2.16 Project: Building a Knowledge Base from Texts
Contents
2.16 Project: Building a Knowledge Base from Texts#
In this article, we see how to implement a pipeline for extracting a Knowledge Base from texts or online articles. We’ll talk about Named Entity Recognition, Relation Extraction, Entity Linking, and other common steps done when building Knowledge Graphs.
You can try the final demo on its Hugging Face Space.

Here is an example of a knowledge graph extracted from 20 news articles about “Google”. At the end of this lesson, you’ll be able to build knowledge graphs from any list of articles you like.
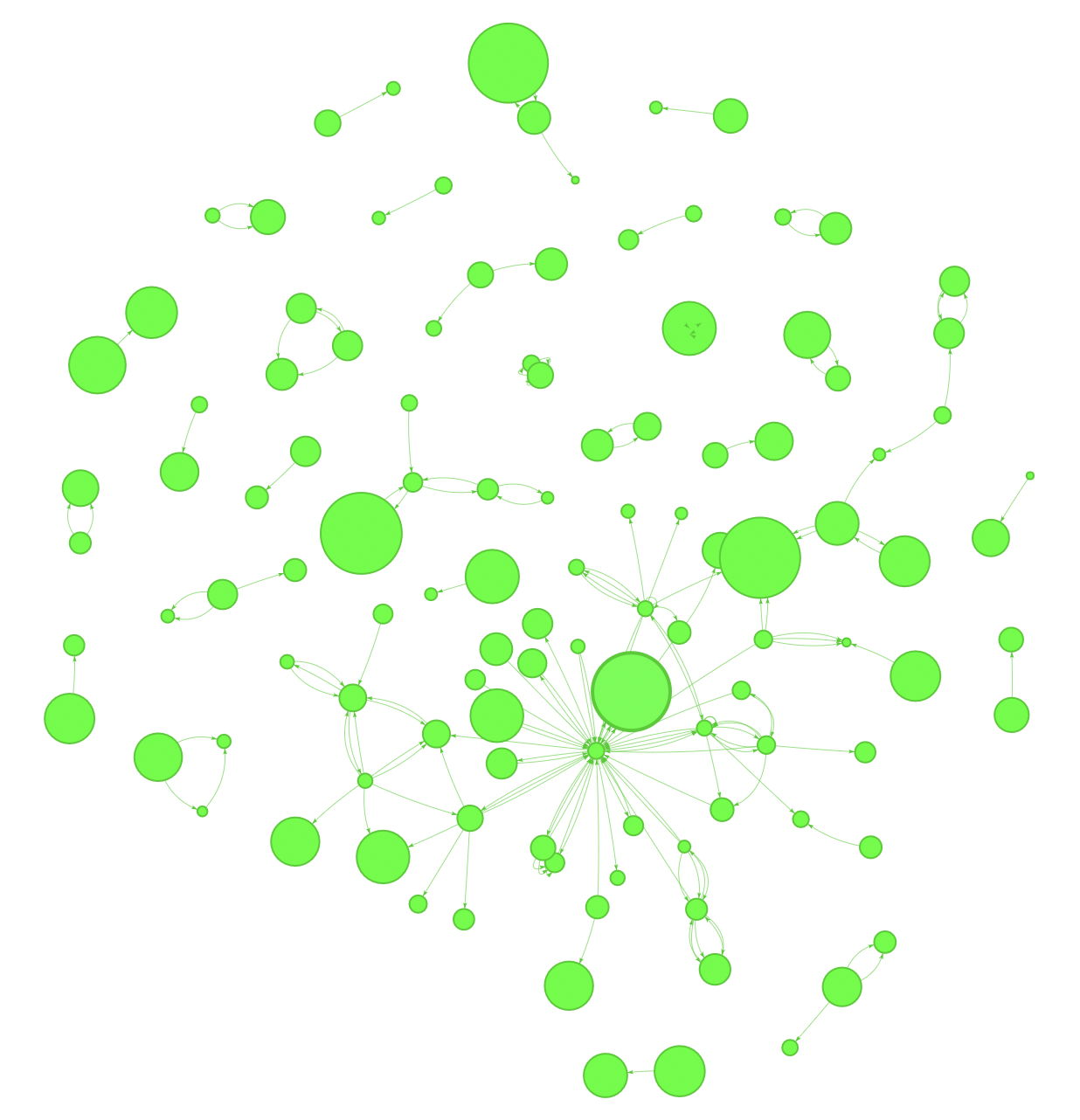
Let’s zoom into it to read about its entities and relations.
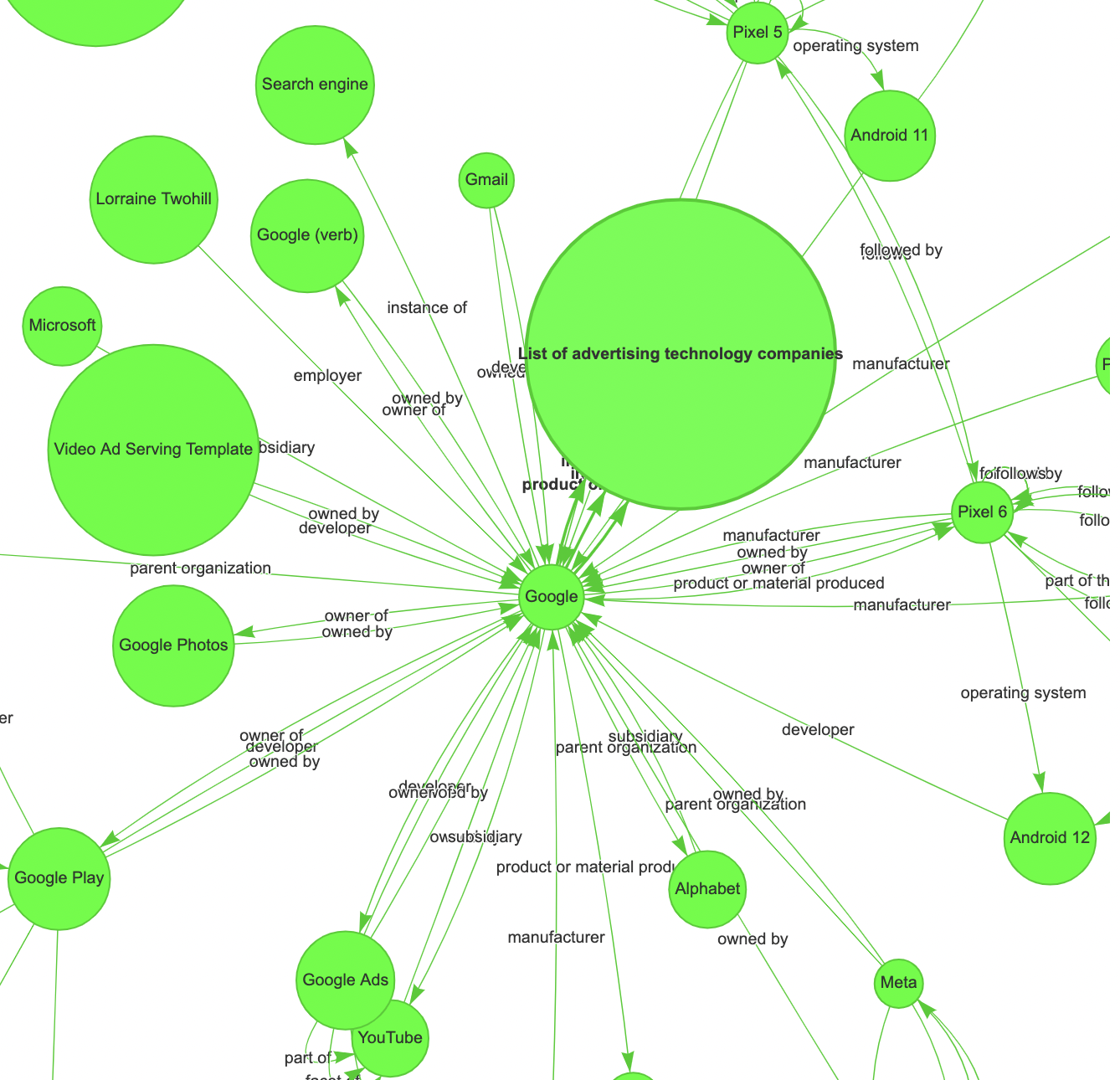
So, this is what we are going to do:
Learn how to build knowledge graphs and how the REBEL model works.
Implement a full pipeline that extracts relations from texts and builds a knowledge graph.
Visualize the knowledge graph.
How to Build a Knowledge Graph#
To build a knowledge graph from text, we typically need to perform two steps:
Extract entities, a.k.a. Named Entity Recognition (NER), which are going to be the nodes of the knowledge graph.
Extract relations between the entities, a.k.a. Relation Classification (RC), which are going to be the edges of the knowledge graph.
These multiple-step pipelines often propagate errors or are limited to a small number of relation types. Recently, end-to-end approaches have been proposed to tackle both tasks simultaneously. This task is usually referred to as Relation Extraction (RE). In this article, we’ll use an end-to-end model called REBEL, from the paper Relation Extraction By End-to-end Language generation.
How REBEL Works#
REBEL is a text2text model trained by BabelScape by fine-tuning BART for translating a raw input sentence containing entities and implicit relations into a set of triplets that explicitly refer to those relations. It has been trained on more than 200 different relation types.
The authors created a custom dataset for REBEL pre-training, using entities and relations found in Wikipedia abstracts and Wikidata, and filtering them using a RoBERTa Natural Language Inference model (similar to this model). Have a look at the paper to know more about the creation process of the dataset. The authors also published their dataset on the Hugging Face Hub.
The model performs quite well on an array of Relation Extraction and Relation Classification benchmarks.
You can find REBEL in the Hugging Face Hub.
Implementing the Knowledge Graph Extraction Pipeline#
Here is what we are going to do, progressively tackling more complex scenarios:
Load the Relation Extraction REBEL model.
Extract a knowledge base from a short text.
Extract a knowledge base from a long text.
Filter and normalize entities.
Extract a knowledge base from an article at a specific URL.
Extract a knowledge base from multiple URLs.
Visualize knowledge bases.
Install and Import Libraries#
First, let’s install the required libraries.
pip install transformers wikipedia newspaper3k GoogleNews pyvis
We need each library for the following reasons:
transformers: Load the REBEL mode.
wikipedia: Validate extracted entities by checking if they have a corresponding Wikipedia page.
newspaper: Parse articles from URLs.
GoogleNews: Read Google News latest articles about a topic.
pyvis: Graphs visualizations.
Let’s import all the necessary libraries and classes.
# needed to load the REBEL model
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import math
import torch
# wrapper for wikipedia API
import wikipedia
# scraping of web articles
from newspaper import Article, ArticleException
# google news scraping
from GoogleNews import GoogleNews
# graph visualization
from pyvis.network import Network
# show HTML in notebook
import IPython
Load the Relation Extraction Model#
Thanks to the transformers library, we can load the pre-trained REBEL model and tokenizer with a few lines of code.
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("Babelscape/rebel-large")
model = AutoModelForSeq2SeqLM.from_pretrained("Babelscape/rebel-large")
From Short Text to KB#
The next step is to write a function that is able to parse the strings generated by REBEL and transform them into relation triplets (e.g. the <Fabio, lives in, Italy> triplet). This function must take into account additional new tokens (i.e. the <triplet> , <subj>, and <obj> tokens) used while training the model. Fortunately, the REBEL model card provides us with a complete code example for this function, which we’ll use as-is.
# from https://huggingface.co/Babelscape/rebel-large
def extract_relations_from_model_output(text):
relations = []
relation, subject, relation, object_ = '', '', '', ''
text = text.strip()
current = 'x'
text_replaced = text.replace("<s>", "").replace("<pad>", "").replace("</s>", "")
for token in text_replaced.split():
if token == "<triplet>":
current = 't'
if relation != '':
relations.append({
'head': subject.strip(),
'type': relation.strip(),
'tail': object_.strip()
})
relation = ''
subject = ''
elif token == "<subj>":
current = 's'
if relation != '':
relations.append({
'head': subject.strip(),
'type': relation.strip(),
'tail': object_.strip()
})
object_ = ''
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '':
relations.append({
'head': subject.strip(),
'type': relation.strip(),
'tail': object_.strip()
})
return relations
The function outputs a list of relations, where each relation is represented as a dictionary with the following keys:
head: The subject of the relation (e.g. “Fabio”).type: The relation type (e.g. “lives in”).tail: The object of the relation (e.g. “Italy”).
Next, let’s write the code for implementing a knowledge base class. Our KB class is made of a list of relations and has several methods to deal with adding new relations to the knowledge base or printing them. It implements a very simple logic at the moment.
# knowledge base class
class KB():
def __init__(self):
self.relations = []
def are_relations_equal(self, r1, r2):
return all(r1[attr] == r2[attr] for attr in ["head", "type", "tail"])
def exists_relation(self, r1):
return any(self.are_relations_equal(r1, r2) for r2 in self.relations)
def add_relation(self, r):
if not self.exists_relation(r):
self.relations.append(r)
def print(self):
print("Relations:")
for r in self.relations:
print(f" {r}")
Last, we define a from_small_text_to_kb function that returns a KB object with relations extracted from a short text. It does the following:
Initialize an empty knowledge base KB object.
Tokenize the input text.
Use REBEL to generate relations from the text.
Parse REBEL output and store relation triplets into the knowledge base object.
Return the knowledge base object.
# build a knowledge base from text
def from_small_text_to_kb(text, verbose=False):
kb = KB()
# Tokenizer text
model_inputs = tokenizer(text, max_length=512, padding=True, truncation=True,
return_tensors='pt')
if verbose:
print(f"Num tokens: {len(model_inputs['input_ids'][0])}")
# Generate
gen_kwargs = {
"max_length": 216,
"length_penalty": 0,
"num_beams": 3,
"num_return_sequences": 3
}
generated_tokens = model.generate(
**model_inputs,
**gen_kwargs,
)
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=False)
# create kb
for sentence_pred in decoded_preds:
relations = extract_relations_from_model_output(sentence_pred)
for r in relations:
kb.add_relation(r)
return kb
Let’s try the function with some text about Napoleon Bonaparte from Wikipedia.
# test the `from_small_text_to_kb` function
text = "Napoleon Bonaparte (born Napoleone di Buonaparte; 15 August 1769 – 5 " \
"May 1821), and later known by his regnal name Napoleon I, was a French military " \
"and political leader who rose to prominence during the French Revolution and led " \
"several successful campaigns during the Revolutionary Wars. He was the de facto " \
"leader of the French Republic as First Consul from 1799 to 1804. As Napoleon I, " \
"he was Emperor of the French from 1804 until 1814 and again in 1815. Napoleon's " \
"political and cultural legacy has endured, and he has been one of the most " \
"celebrated and controversial leaders in world history."
kb = from_small_text_to_kb(text, verbose=True)
kb.print()
Num tokens: 133
Relations:
{'head': 'Napoleon Bonaparte', 'type': 'date of birth', 'tail': '15 August 1769'}
{'head': 'Napoleon Bonaparte', 'type': 'date of death', 'tail': '5 May 1821'}
{'head': 'Napoleon Bonaparte', 'type': 'participant in', 'tail': 'French Revolution'}
{'head': 'Napoleon Bonaparte', 'type': 'conflict', 'tail': 'Revolutionary Wars'}
{'head': 'Revolutionary Wars', 'type': 'part of', 'tail': 'French Revolution'}
{'head': 'French Revolution', 'type': 'participant', 'tail': 'Napoleon Bonaparte'}
{'head': 'Revolutionary Wars', 'type': 'participant', 'tail': 'Napoleon Bonaparte'}
The model is able to extract several relations, such as Napoleon’s date of birth and date of death, and his participation in the French Revolution. Nice!
From Long Text to KB#
Transformer models like REBEL have memory requirements that grow quadratically with the size of the inputs. This means that REBEL is able to work on common hardware at a reasonable speed with inputs of about 512 tokens, which correspond to about 380 English words. However, we may need to extract relations from documents long several thousands of words.
Moreover, from my experiments with the model, it seems to work better with shorter inputs. Intuitively, raw text relations are often expressed in single or contiguous sentences, therefore it may not be necessary to consider a high number of sentences at the same time to extract specific relations. Additionally, extracting a few relations is a simpler task than extracting many relations.
So, how do we put all this together?
For example, we can divide an input text long 1000 tokens into eight shorter overlapping spans long 128 tokens and extract relations from each span. While doing so, we also add some metadata to the extracted relations containing their span boundaries. With this info, we are able to see from which span of the text we extracted a specific relation which is now saved in our knowledge base.
Let’s modify the KB methods so that span boundaries are saved as well. The relation dictionary has now the keys:
head: The subject of the relation (e.g. “Fabio”).type: The relation type (e.g. “lives in”).tail: The object of the relation (e.g. “Italy”).meta: A dictionary containing meta information about the relation. This dictionary has aspanskey, whose value is the list of span boundaries (e.g. [[0, 128], [119, 247]]) where the relation has been found.
# add `merge_relations` to KB class
class KB():
...
def merge_relations(self, r1):
r2 = [r for r in self.relations
if self.are_relations_equal(r1, r)][0]
spans_to_add = [span for span in r1["meta"]["spans"]
if span not in r2["meta"]["spans"]]
r2["meta"]["spans"] += spans_to_add
def add_relation(self, r):
if not self.exists_relation(r):
self.relations.append(r)
else:
self.merge_relations(r)
Next, we write the from_text_to_kb function, which is similar to the from_small_text_to_kb function but is able to manage longer texts by splitting them into spans. All the new code is about the spanning logic and the management of the spans into the relations.
# extract relations for each span and put them together in a knowledge base
def from_text_to_kb(text, span_length=128, verbose=False):
# tokenize whole text
inputs = tokenizer([text], return_tensors="pt")
# compute span boundaries
num_tokens = len(inputs["input_ids"][0])
if verbose:
print(f"Input has {num_tokens} tokens")
num_spans = math.ceil(num_tokens / span_length)
if verbose:
print(f"Input has {num_spans} spans")
overlap = math.ceil((num_spans * span_length - num_tokens) /
max(num_spans - 1, 1))
spans_boundaries = []
start = 0
for i in range(num_spans):
spans_boundaries.append([start + span_length * i,
start + span_length * (i + 1)])
start -= overlap
if verbose:
print(f"Span boundaries are {spans_boundaries}")
# transform input with spans
tensor_ids = [inputs["input_ids"][0][boundary[0]:boundary[1]]
for boundary in spans_boundaries]
tensor_masks = [inputs["attention_mask"][0][boundary[0]:boundary[1]]
for boundary in spans_boundaries]
inputs = {
"input_ids": torch.stack(tensor_ids),
"attention_mask": torch.stack(tensor_masks)
}
# generate relations
num_return_sequences = 3
gen_kwargs = {
"max_length": 256,
"length_penalty": 0,
"num_beams": 3,
"num_return_sequences": num_return_sequences
}
generated_tokens = model.generate(
**inputs,
**gen_kwargs,
)
# decode relations
decoded_preds = tokenizer.batch_decode(generated_tokens,
skip_special_tokens=False)
# create kb
kb = KB()
i = 0
for sentence_pred in decoded_preds:
current_span_index = i // num_return_sequences
relations = extract_relations_from_model_output(sentence_pred)
for relation in relations:
relation["meta"] = {
"spans": [spans_boundaries[current_span_index]]
}
kb.add_relation(relation)
i += 1
return kb
Let’s try it with a longer text of 726 tokens about Napoleon. We are currently splitting the text into spans long 128 tokens.
text = """
Napoleon Bonaparte (born Napoleone di Buonaparte; 15 August 1769 – 5 May 1821), and later known by his regnal name Napoleon I, was a French military and political leader who rose to prominence during the French Revolution and led several successful campaigns during the Revolutionary Wars. He was the de facto leader of the French Republic as First Consul from 1799 to 1804. As Napoleon I, he was Emperor of the French from 1804 until 1814 and again in 1815. Napoleon's political and cultural legacy has endured, and he has been one of the most celebrated and controversial leaders in world history. Napoleon was born on the island of Corsica not long after its annexation by the Kingdom of France.[5] He supported the French Revolution in 1789 while serving in the French army, and tried to spread its ideals to his native Corsica. He rose rapidly in the Army after he saved the governing French Directory by firing on royalist insurgents. In 1796, he began a military campaign against the Austrians and their Italian allies, scoring decisive victories and becoming a national hero. Two years later, he led a military expedition to Egypt that served as a springboard to political power. He engineered a coup in November 1799 and became First Consul of the Republic. Differences with the British meant that the French faced the War of the Third Coalition by 1805. Napoleon shattered this coalition with victories in the Ulm Campaign, and at the Battle of Austerlitz, which led to the dissolving of the Holy Roman Empire. In 1806, the Fourth Coalition took up arms against him because Prussia became worried about growing French influence on the continent. Napoleon knocked out Prussia at the battles of Jena and Auerstedt, marched the Grande Armée into Eastern Europe, annihilating the Russians in June 1807 at Friedland, and forcing the defeated nations of the Fourth Coalition to accept the Treaties of Tilsit. Two years later, the Austrians challenged the French again during the War of the Fifth Coalition, but Napoleon solidified his grip over Europe after triumphing at the Battle of Wagram. Hoping to extend the Continental System, his embargo against Britain, Napoleon invaded the Iberian Peninsula and declared his brother Joseph King of Spain in 1808. The Spanish and the Portuguese revolted in the Peninsular War, culminating in defeat for Napoleon's marshals. Napoleon launched an invasion of Russia in the summer of 1812. The resulting campaign witnessed the catastrophic retreat of Napoleon's Grande Armée. In 1813, Prussia and Austria joined Russian forces in a Sixth Coalition against France. A chaotic military campaign resulted in a large coalition army defeating Napoleon at the Battle of Leipzig in October 1813. The coalition invaded France and captured Paris, forcing Napoleon to abdicate in April 1814. He was exiled to the island of Elba, between Corsica and Italy. In France, the Bourbons were restored to power. However, Napoleon escaped Elba in February 1815 and took control of France.[6][7] The Allies responded by forming a Seventh Coalition, which defeated Napoleon at the Battle of Waterloo in June 1815. The British exiled him to the remote island of Saint Helena in the Atlantic, where he died in 1821 at the age of 51. Napoleon had an extensive impact on the modern world, bringing liberal reforms to the many countries he conquered, especially the Low Countries, Switzerland, and parts of modern Italy and Germany. He implemented liberal policies in France and Western Europe.
"""
kb = from_text_to_kb(text, verbose=True)
kb.print()
Input has 726 tokens
Input has 6 spans
Span boundaries are [[0, 128], [119, 247], [238, 366], [357, 485], [476, 604], [595, 723]]
Relations:
{'head': 'Napoleon Bonaparte', 'type': 'date of birth',
'tail': '15 August 1769', 'meta': {'spans': [[0, 128]]}}
...
{'head': 'Napoleon', 'type': 'place of birth',
'tail': 'Corsica', 'meta': {'spans': [[119, 247]]}}
...
{'head': 'Fourth Coalition', 'type': 'start time',
'tail': '1806', 'meta': {'spans': [[238, 366]]}}
...
The text has been split into six spans, from which 23 relations have been extracted! Note that we also know from which text span each relation comes.
Filter and Normalize Entities with Wikipedia#
If you look closely at the extracted relations, you can see that there’s a relation with the entity “Napoleon Bonaparte” and a relation with the entity “Napoleon”. How can we tell our knowledge base that the two entities should be treated as the same?
One way to do this is to use the wikipedia library to check if “Napoleon Bonaparte” and “Napoleon” have the same Wikipedia page. If so, they are normalized to the title of the Wikipedia page. If an extracted entity doesn’t have a corresponding Wikipedia page, we ignore it at the moment. This step is commonly called Entity Linking.
Note that this approach relies on Wikipedia to be constantly updated by people with relevant entities. Therefore, it won’t work if you want to extract entities different from the ones already present in Wikipedia. Moreover, note that we are ignoring “date” (e.g. the 15 August 1769 in <Napoleon, date of birth, 15 August 1769>) entities for simplicity.
Let’s modify our KB code:
The
KBnow stores anentitiesdictionary with the entities of the stored relations. The keys are the entity identifiers (i.e. the title of the corresponding Wikipedia page), and the value is a dictionary containing the Wikipedia pageurland itssummary.When adding a new relation, we now check its entities with the
wikipedialibrary.
# filter and normalize entities before adding them to the KB
class KB():
def __init__(self):
self.entities = {}
self.relations = []
...
def get_wikipedia_data(self, candidate_entity):
try:
page = wikipedia.page(candidate_entity, auto_suggest=False)
entity_data = {
"title": page.title,
"url": page.url,
"summary": page.summary
}
return entity_data
except:
return None
def add_entity(self, e):
self.entities[e["title"]] = {k:v for k,v in e.items() if k != "title"}
def add_relation(self, r):
# check on wikipedia
candidate_entities = [r["head"], r["tail"]]
entities = [self.get_wikipedia_data(ent) for ent in candidate_entities]
# if one entity does not exist, stop
if any(ent is None for ent in entities):
return
# manage new entities
for e in entities:
self.add_entity(e)
# rename relation entities with their wikipedia titles
r["head"] = entities[0]["title"]
r["tail"] = entities[1]["title"]
# manage new relation
if not self.exists_relation(r):
self.relations.append(r)
else:
self.merge_relations(r)
def print(self):
print("Entities:")
for e in self.entities.items():
print(f" {e}")
print("Relations:")
for r in self.relations:
print(f" {r}")
Let’s extract relations and entities from the same text about Napoleon:
text = """
Napoleon Bonaparte (born Napoleone di Buonaparte; 15 August 1769 – 5 May 1821), and later known by his regnal name Napoleon I, was a French military and political leader who rose to prominence during the French Revolution and led several successful campaigns during the Revolutionary Wars. He was the de facto leader of the French Republic as First Consul from 1799 to 1804. As Napoleon I, he was Emperor of the French from 1804 until 1814 and again in 1815. Napoleon's political and cultural legacy has endured, and he has been one of the most celebrated and controversial leaders in world history. Napoleon was born on the island of Corsica not long after its annexation by the Kingdom of France.[5] He supported the French Revolution in 1789 while serving in the French army, and tried to spread its ideals to his native Corsica. He rose rapidly in the Army after he saved the governing French Directory by firing on royalist insurgents. In 1796, he began a military campaign against the Austrians and their Italian allies, scoring decisive victories and becoming a national hero. Two years later, he led a military expedition to Egypt that served as a springboard to political power. He engineered a coup in November 1799 and became First Consul of the Republic. Differences with the British meant that the French faced the War of the Third Coalition by 1805. Napoleon shattered this coalition with victories in the Ulm Campaign, and at the Battle of Austerlitz, which led to the dissolving of the Holy Roman Empire. In 1806, the Fourth Coalition took up arms against him because Prussia became worried about growing French influence on the continent. Napoleon knocked out Prussia at the battles of Jena and Auerstedt, marched the Grande Armée into Eastern Europe, annihilating the Russians in June 1807 at Friedland, and forcing the defeated nations of the Fourth Coalition to accept the Treaties of Tilsit. Two years later, the Austrians challenged the French again during the War of the Fifth Coalition, but Napoleon solidified his grip over Europe after triumphing at the Battle of Wagram. Hoping to extend the Continental System, his embargo against Britain, Napoleon invaded the Iberian Peninsula and declared his brother Joseph King of Spain in 1808. The Spanish and the Portuguese revolted in the Peninsular War, culminating in defeat for Napoleon's marshals. Napoleon launched an invasion of Russia in the summer of 1812. The resulting campaign witnessed the catastrophic retreat of Napoleon's Grande Armée. In 1813, Prussia and Austria joined Russian forces in a Sixth Coalition against France. A chaotic military campaign resulted in a large coalition army defeating Napoleon at the Battle of Leipzig in October 1813. The coalition invaded France and captured Paris, forcing Napoleon to abdicate in April 1814. He was exiled to the island of Elba, between Corsica and Italy. In France, the Bourbons were restored to power. However, Napoleon escaped Elba in February 1815 and took control of France.[6][7] The Allies responded by forming a Seventh Coalition, which defeated Napoleon at the Battle of Waterloo in June 1815. The British exiled him to the remote island of Saint Helena in the Atlantic, where he died in 1821 at the age of 51. Napoleon had an extensive impact on the modern world, bringing liberal reforms to the many countries he conquered, especially the Low Countries, Switzerland, and parts of modern Italy and Germany. He implemented liberal policies in France and Western Europe.
"""
kb = from_text_to_kb(text)
kb.print()
Entities:
('Napoleon', {'url': 'https://en.wikipedia.org/wiki/Napoleon',
'summary': "Napoleon Bonaparte (born Napoleone di Buonaparte; 15 August ..."})
('French Revolution', {'url': 'https://en.wikipedia.org/wiki/French_Revolution',
'summary': 'The French Revolution (French: Révolution française..."})
...
Relations:
{'head': 'Napoleon', 'type': 'participant in', 'tail': 'French Revolution',
'meta': {'spans': [[0, 128], [119, 247]]}}
{'head': 'French Revolution', 'type': 'participant', 'tail': 'Napoleon',
'meta': {'spans': [[0, 128]]}}
...
All the extracted entities are linked to Wikipedia pages and normalized with their titles. “Napoleon Bonaparte” and “Napoleon” are now both referred to with “Napoleon”!
Extract KB from Web Article#
Let’s go another step further. We want our knowledge base to manage the addition of relations and entities from articles from around the web, and to keep track of where each relation comes from.
To do this, we need to modify our KB class so that:
Along with
relationsandentities,sources(i.e. articles from around the web) are stored as well. Each article has its URL as key and a dictionary with keysarticle_titleandarticle_publish_dateas value. We’ll see later how to extract these two features.When we add a new relation to our knowledge base, the relation
metafield is now a dictionary with article URLs as keys, and another dictionary containing thespansas value. In this way, the knowledge base keeps track of all the articles from which a specific relation has been extracted. This information can be an indicator of the quality of an extracted relation.
# keep track of where relations have been extracted
class KB():
def __init__(self):
self.entities = {} # { entity_title: {...} }
self.relations = [] # [ head: entity_title, type: ..., tail: entity_title,
# meta: { article_url: { spans: [...] } } ]
self.sources = {} # { article_url: {...} }
...
def merge_relations(self, r2):
r1 = [r for r in self.relations
if self.are_relations_equal(r2, r)][0]
# if different article
article_url = list(r2["meta"].keys())[0]
if article_url not in r1["meta"]:
r1["meta"][article_url] = r2["meta"][article_url]
# if existing article
else:
spans_to_add = [span for span in r2["meta"][article_url]["spans"]
if span not in r1["meta"][article_url]["spans"]]
r1["meta"][article_url]["spans"] += spans_to_add
...
def add_relation(self, r, article_title, article_publish_date):
# check on wikipedia
candidate_entities = [r["head"], r["tail"]]
entities = [self.get_wikipedia_data(ent) for ent in candidate_entities]
# if one entity does not exist, stop
if any(ent is None for ent in entities):
return
# manage new entities
for e in entities:
self.add_entity(e)
# rename relation entities with their wikipedia titles
r["head"] = entities[0]["title"]
r["tail"] = entities[1]["title"]
# add source if not in kb
article_url = list(r["meta"].keys())[0]
if article_url not in self.sources:
self.sources[article_url] = {
"article_title": article_title,
"article_publish_date": article_publish_date
}
# manage new relation
if not self.exists_relation(r):
self.relations.append(r)
else:
self.merge_relations(r)
def print(self):
print("Entities:")
for e in self.entities.items():
print(f" {e}")
print("Relations:")
for r in self.relations:
print(f" {r}")
print("Sources:")
for s in self.sources.items():
print(f" {s}")
Next, we modify the from_text_to_kb function so that it prepares the relation meta field taking into account article URLs as well.
# extract text from url, extract relations and populate the KB
def from_text_to_kb(text, article_url, span_length=128, article_title=None,
article_publish_date=None, verbose=False):
...
# create kb
kb = KB()
i = 0
for sentence_pred in decoded_preds:
current_span_index = i // num_return_sequences
relations = extract_relations_from_model_output(sentence_pred)
for relation in relations:
relation["meta"] = {
article_url: {
"spans": [spans_boundaries[current_span_index]]
}
}
kb.add_relation(relation, article_title, article_publish_date)
i += 1
return kb
Last, we use the newspaper library to download and parse articles from URLs and define a from_url_to_kb function. The library automatically extracts the article text, title, and publish date (if present).
# parse an article with newspaper3k
def get_article(url):
article = Article(url)
article.download()
article.parse()
return article
# extract the article from the url (along with metadata), extract relations and populate a KB
def from_url_to_kb(url):
article = get_article(url)
config = {
"article_title": article.title,
"article_publish_date": article.publish_date
}
kb = from_text_to_kb(article.text, article.url, **config)
return kb
Let’s try to extract a knowledge base from the article Microstrategy chief: ‘Bitcoin is going to go into the millions’.
# test the `from_url_to_kb` function
url = "https://finance.yahoo.com/news/microstrategy-bitcoin-millions-142143795.html"
kb = from_url_to_kb(url)
kb.print()
Entities:
('MicroStrategy', {'url': 'https://en.wikipedia.org/wiki/MicroStrategy',
'summary': "MicroStrategy Incorporated is an American company that ..."})
('Michael J. Saylor', {'url': 'https://en.wikipedia.org/wiki/Michael_J._Saylor',
'summary': 'Michael J. Saylor (born February 4, 1965) is an American ..."})
...
Relations:
{'head': 'MicroStrategy', 'type': 'founded by', 'tail': 'Michael J. Saylor',
'meta': {'https://finance.yahoo.com/news/microstrategy-bitcoin-millions-142143795.html':
{'spans': [[0, 128]]}}}
{'head': 'Michael J. Saylor', 'type': 'employer', 'tail': 'MicroStrategy',
'meta': {'https://finance.yahoo.com/news/microstrategy-bitcoin-millions-142143795.html':
{'spans': [[0, 128]]}}}
...
Sources:
('https://finance.yahoo.com/news/microstrategy-bitcoin-millions-142143795.html',
{'article_title': "Microstrategy chief: 'Bitcoin is going to go into the millions'",
'article_publish_date': None})
The KB is showing a lot of information!
From the
entitieslist, we see that Microstrategy is an American company.From the
relationslist, we see that Michael J. Saylor is a founder of the Microstrategy company, and where we extracted such relation (i.e. the article URL and the text span).From the
sourceslist, we see the title and publish date of the aforementioned article.
Google News: Extract KB from Multiple Articles#
We are almost done! Consider this last scenario: creating a knowledge base from multiple articles. We can deal with it by extracting a separate knowledge base from each article and then merging all the knowledge bases together. Let’s add a merge_with_kb method to our KB class.
class KB():
...
def merge_with_kb(self, kb2):
for r in kb2.relations:
article_url = list(r["meta"].keys())[0]
source_data = kb2.sources[article_url]
self.add_relation(r, source_data["article_title"],
source_data["article_publish_date"])
...
Then, we use the GoogleNews library to get the URLs of recent news articles about a specific topic. Once we have multiple URLs, we feed them to the from_urls_to_kb function, which extracts a knowledge base from each article and then merges them together.
# get news links from google news
def get_news_links(query, lang="en", region="US", pages=1, max_links=100000):
googlenews = GoogleNews(lang=lang, region=region)
googlenews.search(query)
all_urls = []
for page in range(pages):
googlenews.get_page(page)
all_urls += googlenews.get_links()
return list(set(all_urls))[:max_links]
# build a KB from multiple news links
def from_urls_to_kb(urls, verbose=False):
kb = KB()
if verbose:
print(f"{len(urls)} links to visit")
for url in urls:
if verbose:
print(f"Visiting {url}...")
try:
kb_url = from_url_to_kb(url)
kb.merge_with_kb(kb_url)
except ArticleException:
if verbose:
print(f" Couldn't download article at url {url}")
return kb
Let’s try extracting a knowledge base from three articles from Google News about “Google”.
# test the `from_urls_to_kb` function
news_links = get_news_links("Google", pages=1, max_links=3)
kb = from_urls_to_kb(news_links, verbose=True)
kb.print()
3 links to visit
Visiting https://www.hindustantimes.com/india-news/google-doodle-celebrates-india-s-gama-pehlwan-the-undefeated-wrestling-champion-101653180853982.html...
Visiting https://tech.hindustantimes.com/tech/news/google-doodle-today-celebrates-gama-pehlwan-s-144th-birth-anniversary-know-who-he-is-71653191916538.html...
Visiting https://www.moneycontrol.com/news/trends/current-affairs-trends/google-doodle-celebrates-gama-pehlwan-the-amritsar-born-wrestling-champ-who-inspired-bruce-lee-8552171.html...
Entities:
('Google', {'url': 'https://en.wikipedia.org/wiki/Google',
'summary': 'Google LLC is an American ...'})
...
Relations:
{'head': 'Google', 'type': 'owner of', 'tail': 'Google Doodle',
'meta': {'https://tech.hindustantimes.com/tech/news/google-doodle-today-celebrates-gama-pehlwan-s-144th-birth-anniversary-know-who-he-is-71653191916538.html':
{'spans': [[0, 128]]}}}
...
Sources:
('https://www.hindustantimes.com/india-news/google-doodle-celebrates-india-s-gama-pehlwan-the-undefeated-wrestling-champion-101653180853982.html',
{'article_title': "Google Doodle celebrates India's Gama Pehlwan, the undefeated wrestling champion",
'article_publish_date': datetime.datetime(2022, 5, 22, 6, 59, 56, tzinfo=tzoffset(None, 19800))})
('https://tech.hindustantimes.com/tech/news/google-doodle-today-celebrates-gama-pehlwan-s-144th-birth-anniversary-know-who-he-is-71653191916538.html',
{'article_title': "Google Doodle today celebrates Gama Pehlwan's 144th birth anniversary; know who he is",
'article_publish_date': datetime.datetime(2022, 5, 22, 9, 32, 38, tzinfo=tzoffset(None, 19800))})
('https://www.moneycontrol.com/news/trends/current-affairs-trends/google-doodle-celebrates-gama-pehlwan-the-amritsar-born-wrestling-champ-who-inspired-bruce-lee-8552171.html',
{'article_title': 'Google Doodle celebrates Gama Pehlwan, the Amritsar-born wrestling champ who inspired Bruce Lee',
'article_publish_date': None})
The knowledge bases are getting bigger! We got 10 entities, 10 relations, and 3 sources. Note that we know from which article each relation comes.
Visualize KB#
Congratulations if you’ve read this far, we’re done with the scenarios! Let’s visualize the output of our work by plotting the knowledge bases. As our knowledge bases are graphs, we can use the pyvis library, which allows the creation of interactive network visualizations.
We define a save_network_html function that:
Initialize an empty directed
pyvisnetwork.Add the knowledge base entities as nodes.
Add the knowledge base relations as edges.
Save the network in an HTML file.
# from KB to HTML visualization
def save_network_html(kb, filename="network.html"):
# create network
net = Network(directed=True, width="auto", height="700px", bgcolor="#eeeeee")
# nodes
color_entity = "#00FF00"
for e in kb.entities:
net.add_node(e, shape="circle", color=color_entity)
# edges
for r in kb.relations:
net.add_edge(r["head"], r["tail"],
title=r["type"], label=r["type"])
# save network
net.repulsion(
node_distance=200,
central_gravity=0.2,
spring_length=200,
spring_strength=0.05,
damping=0.09
)
net.set_edge_smooth('dynamic')
net.show(filename)
Let’s try the save_network_html function with a knowledge base built from 20 news articles about “Google”.
# extract KB from news about Google and visualize it
news_links = get_news_links("Google", pages=5, max_links=20)
kb = from_urls_to_kb(news_links, verbose=True)
filename = "network_3_google.html"
save_network_html(kb, filename=filename)
Remember that, even though they are not visualized, the knowledge graph saves information about the provenience of each relation (e.g. from which articles it has been extracted and other metadata), along with Wikipedia data about each entity. Visualizing knowledge graphs is useful for debugging purposes, but their main benefits come when used for inference.
This is the resulting graph:
Code Exercises#
Quiz#
To build a knowledge graph from text, we typically need to perform two steps:
Extract entities and extract relations between these entities.
Identify topics and classify them into categories.
Tokenize the text and perform lemmatization.
Generate a list of keywords and map them to relevant concepts.
Answer
The correct answer is 1.
True or False. Relation Extraction involves doing both Named Entity Recognition and Relation Classification in an end-to-end approach.
Answer
The correct answer is True.
What data has the REBEL relation extraction model been trained on?
Unstructured text from webpages and books.
A corpus of tagged dialogue transcripts.
Entities and relations found in Wikipedia abstracts and Wikidata.
Answer
The correct answer is 3.
What’s the job of the Entity Linking task?
To link entities in a text with an existing knowledge base.
To classify entities in a text.
To assign a probability to each candidate entity.
Answer
The correct answer is 1.
What’s the name of a Python library for plotting graphs?
seabornmatplotlibpyvisggplot
Answer
The correct answer is 3.
Questions and Feedbacks#
Have questions about this lesson? Would you like to exchange ideas? Or would you like to point out something that needs to be corrected? Join the NLPlanet Discord server and interact with the community! There’s a specific channel for this course called practical-nlp-nlplanet.