Chapter Quiz
Contents
Chapter Quiz#
Here you can find all the quizzes from the lessons in this chapter. Try to solve them to understand how well you have learned the concepts.
1.1 A Brief History of NLP#
Which one of the following tasks is not about NLP?
Forecasting the stock market leveraging business news articles.
Classifying which emails should go in the spam folder.
Translating natural language into SQL queries.
Detecting fires from satellite images.
Answer
The correct answer is 4.
Explanation:
It’s NLP because it deals with analyzing business news articles (text) looking for events or particular sentiment.
It’s NLP as it’s about text classification.
It’s NLP as it’s a sequence-to-sequence problem involving text.
It’s an image classification problem and so it’s about the Computer Vision field.
Is it possible today to automatically generate newspaper articles that are hardly distinguishable from those written by human writers? True or False.
Answer
The correct answer is True, but only for specific types of articles.
Explanation:
As we saw in the example about generating a draft of an article about the importance of sleep, today with AI it is possible to generate convincing articles automatically. However, there are often inaccuracies in these articles and they become inconsistent if long enough.
What’s the goal of a language model?
Classifying the language of a text.
Learning the distribution of the words in a language.
Detecting whether a text is grammatically correct or not.
Containing all the rules needed to generate correct texts in a language.
Answer
The correct answer is 2.
What was the first task faced in the history of NLP?
Machine translation.
Text generation.
Text classification.
Text similarity.
Answer
The correct answer is 1.
What are the AI Winters?
Moments when artificial intelligence research funds were exhausted due to economic crises.
Periods in which the research on artificial intelligence didn’t achieve significant advances.
A period of reduced funding and interest in the AI technology, typically alternating with moments of hype.
Answer
The correct answer is 3.
What’s the name of the programs designed to mimic human experts in specific domains, such as medicine or law?
Symbolic Experts.
Domain Programs.
Domain Experts.
Expert Systems.
Answer
The correct answer is 4.
What are word embeddings?
Vectors representing words, such that semantically similar words are represented by similar vectors.
Vectors used to compress the meaning of a text in sequence-to-sequence problems.
A mechanism that made neural networks more efficient, leading to the birth of the Transformer neural network.
Answer
The correct answer is 1.
What is a Transformer in NLP?
A particular type of neural network that leverages attention mechanisms.
A particular type of neural network that leverages ontologies.
A particular language model that can be fine-tuned for specific tasks.
Answer
The correct answer is 1.
Which of the following is not a reason for the recent boom of NLP.
The advances in machine learning algorithms.
The development of powerful computational resources.
The development of large expert systems with hand-written rules.
The increasing availability of text data from around the internet.
The development of frameworks for developing neural networks.
Answer
The correct answer is 3.
1.2 What Tasks Can I Solve with NLP Today?#
Select the example that is not about text classification.
Detecting the language of a text.
Classifying a tweet as containing or not containing obscene text.
Translating a sentence from English to Italian.
Labeling a Git issue as “Improvement proposal”.
Answer
The correct answer is 3.
Explanations:
It’s a text classification problem where each language is a separate class.
It’s a text classification problem with the class “obscene”.
The problem consists in transforming a text into another text, i.e. it’s a text-to-text problem.
It’s a text classification problem with the class “Improvement proposal”.
Select the example that is not about text classification.
Getting the most similar document to my search query.
Detecting spam emails.
Categorizing news articles into a known taxonomy of categories.
Automatically filtering tweets about climate disasters.
Answer
The correct answer is 1.
Explanations:
In this problem, we need to rank a collection of documents according to semantic relevance with the search query. It’s a text ranking problem.
It’s a text classification problem with the class “spam”.
This is a little tricky but it’s still a text classification problem where each category is a separate class. There can be some “taxonomy logic” implemented, e.g. automatically classifying an article with “Artificial Intelligence” if the model predicted the category “Machine Learning”.
It’s a text classification problem with the class “is about climate disaster”.
Choose the option that best describes the goal of a semantic search engine.
Matching words in the queries with words in the documents semantically by assigning appropriate weights to words.
Retrieving and ranking all types of documents (texts, images, etc) that are relevant to a query.
Looking for the documents most relevant to a query, going beyond text-matching and taking semantics into account (typically with word embeddings).
Answer
The correct answer is 3.
What are two common types of Question Answering models?
Extractive and Generative.
Generative and Multimodal.
Chatbot-based and Personal Assistant-based.
Answer
The correct answer is 1.
What’s the name of the depicted NLP task?
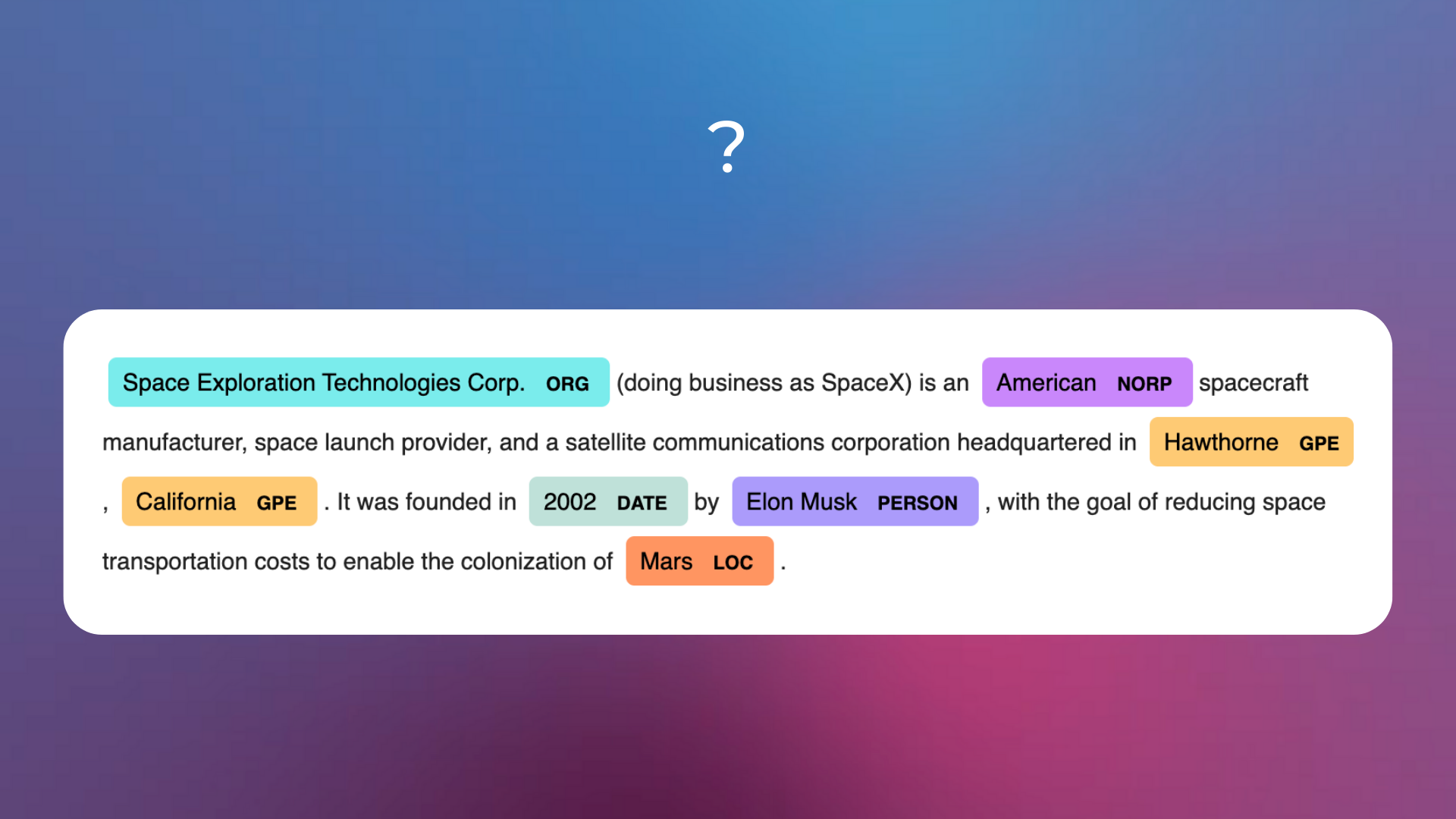
Relation Extraction.
Named-Entity Recognition.
Keyword and Keyphrases Extraction.
Answer
The correct answer is 2.
What do nodes and edges in a Knowledge Graph typically represent?
Nodes represent relationships, and edges represent entities.
Nodes represent words, and edges represent semantic relationships between the words.
Nodes represent entities, and edges represent relationships between the entities.
Answer
The correct answer is 3.
What are two possible names of the task that transcribes speech into text? (2 correct answers)
Automatic Speech Transcription.
Speech-to-Text.
Automatic Speech Recognition.
Answer
The correct answers are 2 and 3.
1.3 How It Started: Grammars and Why Human Language Is Hard for Computers#
What is a grammar?
A set of rules for forming well-structured sentences in a language.
A set of rules for estimating the probability of each word in a language.
A set of rules describing the meaning of the sentences in a language.
Answer
The correct answer is 1.
How are groups of synonyms called in WordNet?
Synonym groups.
Synsets.
Homonyms.
Answer
The correct answer is 2.
What’s the name of a popular Python library that provides a simple interface to the WordNet lexical database?
NLTK.
WordNetAPI.
PythonNLP.
Answer
The correct answer is 1.
What is tokenization in NLP?
The process of splitting text into tokens, which are usually individual words but they can be also single characters or subwords.
The process of inferring tokens from text, such as noun phrase, verb phrase, noun, adjective, etc.
The process of solving ambiguities in sentences, linking words to their meanings in lexical databases.
Answer
The correct answer is 1.
What are two common tokenization functions from NLTK?
token_splitandsentence_splitword_splitandsentence_splitword_tokenizeandsent_tokenize
Answer
The correct answer is 3.
Why is it hard to deal with natural language with grammars?
Because it’s computationally intractable.
Because grammars are hard to define.
Because of aspects like ambiguity, the need for contextual information, and idioms.
Answer
The correct answer is 3.
1.4 Statistical Approaches and Text Classification with N-grams#
What is text vectorization?
The process of converting text into an unordered set of words.
The process of converting text into a numerical vector that most machine learning models can understand.
The process of converting text into vectors of words that are easier to use by machine learning models.
Answer
The correct answer is 2.
What does the ngram_range parameter of the CountVectorizer class specify?
The minimum and maximum number of n-grams to be extracted by the vectorizer.
The regular expression used for tokenization.
The lower and upper boundary of the range of n-values for different n-grams to be extracted.
Answer
The correct answer is 3.
What is a sparse matrix?
A matrix in which most of the elements are zero.
A matrix with few rows and columns.
A matrix with low rank.
Answer
The correct answer is 1.
What does the lowercase parameter of the CountVectorizer class specify?
Whether or not to convert all characters to lowercase before tokenizing.
Whether or not to convert all characters to lowercase after tokenizing.
To check if the input text is already lowercase.
Answer
The correct answer is 1.
What do the max_df and min_df parameters of the CountVectorizer class specify?
To ignore terms that have a document frequency respectively lower and higher than the two parameters.
To consider only terms that have a document frequency respectively higher and lower than the two parameters.
To ignore terms that have a document frequency respectively higher and lower than the two parameters.
Answer
The correct answer is 3.
What does the max_feature parameter of the CountVectorizer class specify?
To build a vocabulary that only considers the top max_features ordered by importance for predicting the label.
To build a vocabulary that only considers the top max_features ordered by term frequency across the corpus.
To build a vocabulary that only considers the bottom max_features ordered by term frequency across the corpus.
Answer
The correct answer is 2.
What is a bag of words representation?
A representation where text is represented as the set of its words, disregarding word order but considering grammar.
A representation where text is represented as the set of its words, disregarding grammar and even word order but keeping multiplicity.
A representation where text is represented as the ordered list of its words, disregarding grammar but keeping multiplicity.
Answer
The correct answer is 2.
1.5 Stemming, Lemmatization, Stopwords, POS Tagging#
What do we mean by inflection when talking about natural languages?
It’s the modification of a word to express different grammatical categories such as tense, case, and gender.
It’s the modification of a word over time to express different meanings.
It’s the tone of voice of a specific word relative to its context.
Answer
The correct answer is 1.
Which of the following reduces words always to a base-form which is an existing word?
Stemming.
Lemmatization.
Answer
The correct answer is 2.
Which of the following can leverage context to find the correct base form of a word?
Stemming.
Lemmatization.
Answer
The correct answer is 2.
Which of the following is typically faster?
Stemming.
Lemmatization.
Answer
The correct answer is 1.
What’s the name of the nltk stemmer class typically used for stemming in languages other than English?
ForeignStemmer.WinterStemmer.SnowballStemmer
Answer
The correct answer is 3.
What’s the name of the function typically used in nltk for extracting the part-of-speech of each token in a text?
nltk.pos_tag.nltk.lemmatize.nltk.get_stopwords.
Answer
The correct answer is 1.
1.9 Representing Texts as Vectors: TF-IDF#
Choose the option that best describes the Zipf’s law.
It states that, given some corpus of natural language utterances, the frequency of any word is inversely proportional to its rank in the frequency table.
It states that, given some corpus of natural language utterances, the frequency of any word is directly proportional to its rank in the frequency table.
It states that, given some corpus of natural language utterances, the frequency of any word is inversely proportional to its number of occurrences in the corpus.
Answer
The correct answer is 1.
Stopwords are the words that, in a typical corpus, have the…
Most occurrences.
Least occurrences.
Answer
The correct answer is 1.
What does the acronym TF-IDF stand for?
Term Frequency - Inverse Document Factor
Term Factor - Inverse Document Factor
Term Frequency - Inverse Document Frequency
Answer
The correct answer is 3.
The TF term of TF-IDF is directly proportional to…
The number of times a word appears in all the documents in the corpus
The number of times a word appears in a document
The number of documents in the corpus
Answer
The correct answer is 2.
The IDF term of TF-IDF is inversely proportional to…
The frequency of a word in a specific document
The document frequency of a word across a collection of documents
The number of documents in the corpus
Answer
The correct answer is 2.
As a consequence of TF-IDF:
Rare words have high scores, common words have low scores
Common words have high scores, rare words have low scores
Answer
The correct answer is 1.
1.12 Representing Texts as Vectors: Word Embeddings#
What are word embeddings?
A type of word representation with numerical vectors that allows words with similar meanings to have a similar representation.
A vectorized representation of words obtained with one-hot encoding
A type of word representation with sparse word vectors that allows words with similar meanings to have a similar representation.
Answer
The correct answer is 1.
What is a common distinction between word embedding models?
Context-dependent and context-independent word embeddings.
Numerical and word-based embeddings.
Attention-dependent and attention-independent word embeddings.
Answer
The correct answer is 1.
Choose the option that better describes the ELMO and CoVe models.
Context-independent word embeddings.
Context-dependent and RNN-based word embeddings.
Context-dependent and Transformer-based word embeddings.
Answer
The correct answer is 2.
Choose the option that better describes the Word2Vec, GloVe and FastText models.
Context-independent word embeddings.
Context-dependent and RNN-based word embeddings.
Context-dependent and Transformer-based word embeddings.
Answer
The correct answer is 1.
Choose the option that better describes the BERT, XLM, RoBERTa and ALBERT models.
Context-independent word embeddings.
Context-dependent and RNN-based word embeddings.
Context-dependent and Transformer-based word embeddings.
Answer
The correct answer is 3.
Choose the correct option.
Word embeddings models are often finetuned models that can be retrained for specific use cases.
Word embeddings models must be trained from scratch for each specific use case.
Word embeddings models are often pre-trained models that can be finetuned for specific use cases.
Answer
The correct answer is 3.
Choose the correct option.
Sentence embeddings models compute an embedding representation of a sentence by averaging the vectors of the words composing the sentence.
Sentence embeddings models can compute an embedding representation of both individual words and sentences out of the box.
Answer
The correct answer is 2.
Choose the correct option.
The latest embedding models are always better than the previous ones in all the tasks.
When choosing an embedding model, it’s better to look at benchmarks to find the best ones for your specific task.
Answer
The correct answer is 2.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.