments with these vectors, it was noticed that it is possible to do mathematical operations with them that represent semantic operations. For example, taking the vector of the word “king”, subtracting the vector of “man” from it and adding the vector of “woman”, we get a vector very close to the vector of “queen”.
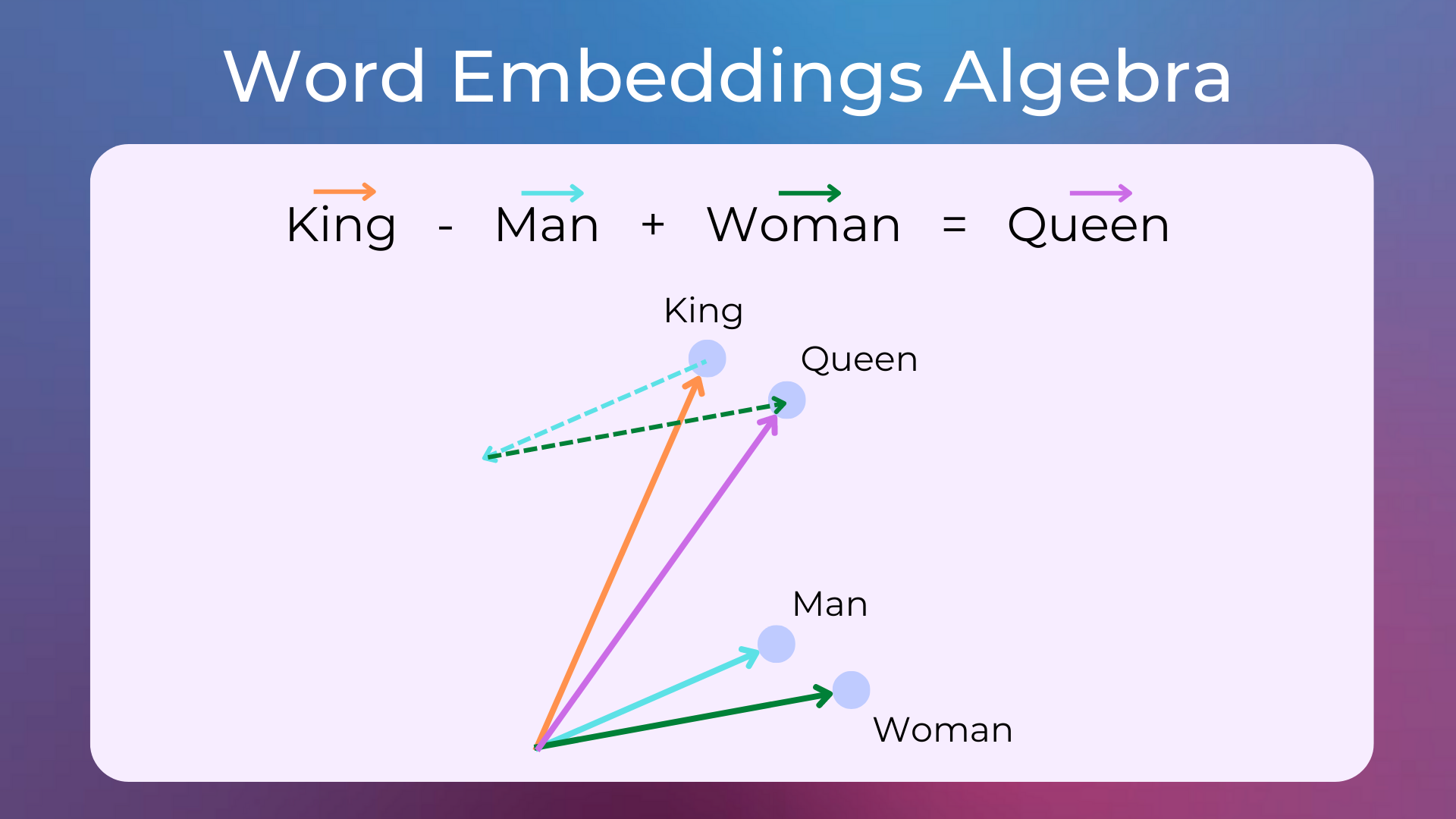
What made word embeddings of great importance in NLP until today has been the evidence that using pre-trained embeddings as features for machine learning models improves performance across a wide range of downstream tasks. Since then, a lot of work has been done to obtain word embeddings that better encapsulate the meaning of the texts they represent. The most used neural networks during this period were LSTM RNNs and Convolutional Neural Networks (CNNs).
Subsequently in 2014 a general formalization of sequence-to-sequence problems (such as machine translation, which translates a sequence of words into another sequence of words) was proposed with a system made up of two neural networks called Encoder-Decoder: the first network is called Encoder and encodes the entire input into a vector (commonly called context vector), the second is called Decoder and decodes the output from the vector.
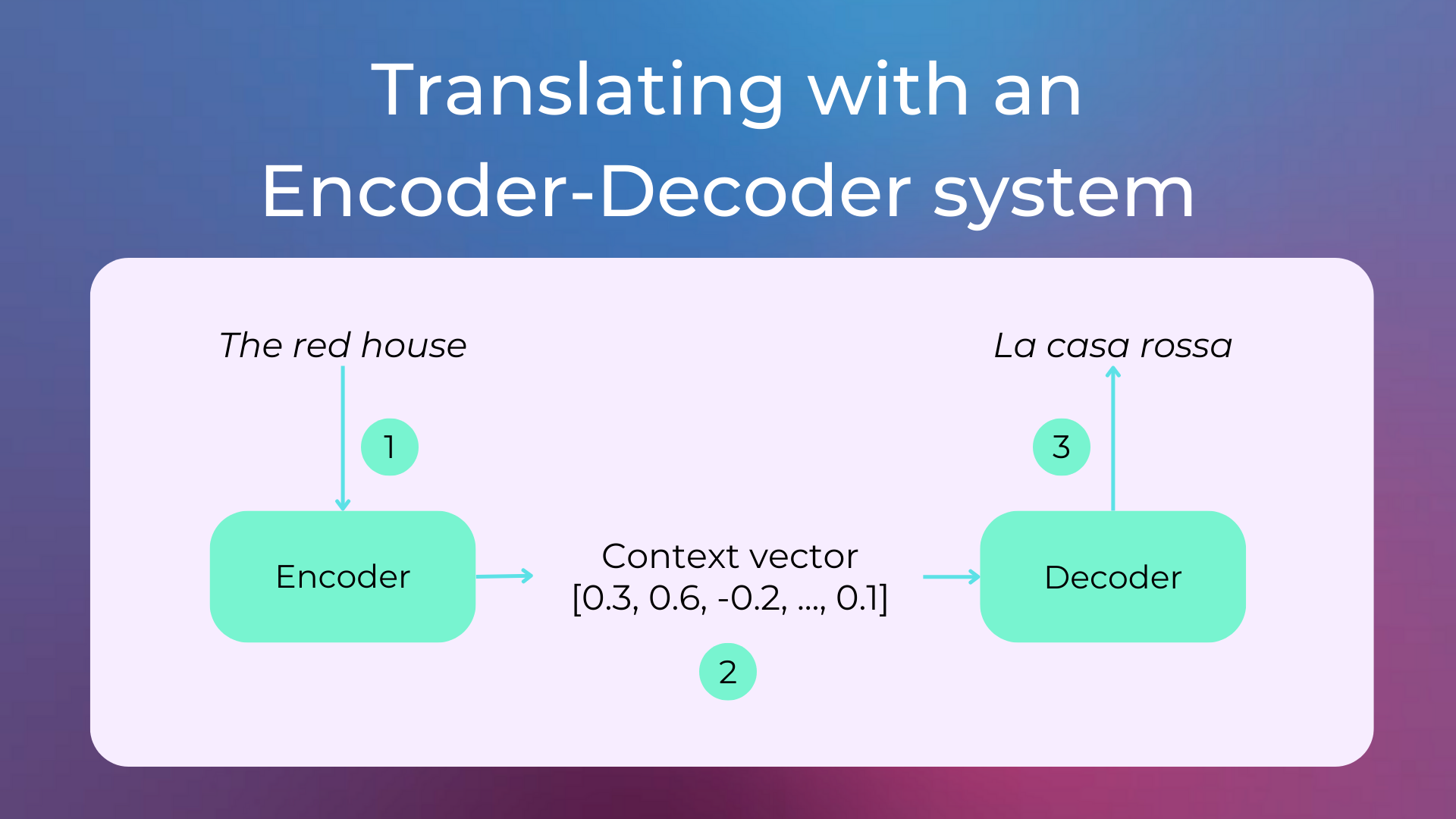
The encoder-decoder architecture was then very successful with the use of attention mechanisms, which allow a greater passage of information between the two modules. This new system was so successful that, in 2016, Google Translate replaced its statistical model with a neural sequence-to-sequence model. The attention mechanism was then used in 2017 also to create a new type of neural network called Transformer (with the famous paper Attention Is All You Need), which is still the most used neural network in NLP today. A very popular transformer-based model is BERT.
In the following years, Transformers were trained in such a way as to be able to produce embeddings from texts that also take into account the context in which the words are, advancing the state of the art in the majority of NLP tasks. These models are essentially language models trained in a self-supervised way on datasets comprising large quantities of texts from around the Internet. These models are also called pre-trained models because, after being first trained on a large training set, they can then be reused in different tasks after a small adaptation training (called fine-tuning).
A trend today is to train increasingly larger language models on ever larger datasets. The reason for this is that these models are able to solve a wide range of NLP tasks excellently and without further training. The two examples about generating draft articles and rewriting screenplays were produced using one of these large language models.
The Recent Boom of NLP#
It’s no secret that Natural Language Processing has seen a boom in recent years, especially from Word2Vec onwards. The main reasons for its success are:
The increasing availability of text data from around the internet, thanks to which it is possible to learn the characteristics of a language starting from billions of texts.
The development of powerful computational resources, especially better and better hardware for the type of computations that neural networks need (e.g. GPUs and TPUs).
The development of frameworks for developing neural networks like TensorFlow and PyTorch.
The advances in machine learning algorithms, such as representing text with semantic vectors, transformers, and attention mechanisms.
Quiz#
Which one of the following tasks is not about NLP?
Forecasting the stock market leveraging business news articles.
Classifying which emails should go in the spam folder.
Translating natural language into SQL queries.
Detecting fires from satellite images.
Answer
The correct answer is 4.
Explanation:
It’s NLP because it deals with analyzing business news articles (text) looking for events or particular sentiment.
It’s NLP as it’s about text classification.
It’s NLP as it’s a sequence-to-sequence problem involving text.
It’s an image classification problem and so it’s about the Computer Vision field.
Is it possible today to automatically generate newspaper articles that are hardly distinguishable from those written by human writers? True or False.
Answer
The correct answer is True, but only for specific types of articles.
Explanation:
As we saw in the example about generating a draft of an article about the importance of sleep, today with AI it is possible to generate convincing articles automatically. However, there are often inaccuracies in these articles and they become inconsistent if long enough.
What’s the goal of a language model?
Classifying the language of a text.
Learning the distribution of the words in a language.
Detecting whether a text is grammatically correct or not.
Containing all the rules needed to generate correct texts in a language.
Answer
The correct answer is 2.
What was the first task faced in the history of NLP?
Machine translation.
Text generation.
Text classification.
Text similarity.
Answer
The correct answer is 1.
What are the AI Winters?
Moments when artificial intelligence research funds were exhausted due to economic crises.
Periods in which the research on artificial intelligence didn’t achieve significant advances.
A period of reduced funding and interest in the AI technology, typically alternating with moments of hype.
Answer
The correct answer is 3.
What’s the name of the programs designed to mimic human experts in specific domains, such as medicine or law?
Symbolic Experts.
Domain Programs.
Domain Experts.
Expert Systems.
Answer
The correct answer is 4.
What are word embeddings?
Vectors representing words, such that semantically similar words are represented by similar vectors.
Vectors used to compress the meaning of a text in sequence-to-sequence problems.
A mechanism that made neural networks more efficient, leading to the birth of the Transformer neural network.
Answer
The correct answer is 1.
What is a Transformer in NLP?
A particular type of neural network that leverages attention mechanisms.
A particular type of neural network that leverages ontologies.
A particular language model that can be fine-tuned for specific tasks.
Answer
The correct answer is 1.
Which of the following is not a reason for the recent boom of NLP.
The advances in machine learning algorithms.
The development of powerful computational resources.
The development of large expert systems with hand-written rules.
The increasing availability of text data from around the internet.
The development of frameworks for developing neural networks.
Answer
The correct answer is 3.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.